 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCure the headache of Transformers via Collinear Constrained Attention
Sep 15, 2023



As the rapid progression of practical applications based on Large Language Models continues, the importance of extrapolating performance has grown exponentially in the research domain. In our study, we identified an anomalous behavior in Transformer models that had been previously overlooked, leading to a chaos around closest tokens which carried the most important information. We've coined this discovery the "headache of Transformers". To address this at its core, we introduced a novel self-attention structure named Collinear Constrained Attention (CoCA). This structure can be seamlessly integrated with existing extrapolation, interpolation methods, and other optimization strategies designed for traditional Transformer models. We have achieved excellent extrapolating performance even for 16 times to 24 times of sequence lengths during inference without any fine-tuning on our model. We have also enhanced CoCA's computational and spatial efficiency to ensure its practicality. We plan to open-source CoCA shortly. In the meantime, we've made our code available in the appendix for reappearing experiments.
Continual Learning in Predictive Autoscaling
Aug 14, 2023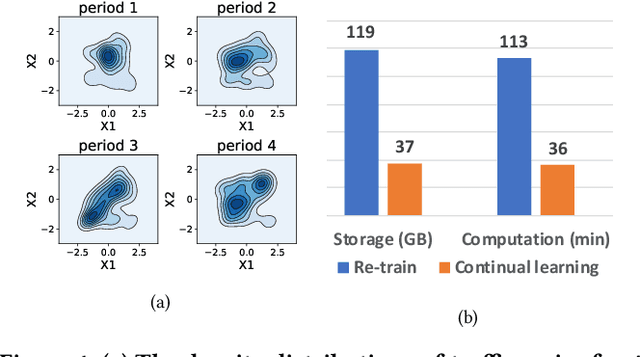
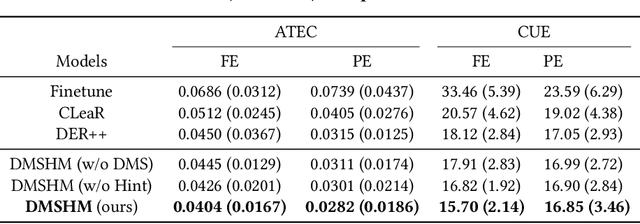
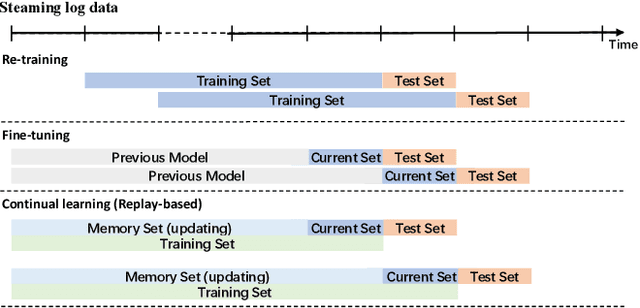
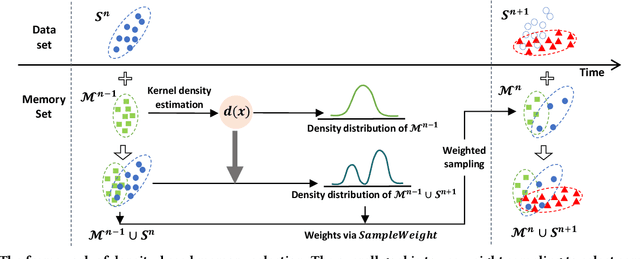
Predictive Autoscaling is used to forecast the workloads of servers and prepare the resources in advance to ensure service level objectives (SLOs) in dynamic cloud environments. However, in practice, its prediction task often suffers from performance degradation under abnormal traffics caused by external events (such as sales promotional activities and applications re-configurations), for which a common solution is to re-train the model with data of a long historical period, but at the expense of high computational and storage costs. To better address this problem, we propose a replay-based continual learning method, i.e., Density-based Memory Selection and Hint-based Network Learning Model (DMSHM), using only a small part of the historical log to achieve accurate predictions. First, we discover the phenomenon of sample overlap when applying replay-based continual learning in prediction tasks. In order to surmount this challenge and effectively integrate new sample distribution, we propose a density-based sample selection strategy that utilizes kernel density estimation to calculate sample density as a reference to compute sample weight, and employs weight sampling to construct a new memory set. Then we implement hint-based network learning based on hint representation to optimize the parameters. Finally, we conduct experiments on public and industrial datasets to demonstrate that our proposed method outperforms state-of-the-art continual learning methods in terms of memory capacity and prediction accuracy. Furthermore, we demonstrate remarkable practicability of DMSHM in real industrial applications.
Full Scaling Automation for Sustainable Development of Green Data Centers
May 01, 2023



The rapid rise in cloud computing has resulted in an alarming increase in data centers' carbon emissions, which now accounts for >3% of global greenhouse gas emissions, necessitating immediate steps to combat their mounting strain on the global climate. An important focus of this effort is to improve resource utilization in order to save electricity usage. Our proposed Full Scaling Automation (FSA) mechanism is an effective method of dynamically adapting resources to accommodate changing workloads in large-scale cloud computing clusters, enabling the clusters in data centers to maintain their desired CPU utilization target and thus improve energy efficiency. FSA harnesses the power of deep representation learning to accurately predict the future workload of each service and automatically stabilize the corresponding target CPU usage level, unlike the previous autoscaling methods, such as Autopilot or FIRM, that need to adjust computing resources with statistical models and expert knowledge. Our approach achieves significant performance improvement compared to the existing work in real-world datasets. We also deployed FSA on large-scale cloud computing clusters in industrial data centers, and according to the certification of the China Environmental United Certification Center (CEC), a reduction of 947 tons of carbon dioxide, equivalent to a saving of 1538,000 kWh of electricity, was achieved during the Double 11 shopping festival of 2022, marking a critical step for our company's strategic goal towards carbon neutrality by 2030.
A Meta Reinforcement Learning Approach for Predictive Autoscaling in the Cloud
May 31, 2022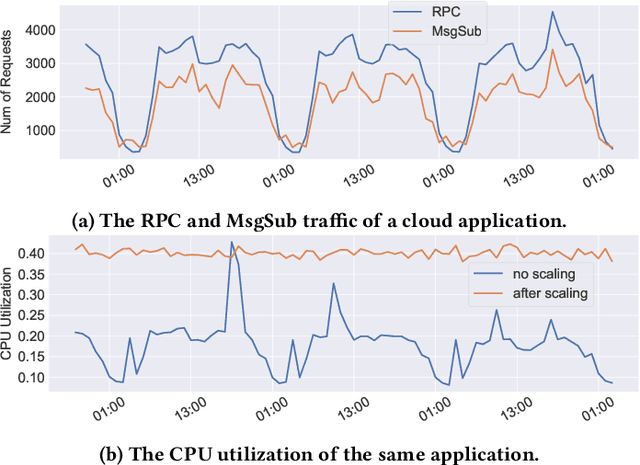

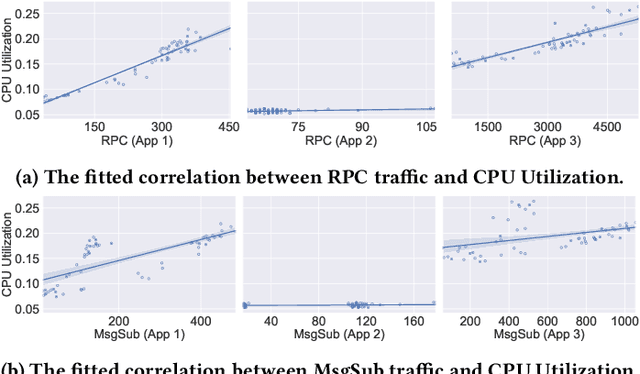

Predictive autoscaling (autoscaling with workload forecasting) is an important mechanism that supports autonomous adjustment of computing resources in accordance with fluctuating workload demands in the Cloud. In recent works, Reinforcement Learning (RL) has been introduced as a promising approach to learn the resource management policies to guide the scaling actions under the dynamic and uncertain cloud environment. However, RL methods face the following challenges in steering predictive autoscaling, such as lack of accuracy in decision-making, inefficient sampling and significant variability in workload patterns that may cause policies to fail at test time. To this end, we propose an end-to-end predictive meta model-based RL algorithm, aiming to optimally allocate resource to maintain a stable CPU utilization level, which incorporates a specially-designed deep periodic workload prediction model as the input and embeds the Neural Process to guide the learning of the optimal scaling actions over numerous application services in the Cloud. Our algorithm not only ensures the predictability and accuracy of the scaling strategy, but also enables the scaling decisions to adapt to the changing workloads with high sample efficiency. Our method has achieved significant performance improvement compared to the existing algorithms and has been deployed online at Alipay, supporting the autoscaling of applications for the world-leading payment platform.