 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning in Predictive Autoscaling
Paper and Code
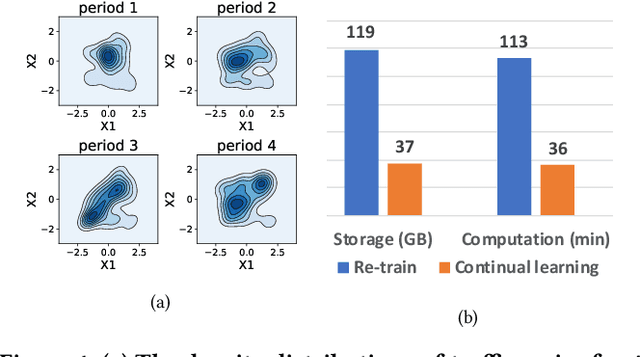
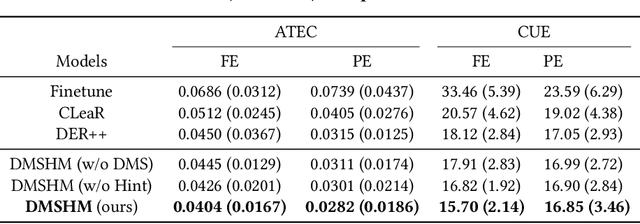
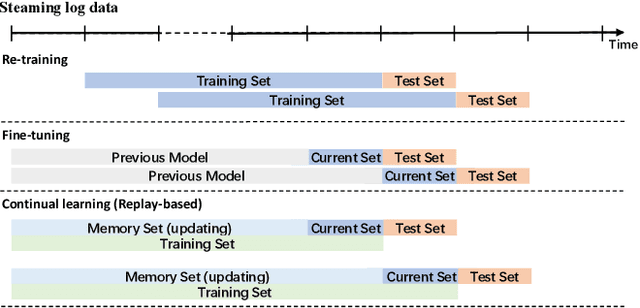
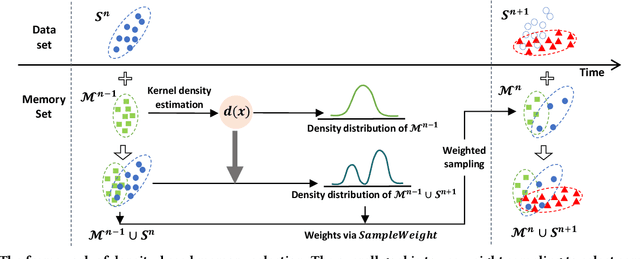
Predictive Autoscaling is used to forecast the workloads of servers and prepare the resources in advance to ensure service level objectives (SLOs) in dynamic cloud environments. However, in practice, its prediction task often suffers from performance degradation under abnormal traffics caused by external events (such as sales promotional activities and applications re-configurations), for which a common solution is to re-train the model with data of a long historical period, but at the expense of high computational and storage costs. To better address this problem, we propose a replay-based continual learning method, i.e., Density-based Memory Selection and Hint-based Network Learning Model (DMSHM), using only a small part of the historical log to achieve accurate predictions. First, we discover the phenomenon of sample overlap when applying replay-based continual learning in prediction tasks. In order to surmount this challenge and effectively integrate new sample distribution, we propose a density-based sample selection strategy that utilizes kernel density estimation to calculate sample density as a reference to compute sample weight, and employs weight sampling to construct a new memory set. Then we implement hint-based network learning based on hint representation to optimize the parameters. Finally, we conduct experiments on public and industrial datasets to demonstrate that our proposed method outperforms state-of-the-art continual learning methods in terms of memory capacity and prediction accuracy. Furthermore, we demonstrate remarkable practicability of DMSHM in real industrial applications.