 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMP-AR: Granularity Message Passing and Adaptive Reconciliation for Temporal Hierarchy Forecasting
Jun 18, 2024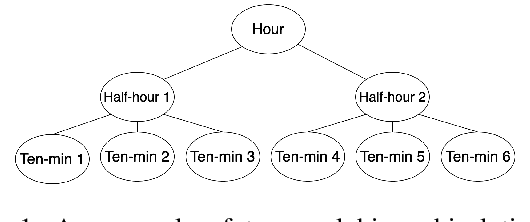
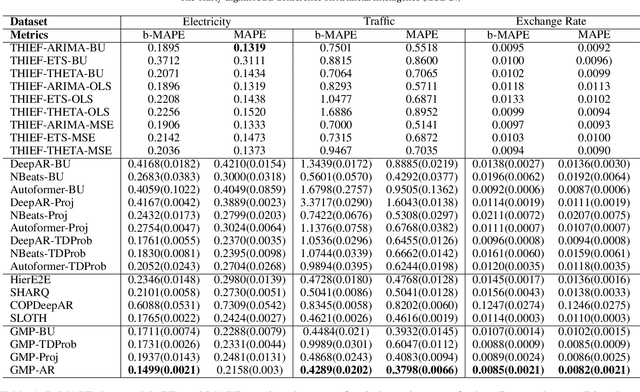
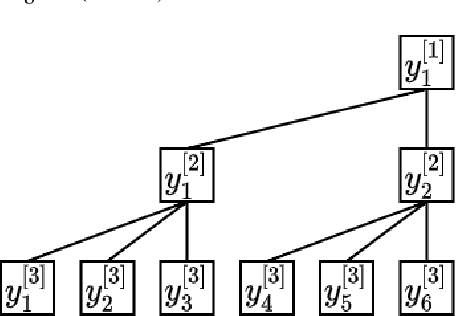
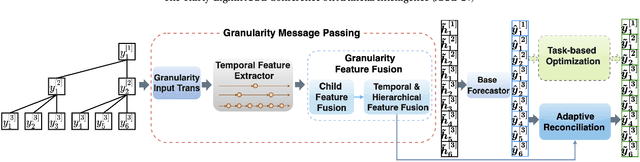
Time series forecasts of different temporal granularity are widely used in real-world applications, e.g., sales prediction in days and weeks for making different inventory plans. However, these tasks are usually solved separately without ensuring coherence, which is crucial for aligning downstream decisions. Previous works mainly focus on ensuring coherence with some straightforward methods, e.g., aggregation from the forecasts of fine granularity to the coarse ones, and allocation from the coarse granularity to the fine ones. These methods merely take the temporal hierarchical structure to maintain coherence without improving the forecasting accuracy. In this paper, we propose a novel granularity message-passing mechanism (GMP) that leverages temporal hierarchy information to improve forecasting performance and also utilizes an adaptive reconciliation (AR) strategy to maintain coherence without performance loss. Furthermore, we introduce an optimization module to achieve task-based targets while adhering to more real-world constraints. Experiments on real-world datasets demonstrate that our framework (GMP-AR) achieves superior performances on temporal hierarchical forecasting tasks compared to state-of-the-art methods. In addition, our framework has been successfully applied to a real-world task of payment traffic management in Alipay by integrating with the task-based optimization module.
Large Models for Time Series and Spatio-Temporal Data: A Survey and Outlook
Oct 20, 2023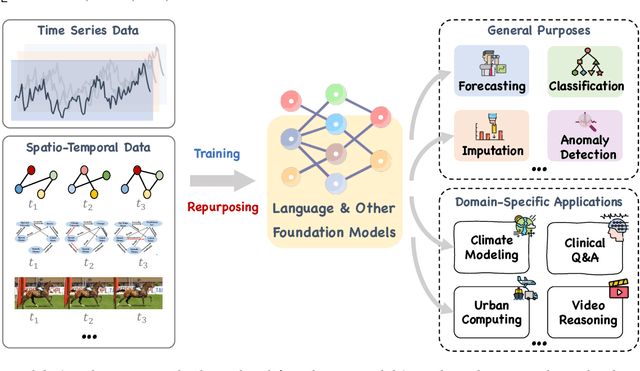
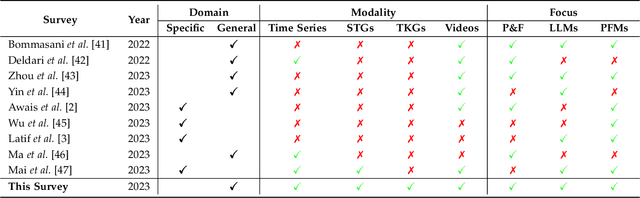
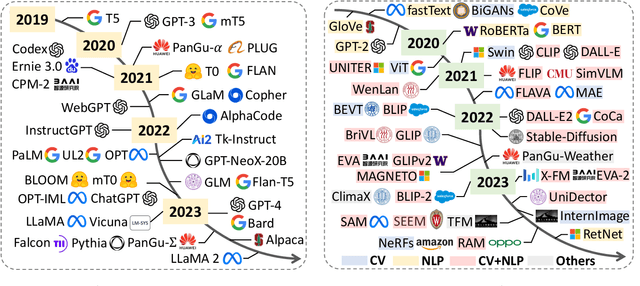
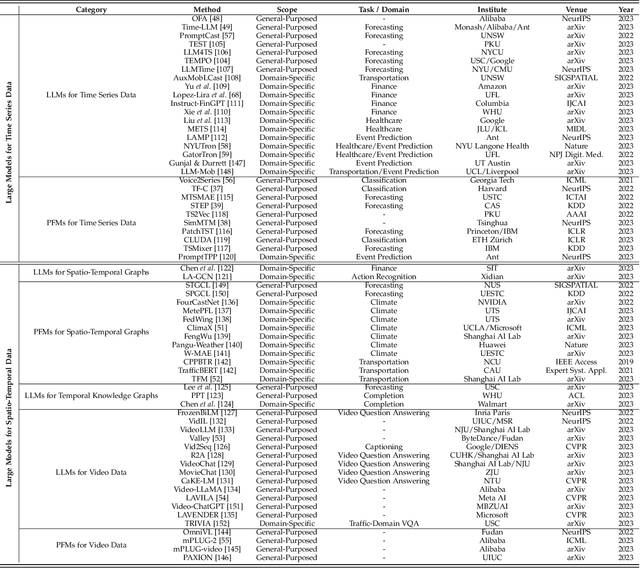
Temporal data, notably time series and spatio-temporal data, are prevalent in real-world applications. They capture dynamic system measurements and are produced in vast quantities by both physical and virtual sensors. Analyzing these data types is vital to harnessing the rich information they encompass and thus benefits a wide range of downstream tasks. Recent advances in large language and other foundational models have spurred increased use of these models in time series and spatio-temporal data mining. Such methodologies not only enable enhanced pattern recognition and reasoning across diverse domains but also lay the groundwork for artificial general intelligence capable of comprehending and processing common temporal data. In this survey, we offer a comprehensive and up-to-date review of large models tailored (or adapted) for time series and spatio-temporal data, spanning four key facets: data types, model categories, model scopes, and application areas/tasks. Our objective is to equip practitioners with the knowledge to develop applications and further research in this underexplored domain. We primarily categorize the existing literature into two major clusters: large models for time series analysis (LM4TS) and spatio-temporal data mining (LM4STD). On this basis, we further classify research based on model scopes (i.e., general vs. domain-specific) and application areas/tasks. We also provide a comprehensive collection of pertinent resources, including datasets, model assets, and useful tools, categorized by mainstream applications. This survey coalesces the latest strides in large model-centric research on time series and spatio-temporal data, underscoring the solid foundations, current advances, practical applications, abundant resources, and future research opportunities.
Deep Optimal Timing Strategies for Time Series
Oct 09, 2023



Deciding the best future execution time is a critical task in many business activities while evolving time series forecasting, and optimal timing strategy provides such a solution, which is driven by observed data. This solution has plenty of valuable applications to reduce the operation costs. In this paper, we propose a mechanism that combines a probabilistic time series forecasting task and an optimal timing decision task as a first systematic attempt to tackle these practical problems with both solid theoretical foundation and real-world flexibility. Specifically, it generates the future paths of the underlying time series via probabilistic forecasting algorithms, which does not need a sophisticated mathematical dynamic model relying on strong prior knowledge as most other common practices. In order to find the optimal execution time, we formulate the decision task as an optimal stopping problem, and employ a recurrent neural network structure (RNN) to approximate the optimal times. Github repository: \url{github.com/ChenPopper/optimal_timing_TSF}.
Continuous Invariance Learning
Oct 09, 2023



Invariance learning methods aim to learn invariant features in the hope that they generalize under distributional shifts. Although many tasks are naturally characterized by continuous domains, current invariance learning techniques generally assume categorically indexed domains. For example, auto-scaling in cloud computing often needs a CPU utilization prediction model that generalizes across different times (e.g., time of a day and date of a year), where `time' is a continuous domain index. In this paper, we start by theoretically showing that existing invariance learning methods can fail for continuous domain problems. Specifically, the naive solution of splitting continuous domains into discrete ones ignores the underlying relationship among domains, and therefore potentially leads to suboptimal performance. To address this challenge, we then propose Continuous Invariance Learning (CIL), which extracts invariant features across continuously indexed domains. CIL is a novel adversarial procedure that measures and controls the conditional independence between the labels and continuous domain indices given the extracted features. Our theoretical analysis demonstrates the superiority of CIL over existing invariance learning methods. Empirical results on both synthetic and real-world datasets (including data collected from production systems) show that CIL consistently outperforms strong baselines among all the tasks.
WeaverBird: Empowering Financial Decision-Making with Large Language Model, Knowledge Base, and Search Engine
Aug 30, 2023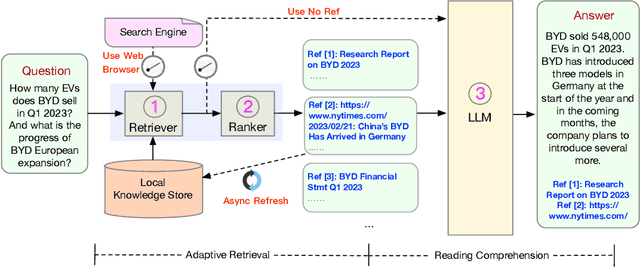
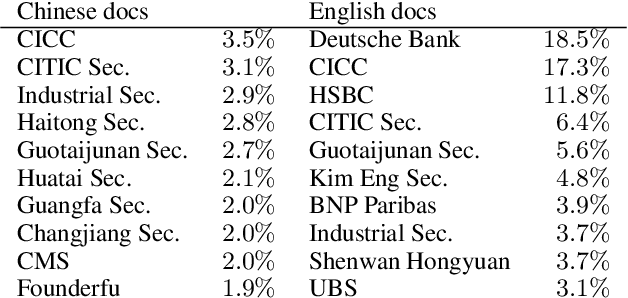
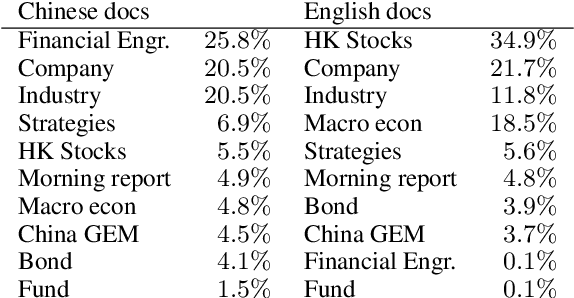
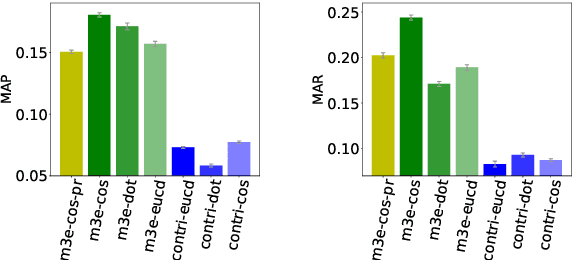
We present WeaverBird, an intelligent dialogue system designed specifically for the finance domain. Our system harnesses a large language model of GPT architecture that has been tuned using extensive corpora of finance-related text. As a result, our system possesses the capability to understand complex financial queries, such as "How should I manage my investments during inflation?", and provide informed responses. Furthermore, our system incorporates a local knowledge base and a search engine to retrieve relevant information. The final responses are conditioned on the search results and include proper citations to the sources, thus enjoying an enhanced credibility. Through a range of finance-related questions, we have demonstrated the superior performance of our system compared to other models. To experience our system firsthand, users can interact with our live demo at https://weaverbird.ttic.edu, as well as watch our 2-min video illustration at https://www.youtube.com/watch?v=fyV2qQkX6Tc.
Continual Learning in Predictive Autoscaling
Aug 14, 2023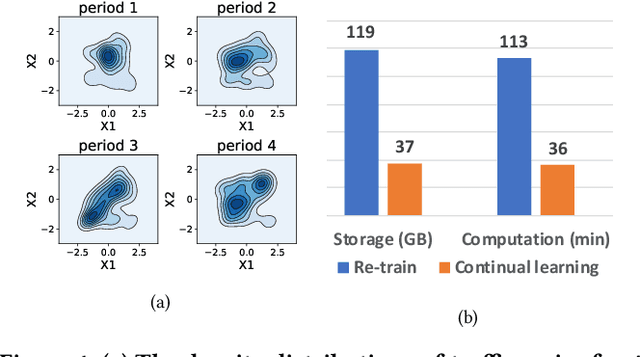
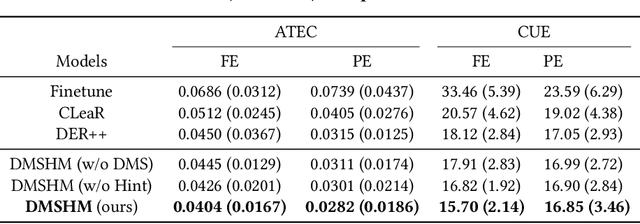
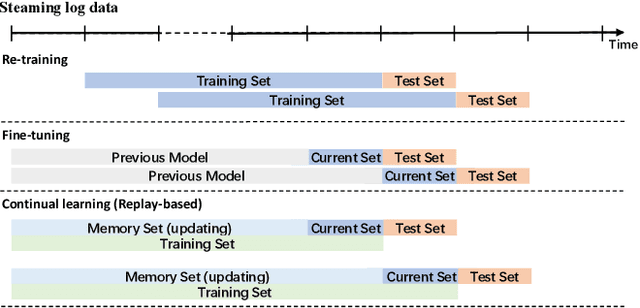
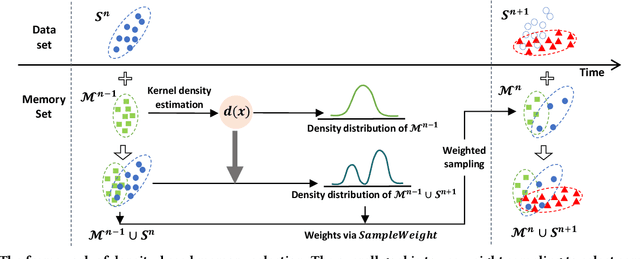
Predictive Autoscaling is used to forecast the workloads of servers and prepare the resources in advance to ensure service level objectives (SLOs) in dynamic cloud environments. However, in practice, its prediction task often suffers from performance degradation under abnormal traffics caused by external events (such as sales promotional activities and applications re-configurations), for which a common solution is to re-train the model with data of a long historical period, but at the expense of high computational and storage costs. To better address this problem, we propose a replay-based continual learning method, i.e., Density-based Memory Selection and Hint-based Network Learning Model (DMSHM), using only a small part of the historical log to achieve accurate predictions. First, we discover the phenomenon of sample overlap when applying replay-based continual learning in prediction tasks. In order to surmount this challenge and effectively integrate new sample distribution, we propose a density-based sample selection strategy that utilizes kernel density estimation to calculate sample density as a reference to compute sample weight, and employs weight sampling to construct a new memory set. Then we implement hint-based network learning based on hint representation to optimize the parameters. Finally, we conduct experiments on public and industrial datasets to demonstrate that our proposed method outperforms state-of-the-art continual learning methods in terms of memory capacity and prediction accuracy. Furthermore, we demonstrate remarkable practicability of DMSHM in real industrial applications.
Automatic Deduction Path Learning via Reinforcement Learning with Environmental Correction
Jun 16, 2023

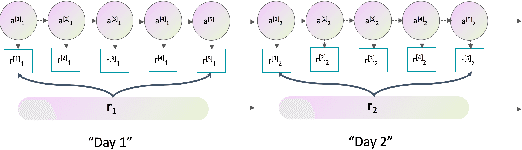

Automatic bill payment is an important part of business operations in fintech companies. The practice of deduction was mainly based on the total amount or heuristic search by dividing the bill into smaller parts to deduct as much as possible. This article proposes an end-to-end approach of automatically learning the optimal deduction paths (deduction amount in order), which reduces the cost of manual path design and maximizes the amount of successful deduction. Specifically, in view of the large search space of the paths and the extreme sparsity of historical successful deduction records, we propose a deep hierarchical reinforcement learning approach which abstracts the action into a two-level hierarchical space: an upper agent that determines the number of steps of deductions each day and a lower agent that decides the amount of deduction at each step. In such a way, the action space is structured via prior knowledge and the exploration space is reduced. Moreover, the inherited information incompleteness of the business makes the environment just partially observable. To be precise, the deducted amounts indicate merely the lower bounds of the available account balance. To this end, we formulate the problem as a partially observable Markov decision problem (POMDP) and employ an environment correction algorithm based on the characteristics of the business. In the world's largest electronic payment business, we have verified the effectiveness of this scheme offline and deployed it online to serve millions of users.
Self-Supervised Learning for Time Series Analysis: Taxonomy, Progress, and Prospects
Jun 16, 2023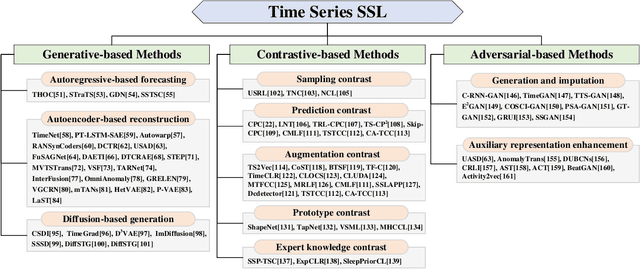
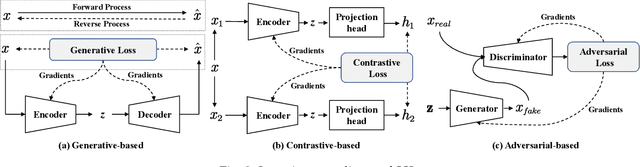
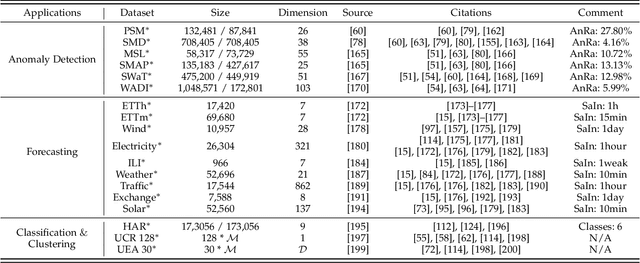
Self-supervised learning (SSL) has recently achieved impressive performance on various time series tasks. The most prominent advantage of SSL is that it reduces the dependence on labeled data. Based on the pre-training and fine-tuning strategy, even a small amount of labeled data can achieve high performance. Compared with many published self-supervised surveys on computer vision and natural language processing, a comprehensive survey for time series SSL is still missing. To fill this gap, we review current state-of-the-art SSL methods for time series data in this article. To this end, we first comprehensively review existing surveys related to SSL and time series, and then provide a new taxonomy of existing time series SSL methods. We summarize these methods into three categories: generative-based, contrastive-based, and adversarial-based. All methods can be further divided into ten subcategories. To facilitate the experiments and validation of time series SSL methods, we also summarize datasets commonly used in time series forecasting, classification, anomaly detection, and clustering tasks. Finally, we present the future directions of SSL for time series analysis.
Full Scaling Automation for Sustainable Development of Green Data Centers
May 01, 2023



The rapid rise in cloud computing has resulted in an alarming increase in data centers' carbon emissions, which now accounts for >3% of global greenhouse gas emissions, necessitating immediate steps to combat their mounting strain on the global climate. An important focus of this effort is to improve resource utilization in order to save electricity usage. Our proposed Full Scaling Automation (FSA) mechanism is an effective method of dynamically adapting resources to accommodate changing workloads in large-scale cloud computing clusters, enabling the clusters in data centers to maintain their desired CPU utilization target and thus improve energy efficiency. FSA harnesses the power of deep representation learning to accurately predict the future workload of each service and automatically stabilize the corresponding target CPU usage level, unlike the previous autoscaling methods, such as Autopilot or FIRM, that need to adjust computing resources with statistical models and expert knowledge. Our approach achieves significant performance improvement compared to the existing work in real-world datasets. We also deployed FSA on large-scale cloud computing clusters in industrial data centers, and according to the certification of the China Environmental United Certification Center (CEC), a reduction of 947 tons of carbon dioxide, equivalent to a saving of 1538,000 kWh of electricity, was achieved during the Double 11 shopping festival of 2022, marking a critical step for our company's strategic goal towards carbon neutrality by 2030.
SLOTH: Structured Learning and Task-based Optimization for Time Series Forecasting on Hierarchies
Feb 27, 2023
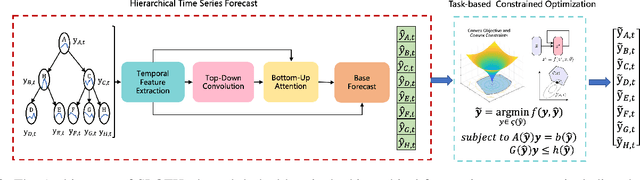
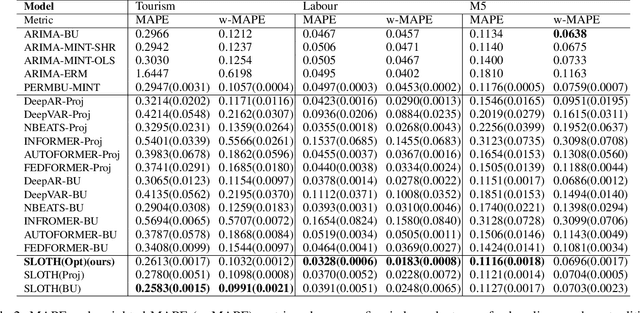
Multivariate time series forecasting with hierarchical structure is widely used in real-world applications, e.g., sales predictions for the geographical hierarchy formed by cities, states, and countries. The hierarchical time series (HTS) forecasting includes two sub-tasks, i.e., forecasting and reconciliation. In the previous works, hierarchical information is only integrated in the reconciliation step to maintain coherency, but not in forecasting step for accuracy improvement. In this paper, we propose two novel tree-based feature integration mechanisms, i.e., top-down convolution and bottom-up attention to leverage the information of the hierarchical structure to improve the forecasting performance. Moreover, unlike most previous reconciliation methods which either rely on strong assumptions or focus on coherent constraints only,we utilize deep neural optimization networks, which not only achieve coherency without any assumptions, but also allow more flexible and realistic constraints to achieve task-based targets, e.g., lower under-estimation penalty and meaningful decision-making loss to facilitate the subsequent downstream tasks. Experiments on real-world datasets demonstrate that our tree-based feature integration mechanism achieves superior performances on hierarchical forecasting tasks compared to the state-of-the-art methods, and our neural optimization networks can be applied to real-world tasks effectively without any additional effort under coherence and task-based constraints