 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProAV-DiT: A Projected Latent Diffusion Transformer for Efficient Synchronized Audio-Video Generation
Nov 15, 2025Sounding Video Generation (SVG) remains a challenging task due to the inherent structural misalignment between audio and video, as well as the high computational cost of multimodal data processing. In this paper, we introduce ProAV-DiT, a Projected Latent Diffusion Transformer designed for efficient and synchronized audio-video generation. To address structural inconsistencies, we preprocess raw audio into video-like representations, aligning both the temporal and spatial dimensions between audio and video. At its core, ProAV-DiT adopts a Multi-scale Dual-stream Spatio-Temporal Autoencoder (MDSA), which projects both modalities into a unified latent space using orthogonal decomposition, enabling fine-grained spatiotemporal modeling and semantic alignment. To further enhance temporal coherence and modality-specific fusion, we introduce a multi-scale attention mechanism, which consists of multi-scale temporal self-attention and group cross-modal attention. Furthermore, we stack the 2D latents from MDSA into a unified 3D latent space, which is processed by a spatio-temporal diffusion Transformer. This design efficiently models spatiotemporal dependencies, enabling the generation of high-fidelity synchronized audio-video content while reducing computational overhead. Extensive experiments conducted on standard benchmarks demonstrate that ProAV-DiT outperforms existing methods in both generation quality and computational efficiency.
COMUNI: Decomposing Common and Unique Video Signals for Diffusion-based Video Generation
Oct 02, 2024
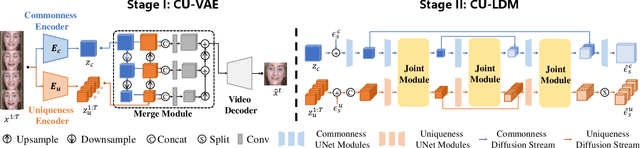
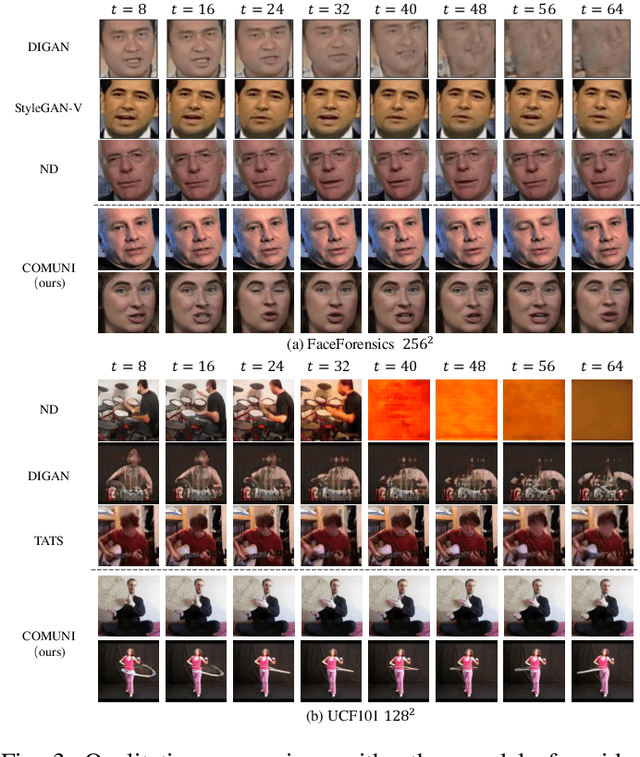
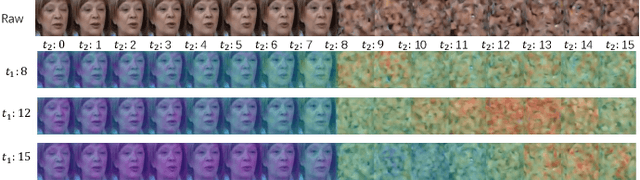
Since videos record objects moving coherently, adjacent video frames have commonness (similar object appearances) and uniqueness (slightly changed postures). To prevent redundant modeling of common video signals, we propose a novel diffusion-based framework, named COMUNI, which decomposes the COMmon and UNIque video signals to enable efficient video generation. Our approach separates the decomposition of video signals from the task of video generation, thus reducing the computation complexity of generative models. In particular, we introduce CU-VAE to decompose video signals and encode them into latent features. To train CU-VAE in a self-supervised manner, we employ a cascading merge module to reconstitute video signals and a time-agnostic video decoder to reconstruct video frames. Then we propose CU-LDM to model latent features for video generation, which adopts two specific diffusion streams to simultaneously model the common and unique latent features. We further utilize additional joint modules for cross modeling of the common and unique latent features, and a novel position embedding method to ensure the content consistency and motion coherence of generated videos. The position embedding method incorporates spatial and temporal absolute position information into the joint modules. Extensive experiments demonstrate the necessity of decomposing common and unique video signals for video generation and the effectiveness and efficiency of our proposed method.
MM-LDM: Multi-Modal Latent Diffusion Model for Sounding Video Generation
Oct 02, 2024Sounding Video Generation (SVG) is an audio-video joint generation task challenged by high-dimensional signal spaces, distinct data formats, and different patterns of content information. To address these issues, we introduce a novel multi-modal latent diffusion model (MM-LDM) for the SVG task. We first unify the representation of audio and video data by converting them into a single or a couple of images. Then, we introduce a hierarchical multi-modal autoencoder that constructs a low-level perceptual latent space for each modality and a shared high-level semantic feature space. The former space is perceptually equivalent to the raw signal space of each modality but drastically reduces signal dimensions. The latter space serves to bridge the information gap between modalities and provides more insightful cross-modal guidance. Our proposed method achieves new state-of-the-art results with significant quality and efficiency gains. Specifically, our method achieves a comprehensive improvement on all evaluation metrics and a faster training and sampling speed on Landscape and AIST++ datasets. Moreover, we explore its performance on open-domain sounding video generation, long sounding video generation, audio continuation, video continuation, and conditional single-modal generation tasks for a comprehensive evaluation, where our MM-LDM demonstrates exciting adaptability and generalization ability.
Enhancing and Accelerating Large Language Models via Instruction-Aware Contextual Compression
Aug 28, 2024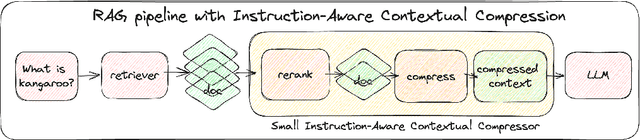


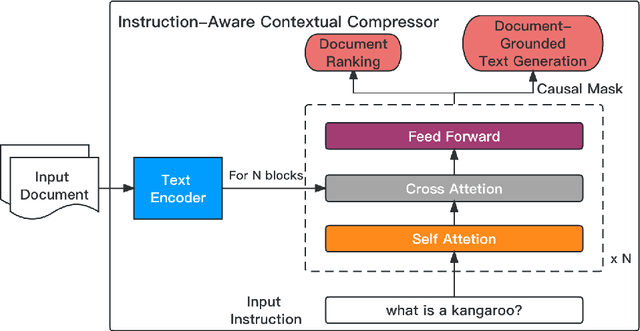
Large Language Models (LLMs) have garnered widespread attention due to their remarkable performance across various tasks. However, to mitigate the issue of hallucinations, LLMs often incorporate retrieval-augmented pipeline to provide them with rich external knowledge and context. Nevertheless, challenges stem from inaccurate and coarse-grained context retrieved from the retriever. Supplying irrelevant context to the LLMs can result in poorer responses, increased inference latency, and higher costs. This paper introduces a method called Instruction-Aware Contextual Compression, which filters out less informative content, thereby accelerating and enhancing the use of LLMs. The experimental results demonstrate that Instruction-Aware Contextual Compression notably reduces memory consumption and minimizes generation latency while maintaining performance levels comparable to those achieved with the use of the full context. Specifically, we achieved a 50% reduction in context-related costs, resulting in a 5% reduction in inference memory usage and a 2.2-fold increase in inference speed, with only a minor drop of 0.047 in Rouge-1. These findings suggest that our method strikes an effective balance between efficiency and performance.
Deep Optimal Timing Strategies for Time Series
Oct 09, 2023



Deciding the best future execution time is a critical task in many business activities while evolving time series forecasting, and optimal timing strategy provides such a solution, which is driven by observed data. This solution has plenty of valuable applications to reduce the operation costs. In this paper, we propose a mechanism that combines a probabilistic time series forecasting task and an optimal timing decision task as a first systematic attempt to tackle these practical problems with both solid theoretical foundation and real-world flexibility. Specifically, it generates the future paths of the underlying time series via probabilistic forecasting algorithms, which does not need a sophisticated mathematical dynamic model relying on strong prior knowledge as most other common practices. In order to find the optimal execution time, we formulate the decision task as an optimal stopping problem, and employ a recurrent neural network structure (RNN) to approximate the optimal times. Github repository: \url{github.com/ChenPopper/optimal_timing_TSF}.
Automatic Deduction Path Learning via Reinforcement Learning with Environmental Correction
Jun 16, 2023

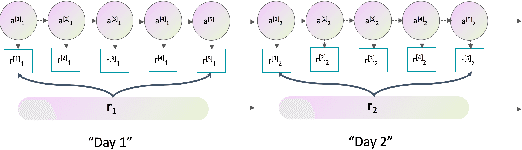

Automatic bill payment is an important part of business operations in fintech companies. The practice of deduction was mainly based on the total amount or heuristic search by dividing the bill into smaller parts to deduct as much as possible. This article proposes an end-to-end approach of automatically learning the optimal deduction paths (deduction amount in order), which reduces the cost of manual path design and maximizes the amount of successful deduction. Specifically, in view of the large search space of the paths and the extreme sparsity of historical successful deduction records, we propose a deep hierarchical reinforcement learning approach which abstracts the action into a two-level hierarchical space: an upper agent that determines the number of steps of deductions each day and a lower agent that decides the amount of deduction at each step. In such a way, the action space is structured via prior knowledge and the exploration space is reduced. Moreover, the inherited information incompleteness of the business makes the environment just partially observable. To be precise, the deducted amounts indicate merely the lower bounds of the available account balance. To this end, we formulate the problem as a partially observable Markov decision problem (POMDP) and employ an environment correction algorithm based on the characteristics of the business. In the world's largest electronic payment business, we have verified the effectiveness of this scheme offline and deployed it online to serve millions of users.
VAST: A Vision-Audio-Subtitle-Text Omni-Modality Foundation Model and Dataset
May 29, 2023



Vision and text have been fully explored in contemporary video-text foundational models, while other modalities such as audio and subtitles in videos have not received sufficient attention. In this paper, we resort to establish connections between multi-modality video tracks, including Vision, Audio, and Subtitle, and Text by exploring an automatically generated large-scale omni-modality video caption dataset called VAST-27M. Specifically, we first collect 27 million open-domain video clips and separately train a vision and an audio captioner to generate vision and audio captions. Then, we employ an off-the-shelf Large Language Model (LLM) to integrate the generated captions, together with subtitles and instructional prompts into omni-modality captions. Based on the proposed VAST-27M dataset, we train an omni-modality video-text foundational model named VAST, which can perceive and process vision, audio, and subtitle modalities from video, and better support various tasks including vision-text, audio-text, and multi-modal video-text tasks (retrieval, captioning and QA). Extensive experiments have been conducted to demonstrate the effectiveness of our proposed VAST-27M corpus and VAST foundation model. VAST achieves 22 new state-of-the-art results on various cross-modality benchmarks. Code, model and dataset will be released at https://github.com/TXH-mercury/VAST.
ChatBridge: Bridging Modalities with Large Language Model as a Language Catalyst
May 25, 2023
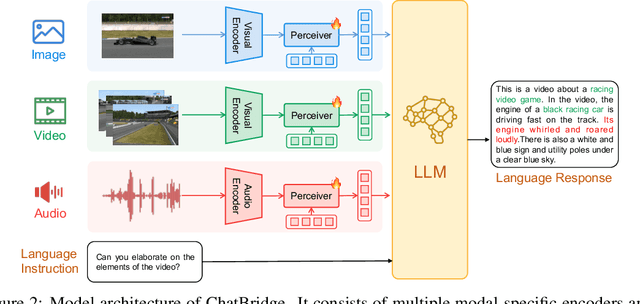
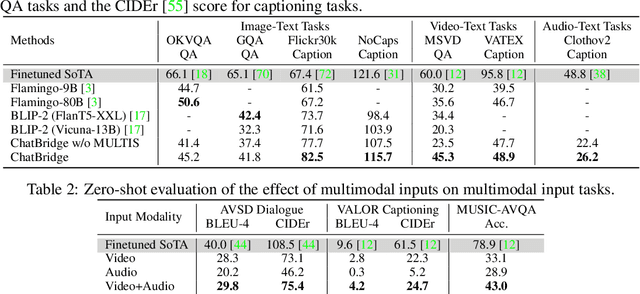
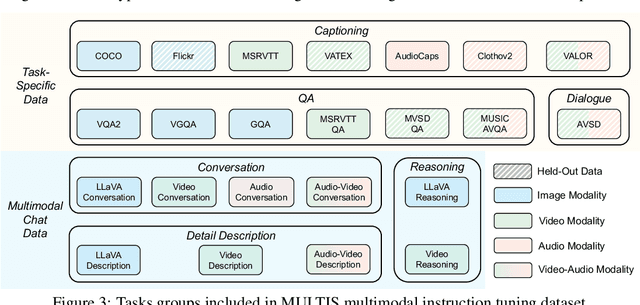
Building general-purpose models that can perceive diverse real-world modalities and solve various tasks is an appealing target in artificial intelligence. In this paper, we present ChatBridge, a novel multimodal language model that leverages the expressive capabilities of language as the catalyst to bridge the gap between various modalities. We show that only language-paired two-modality data is sufficient to connect all modalities. ChatBridge leverages recent large language models (LLM) and extends their zero-shot capabilities to incorporate diverse multimodal inputs. ChatBridge undergoes a two-stage training. The first stage aligns each modality with language, which brings emergent multimodal correlation and collaboration abilities. The second stage instruction-finetunes ChatBridge to align it with user intent with our newly proposed multimodal instruction tuning dataset, named MULTIS, which covers a wide range of 16 multimodal tasks of text, image, video, and audio modalities. We show strong quantitative and qualitative results on zero-shot multimodal tasks covering text, image, video, and audio modalities. All codes, data, and models of ChatBridge will be open-sourced.
VALOR: Vision-Audio-Language Omni-Perception Pretraining Model and Dataset
Apr 17, 2023In this paper, we propose a Vision-Audio-Language Omni-peRception pretraining model (VALOR) for multi-modal understanding and generation. Different from widely-studied vision-language pretraining models, VALOR jointly models relationships of vision, audio and language in an end-to-end manner. It contains three separate encoders for single modality representations, and a decoder for multimodal conditional text generation. We design two pretext tasks to pretrain VALOR model, including Multimodal Grouping Alignment (MGA) and Multimodal Grouping Captioning (MGC). MGA projects vision, language and audio to the same common space, building vision-language, audio-language and audiovisual-language alignment simultaneously. MGC learns how to generate text tokens in conditions of vision, audio or their both. To promote vision-audio-language pretraining research, we construct a large-scale high-quality tri-modality dataset named VALOR-1M, which contains 1M audiable videos with human annotated audiovisual captions. Extensive experiments show that VALOR can learn strong multimodal correlations and be generalized to various downstream tasks (e.g., retrieval, captioning and question answering), with different input modalities (e.g., vision-language, audio-language and audiovisual-language). VALOR achieves new state-of-the-art performances on series of public cross-modality benchmarks. Code and data are available at project page https://casia-iva-group.github.io/projects/VALOR.
Sounding Video Generator: A Unified Framework for Text-guided Sounding Video Generation
Mar 29, 2023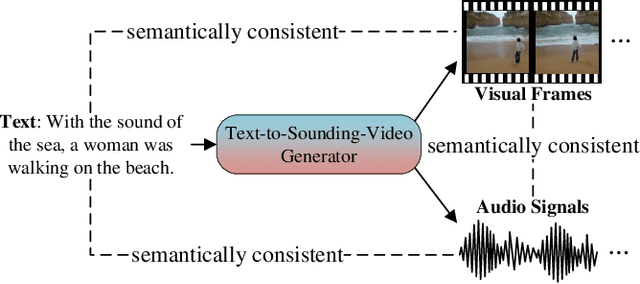
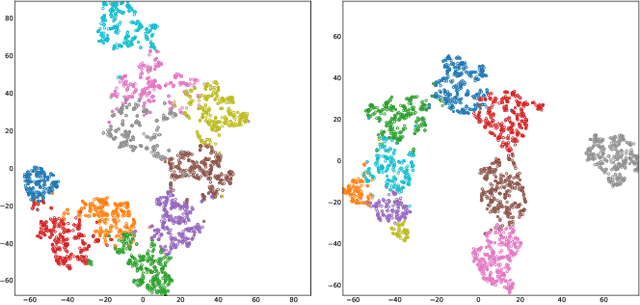
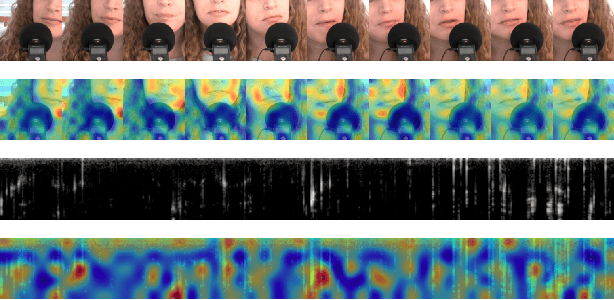
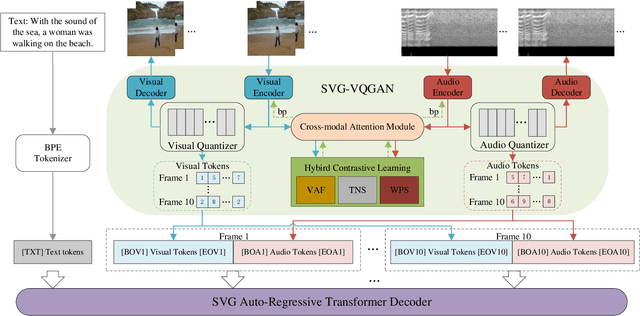
As a combination of visual and audio signals, video is inherently multi-modal. However, existing video generation methods are primarily intended for the synthesis of visual frames, whereas audio signals in realistic videos are disregarded. In this work, we concentrate on a rarely investigated problem of text guided sounding video generation and propose the Sounding Video Generator (SVG), a unified framework for generating realistic videos along with audio signals. Specifically, we present the SVG-VQGAN to transform visual frames and audio melspectrograms into discrete tokens. SVG-VQGAN applies a novel hybrid contrastive learning method to model inter-modal and intra-modal consistency and improve the quantized representations. A cross-modal attention module is employed to extract associated features of visual frames and audio signals for contrastive learning. Then, a Transformer-based decoder is used to model associations between texts, visual frames, and audio signals at token level for auto-regressive sounding video generation. AudioSetCap, a human annotated text-video-audio paired dataset, is produced for training SVG. Experimental results demonstrate the superiority of our method when compared with existing textto-video generation methods as well as audio generation methods on Kinetics and VAS datasets.