 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSounding Video Generator: A Unified Framework for Text-guided Sounding Video Generation
Paper and Code
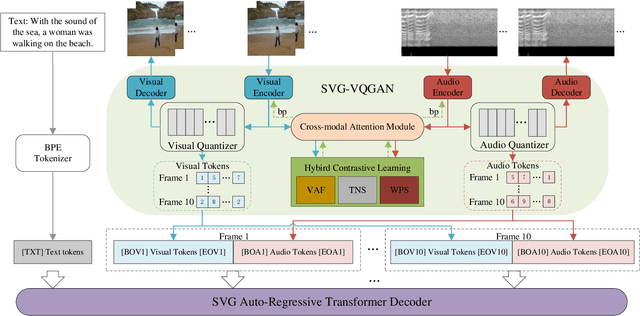
As a combination of visual and audio signals, video is inherently multi-modal. However, existing video generation methods are primarily intended for the synthesis of visual frames, whereas audio signals in realistic videos are disregarded. In this work, we concentrate on a rarely investigated problem of text guided sounding video generation and propose the Sounding Video Generator (SVG), a unified framework for generating realistic videos along with audio signals. Specifically, we present the SVG-VQGAN to transform visual frames and audio melspectrograms into discrete tokens. SVG-VQGAN applies a novel hybrid contrastive learning method to model inter-modal and intra-modal consistency and improve the quantized representations. A cross-modal attention module is employed to extract associated features of visual frames and audio signals for contrastive learning. Then, a Transformer-based decoder is used to model associations between texts, visual frames, and audio signals at token level for auto-regressive sounding video generation. AudioSetCap, a human annotated text-video-audio paired dataset, is produced for training SVG. Experimental results demonstrate the superiority of our method when compared with existing textto-video generation methods as well as audio generation methods on Kinetics and VAS datasets.