 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefReward-SR: LR-Conditioned Reward Modeling for Preference-Aligned Super-Resolution
Mar 25, 2026Recent advances in generative super-resolution (SR) have greatly improved visual realism, yet existing evaluation and optimization frameworks remain misaligned with human perception. Full-Reference and No-Reference metrics often fail to reflect perceptual preference, either penalizing semantically plausible details due to pixel misalignment or favoring visually sharp but inconsistent artifacts. Moreover, most SR methods rely on ground-truth (GT)-dependent distribution matching, which does not necessarily correspond to human judgments. In this work, we propose RefReward-SR, a low-resolution (LR) reference-aware reward model for preference-aligned SR. Instead of relying on GT supervision or NR evaluation, RefReward-SR assesses high-resolution (HR) reconstructions conditioned on their LR inputs, treating the LR image as a semantic anchor. Leveraging the visual-linguistic priors of a Multimodal Large Language Models (MLLM), it evaluates semantic consistency and plausibility in a reasoning-aware manner. To support this paradigm, we construct RefSR-18K, the first large-scale LR-conditioned preference dataset for SR, providing pairwise rankings based on LR-HR consistency and HR naturalness. We fine-tune the MLLM with Group Relative Policy Optimization (GRPO) using LR-conditioned ranking rewards, and further integrate GRPO into SR model training with RefReward-SR as the core reward signal for preference-aligned generation. Extensive experiments show that our framework achieves substantially better alignment with human judgments, producing reconstructions that preserve semantic consistency while enhancing perceptual plausibility and visual naturalness. Code, models, and datasets will be released upon paper acceptance.
Transformer-based CoVaR: Systemic Risk in Textual Information
Feb 13, 2026Conditional Value-at-Risk (CoVaR) quantifies systemic financial risk by measuring the loss quantile of one asset, conditional on another asset experiencing distress. We develop a Transformer-based methodology that integrates financial news articles directly with market data to improve CoVaR estimates. Unlike approaches that use predefined sentiment scores, our method incorporates raw text embeddings generated by a large language model (LLM). We prove explicit error bounds for our Transformer CoVaR estimator, showing that accurate CoVaR learning is possible even with small datasets. Using U.S. market returns and Reuters news items from 2006--2013, our out-of-sample results show that textual information impacts the CoVaR forecasts. With better predictive performance, we identify a pronounced negative dip during market stress periods across several equity assets when comparing the Transformer-based CoVaR to both the CoVaR without text and the CoVaR using traditional sentiment measures. Our results show that textual data can be used to effectively model systemic risk without requiring prohibitively large data sets.
3SGen: Unified Subject, Style, and Structure-Driven Image Generation with Adaptive Task-specific Memory
Dec 22, 2025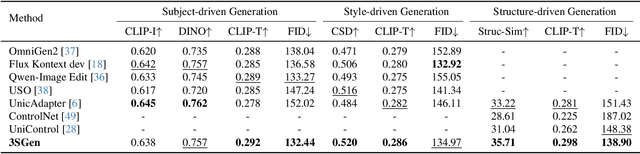
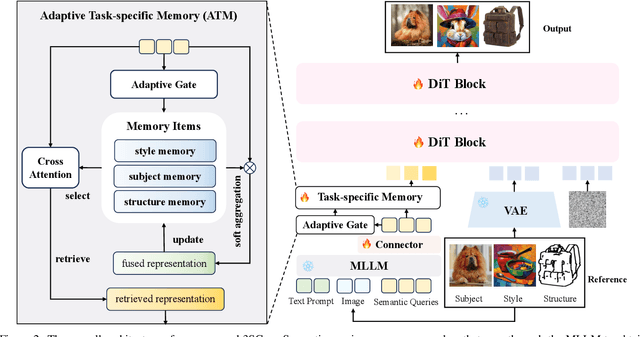
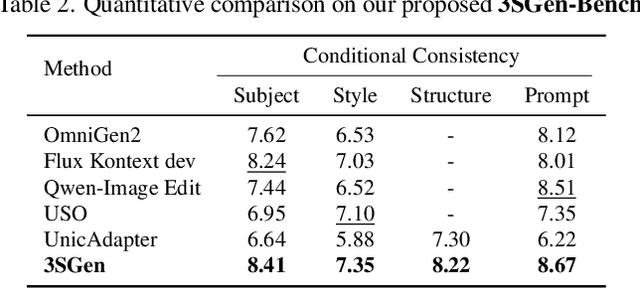
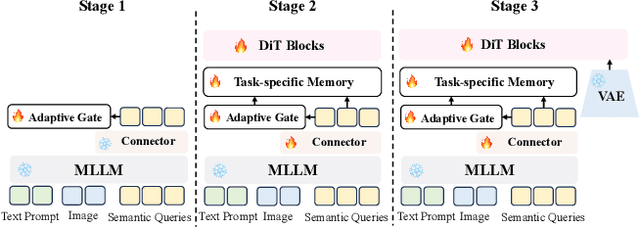
Recent image generation approaches often address subject, style, and structure-driven conditioning in isolation, leading to feature entanglement and limited task transferability. In this paper, we introduce 3SGen, a task-aware unified framework that performs all three conditioning modes within a single model. 3SGen employs an MLLM equipped with learnable semantic queries to align text-image semantics, complemented by a VAE branch that preserves fine-grained visual details. At its core, an Adaptive Task-specific Memory (ATM) module dynamically disentangles, stores, and retrieves condition-specific priors, such as identity for subjects, textures for styles, and spatial layouts for structures, via a lightweight gating mechanism along with several scalable memory items. This design mitigates inter-task interference and naturally scales to compositional inputs. In addition, we propose 3SGen-Bench, a unified image-driven generation benchmark with standardized metrics for evaluating cross-task fidelity and controllability. Extensive experiments on our proposed 3SGen-Bench and other public benchmarks demonstrate our superior performance across diverse image-driven generation tasks.
TTP: Test-Time Padding for Adversarial Detection and Robust Adaptation on Vision-Language Models
Dec 18, 2025



Vision-Language Models (VLMs), such as CLIP, have achieved impressive zero-shot recognition performance but remain highly susceptible to adversarial perturbations, posing significant risks in safety-critical scenarios. Previous training-time defenses rely on adversarial fine-tuning, which requires labeled data and costly retraining, while existing test-time strategies fail to reliably distinguish between clean and adversarial inputs, thereby preventing both adversarial robustness and clean accuracy from reaching their optimum. To address these limitations, we propose Test-Time Padding (TTP), a lightweight defense framework that performs adversarial detection followed by targeted adaptation at inference. TTP identifies adversarial inputs via the cosine similarity shift between CLIP feature embeddings computed before and after spatial padding, yielding a universal threshold for reliable detection across architectures and datasets. For detected adversarial cases, TTP employs trainable padding to restore disrupted attention patterns, coupled with a similarity-aware ensemble strategy for a more robust final prediction. For clean inputs, TTP leaves them unchanged by default or optionally integrates existing test-time adaptation techniques for further accuracy gains. Comprehensive experiments on diverse CLIP backbones and fine-grained benchmarks show that TTP consistently surpasses state-of-the-art test-time defenses, delivering substantial improvements in adversarial robustness without compromising clean accuracy. The code for this paper will be released soon.
ProAV-DiT: A Projected Latent Diffusion Transformer for Efficient Synchronized Audio-Video Generation
Nov 15, 2025Sounding Video Generation (SVG) remains a challenging task due to the inherent structural misalignment between audio and video, as well as the high computational cost of multimodal data processing. In this paper, we introduce ProAV-DiT, a Projected Latent Diffusion Transformer designed for efficient and synchronized audio-video generation. To address structural inconsistencies, we preprocess raw audio into video-like representations, aligning both the temporal and spatial dimensions between audio and video. At its core, ProAV-DiT adopts a Multi-scale Dual-stream Spatio-Temporal Autoencoder (MDSA), which projects both modalities into a unified latent space using orthogonal decomposition, enabling fine-grained spatiotemporal modeling and semantic alignment. To further enhance temporal coherence and modality-specific fusion, we introduce a multi-scale attention mechanism, which consists of multi-scale temporal self-attention and group cross-modal attention. Furthermore, we stack the 2D latents from MDSA into a unified 3D latent space, which is processed by a spatio-temporal diffusion Transformer. This design efficiently models spatiotemporal dependencies, enabling the generation of high-fidelity synchronized audio-video content while reducing computational overhead. Extensive experiments conducted on standard benchmarks demonstrate that ProAV-DiT outperforms existing methods in both generation quality and computational efficiency.
PhysCorr: Dual-Reward DPO for Physics-Constrained Text-to-Video Generation with Automated Preference Selection
Nov 06, 2025



Recent advances in text-to-video generation have achieved impressive perceptual quality, yet generated content often violates fundamental principles of physical plausibility - manifesting as implausible object dynamics, incoherent interactions, and unrealistic motion patterns. Such failures hinder the deployment of video generation models in embodied AI, robotics, and simulation-intensive domains. To bridge this gap, we propose PhysCorr, a unified framework for modeling, evaluating, and optimizing physical consistency in video generation. Specifically, we introduce PhysicsRM, the first dual-dimensional reward model that quantifies both intra-object stability and inter-object interactions. On this foundation, we develop PhyDPO, a novel direct preference optimization pipeline that leverages contrastive feedback and physics-aware reweighting to guide generation toward physically coherent outputs. Our approach is model-agnostic and scalable, enabling seamless integration into a wide range of video diffusion and transformer-based backbones. Extensive experiments across multiple benchmarks demonstrate that PhysCorr achieves significant improvements in physical realism while preserving visual fidelity and semantic alignment. This work takes a critical step toward physically grounded and trustworthy video generation.
Learning Unknown Spoof Prompts for Generalized Face Anti-Spoofing Using Only Real Face Images
May 06, 2025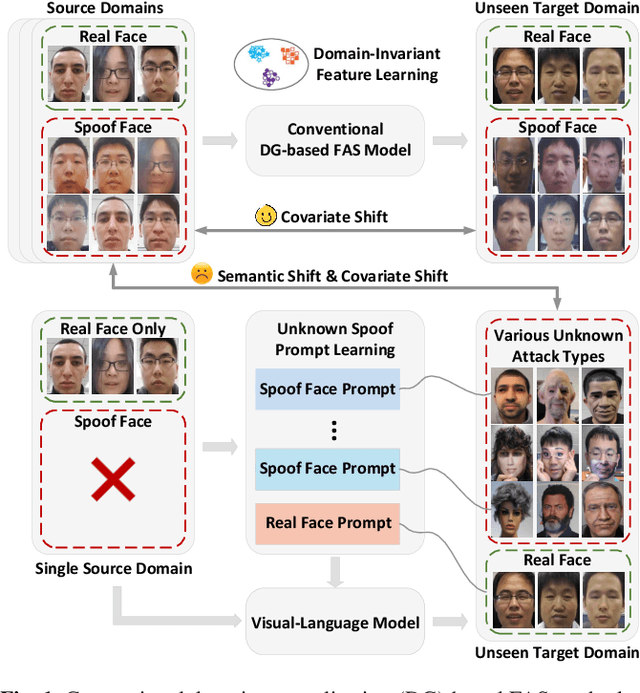

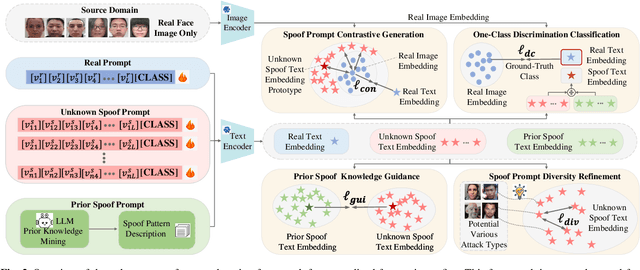
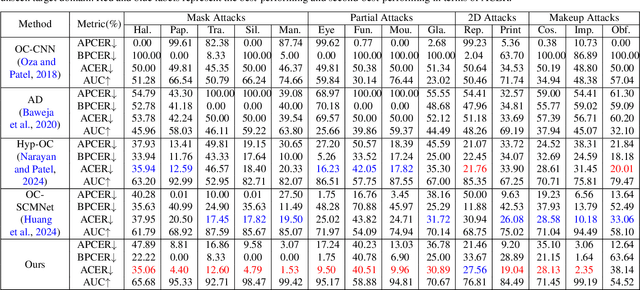
Face anti-spoofing is a critical technology for ensuring the security of face recognition systems. However, its ability to generalize across diverse scenarios remains a significant challenge. In this paper, we attribute the limited generalization ability to two key factors: covariate shift, which arises from external data collection variations, and semantic shift, which results from substantial differences in emerging attack types. To address both challenges, we propose a novel approach for learning unknown spoof prompts, relying solely on real face images from a single source domain. Our method generates textual prompts for real faces and potential unknown spoof attacks by leveraging the general knowledge embedded in vision-language models, thereby enhancing the model's ability to generalize to unseen target domains. Specifically, we introduce a diverse spoof prompt optimization framework to learn effective prompts. This framework constrains unknown spoof prompts within a relaxed prior knowledge space while maximizing their distance from real face images. Moreover, it enforces semantic independence among different spoof prompts to capture a broad range of spoof patterns. Experimental results on nine datasets demonstrate that the learned prompts effectively transfer the knowledge of vision-language models, enabling state-of-the-art generalization ability against diverse unknown attack types across unseen target domains without using any spoof face images.
Learning Knowledge-based Prompts for Robust 3D Mask Presentation Attack Detection
May 06, 20253D mask presentation attack detection is crucial for protecting face recognition systems against the rising threat of 3D mask attacks. While most existing methods utilize multimodal features or remote photoplethysmography (rPPG) signals to distinguish between real faces and 3D masks, they face significant challenges, such as the high costs associated with multimodal sensors and limited generalization ability. Detection-related text descriptions offer concise, universal information and are cost-effective to obtain. However, the potential of vision-language multimodal features for 3D mask presentation attack detection remains unexplored. In this paper, we propose a novel knowledge-based prompt learning framework to explore the strong generalization capability of vision-language models for 3D mask presentation attack detection. Specifically, our approach incorporates entities and triples from knowledge graphs into the prompt learning process, generating fine-grained, task-specific explicit prompts that effectively harness the knowledge embedded in pre-trained vision-language models. Furthermore, considering different input images may emphasize distinct knowledge graph elements, we introduce a visual-specific knowledge filter based on an attention mechanism to refine relevant elements according to the visual context. Additionally, we leverage causal graph theory insights into the prompt learning process to further enhance the generalization ability of our method. During training, a spurious correlation elimination paradigm is employed, which removes category-irrelevant local image patches using guidance from knowledge-based text features, fostering the learning of generalized causal prompts that align with category-relevant local patches. Experimental results demonstrate that the proposed method achieves state-of-the-art intra- and cross-scenario detection performance on benchmark datasets.
AR-Diffusion: Asynchronous Video Generation with Auto-Regressive Diffusion
Mar 10, 2025



The task of video generation requires synthesizing visually realistic and temporally coherent video frames. Existing methods primarily use asynchronous auto-regressive models or synchronous diffusion models to address this challenge. However, asynchronous auto-regressive models often suffer from inconsistencies between training and inference, leading to issues such as error accumulation, while synchronous diffusion models are limited by their reliance on rigid sequence length. To address these issues, we introduce Auto-Regressive Diffusion (AR-Diffusion), a novel model that combines the strengths of auto-regressive and diffusion models for flexible, asynchronous video generation. Specifically, our approach leverages diffusion to gradually corrupt video frames in both training and inference, reducing the discrepancy between these phases. Inspired by auto-regressive generation, we incorporate a non-decreasing constraint on the corruption timesteps of individual frames, ensuring that earlier frames remain clearer than subsequent ones. This setup, together with temporal causal attention, enables flexible generation of videos with varying lengths while preserving temporal coherence. In addition, we design two specialized timestep schedulers: the FoPP scheduler for balanced timestep sampling during training, and the AD scheduler for flexible timestep differences during inference, supporting both synchronous and asynchronous generation. Extensive experiments demonstrate the superiority of our proposed method, which achieves competitive and state-of-the-art results across four challenging benchmarks.
COMUNI: Decomposing Common and Unique Video Signals for Diffusion-based Video Generation
Oct 02, 2024
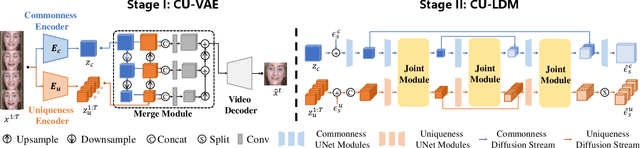
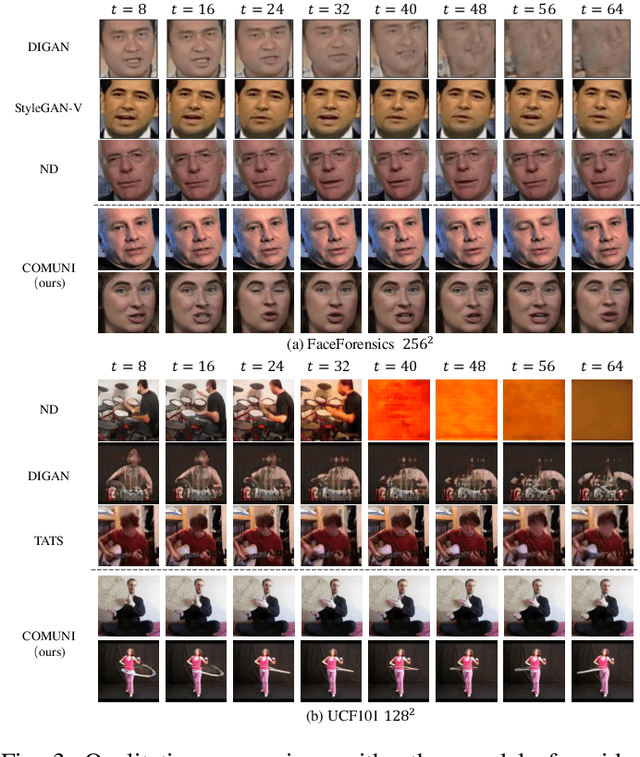
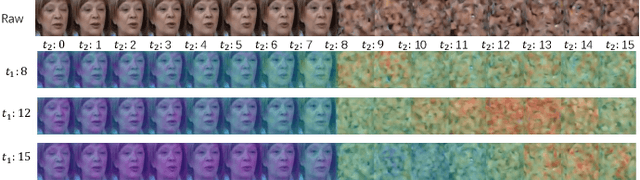
Since videos record objects moving coherently, adjacent video frames have commonness (similar object appearances) and uniqueness (slightly changed postures). To prevent redundant modeling of common video signals, we propose a novel diffusion-based framework, named COMUNI, which decomposes the COMmon and UNIque video signals to enable efficient video generation. Our approach separates the decomposition of video signals from the task of video generation, thus reducing the computation complexity of generative models. In particular, we introduce CU-VAE to decompose video signals and encode them into latent features. To train CU-VAE in a self-supervised manner, we employ a cascading merge module to reconstitute video signals and a time-agnostic video decoder to reconstruct video frames. Then we propose CU-LDM to model latent features for video generation, which adopts two specific diffusion streams to simultaneously model the common and unique latent features. We further utilize additional joint modules for cross modeling of the common and unique latent features, and a novel position embedding method to ensure the content consistency and motion coherence of generated videos. The position embedding method incorporates spatial and temporal absolute position information into the joint modules. Extensive experiments demonstrate the necessity of decomposing common and unique video signals for video generation and the effectiveness and efficiency of our proposed method.