 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProAV-DiT: A Projected Latent Diffusion Transformer for Efficient Synchronized Audio-Video Generation
Nov 15, 2025Sounding Video Generation (SVG) remains a challenging task due to the inherent structural misalignment between audio and video, as well as the high computational cost of multimodal data processing. In this paper, we introduce ProAV-DiT, a Projected Latent Diffusion Transformer designed for efficient and synchronized audio-video generation. To address structural inconsistencies, we preprocess raw audio into video-like representations, aligning both the temporal and spatial dimensions between audio and video. At its core, ProAV-DiT adopts a Multi-scale Dual-stream Spatio-Temporal Autoencoder (MDSA), which projects both modalities into a unified latent space using orthogonal decomposition, enabling fine-grained spatiotemporal modeling and semantic alignment. To further enhance temporal coherence and modality-specific fusion, we introduce a multi-scale attention mechanism, which consists of multi-scale temporal self-attention and group cross-modal attention. Furthermore, we stack the 2D latents from MDSA into a unified 3D latent space, which is processed by a spatio-temporal diffusion Transformer. This design efficiently models spatiotemporal dependencies, enabling the generation of high-fidelity synchronized audio-video content while reducing computational overhead. Extensive experiments conducted on standard benchmarks demonstrate that ProAV-DiT outperforms existing methods in both generation quality and computational efficiency.
AR-Diffusion: Asynchronous Video Generation with Auto-Regressive Diffusion
Mar 10, 2025



The task of video generation requires synthesizing visually realistic and temporally coherent video frames. Existing methods primarily use asynchronous auto-regressive models or synchronous diffusion models to address this challenge. However, asynchronous auto-regressive models often suffer from inconsistencies between training and inference, leading to issues such as error accumulation, while synchronous diffusion models are limited by their reliance on rigid sequence length. To address these issues, we introduce Auto-Regressive Diffusion (AR-Diffusion), a novel model that combines the strengths of auto-regressive and diffusion models for flexible, asynchronous video generation. Specifically, our approach leverages diffusion to gradually corrupt video frames in both training and inference, reducing the discrepancy between these phases. Inspired by auto-regressive generation, we incorporate a non-decreasing constraint on the corruption timesteps of individual frames, ensuring that earlier frames remain clearer than subsequent ones. This setup, together with temporal causal attention, enables flexible generation of videos with varying lengths while preserving temporal coherence. In addition, we design two specialized timestep schedulers: the FoPP scheduler for balanced timestep sampling during training, and the AD scheduler for flexible timestep differences during inference, supporting both synchronous and asynchronous generation. Extensive experiments demonstrate the superiority of our proposed method, which achieves competitive and state-of-the-art results across four challenging benchmarks.
I2VControl-Camera: Precise Video Camera Control with Adjustable Motion Strength
Nov 26, 2024

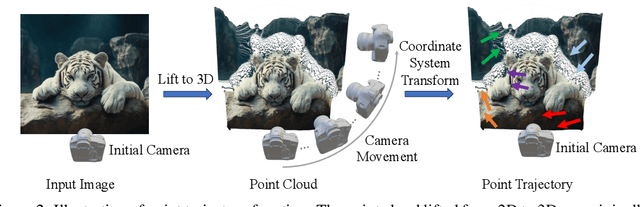
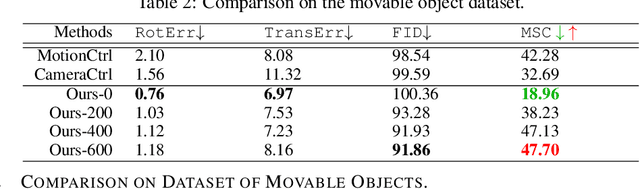
Video generation technologies are developing rapidly and have broad potential applications. Among these technologies, camera control is crucial for generating professional-quality videos that accurately meet user expectations. However, existing camera control methods still suffer from several limitations, including control precision and the neglect of the control for subject motion dynamics. In this work, we propose I2VControl-Camera, a novel camera control method that significantly enhances controllability while providing adjustability over the strength of subject motion. To improve control precision, we employ point trajectory in the camera coordinate system instead of only extrinsic matrix information as our control signal. To accurately control and adjust the strength of subject motion, we explicitly model the higher-order components of the video trajectory expansion, not merely the linear terms, and design an operator that effectively represents the motion strength. We use an adapter architecture that is independent of the base model structure. Experiments on static and dynamic scenes show that our framework outperformances previous methods both quantitatively and qualitatively. The project page is: https://wanquanf.github.io/I2VControlCamera .
I2VControl: Disentangled and Unified Video Motion Synthesis Control
Nov 26, 2024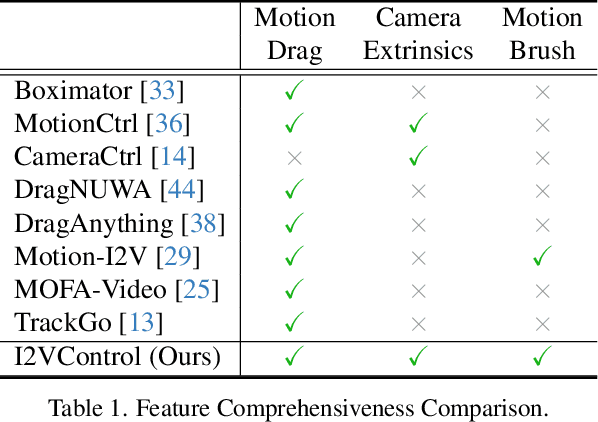
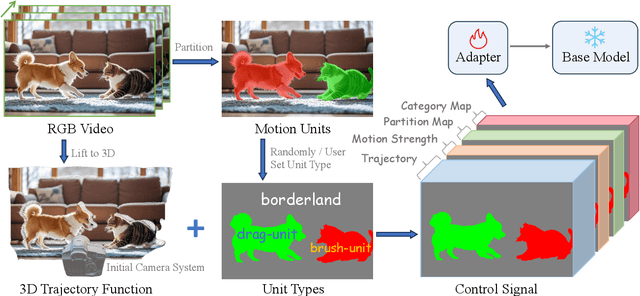
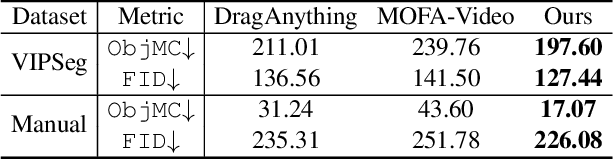

Video synthesis techniques are undergoing rapid progress, with controllability being a significant aspect of practical usability for end-users. Although text condition is an effective way to guide video synthesis, capturing the correct joint distribution between text descriptions and video motion remains a substantial challenge. In this paper, we present a disentangled and unified framework, namely I2VControl, that unifies multiple motion control tasks in image-to-video synthesis. Our approach partitions the video into individual motion units and represents each unit with disentangled control signals, which allows for various control types to be flexibly combined within our single system. Furthermore, our methodology seamlessly integrates as a plug-in for pre-trained models and remains agnostic to specific model architectures. We conduct extensive experiments, achieving excellent performance on various control tasks, and our method further facilitates user-driven creative combinations, enhancing innovation and creativity. The project page is: https://wanquanf.github.io/I2VControl .
MM-LDM: Multi-Modal Latent Diffusion Model for Sounding Video Generation
Oct 02, 2024Sounding Video Generation (SVG) is an audio-video joint generation task challenged by high-dimensional signal spaces, distinct data formats, and different patterns of content information. To address these issues, we introduce a novel multi-modal latent diffusion model (MM-LDM) for the SVG task. We first unify the representation of audio and video data by converting them into a single or a couple of images. Then, we introduce a hierarchical multi-modal autoencoder that constructs a low-level perceptual latent space for each modality and a shared high-level semantic feature space. The former space is perceptually equivalent to the raw signal space of each modality but drastically reduces signal dimensions. The latter space serves to bridge the information gap between modalities and provides more insightful cross-modal guidance. Our proposed method achieves new state-of-the-art results with significant quality and efficiency gains. Specifically, our method achieves a comprehensive improvement on all evaluation metrics and a faster training and sampling speed on Landscape and AIST++ datasets. Moreover, we explore its performance on open-domain sounding video generation, long sounding video generation, audio continuation, video continuation, and conditional single-modal generation tasks for a comprehensive evaluation, where our MM-LDM demonstrates exciting adaptability and generalization ability.
COMUNI: Decomposing Common and Unique Video Signals for Diffusion-based Video Generation
Oct 02, 2024
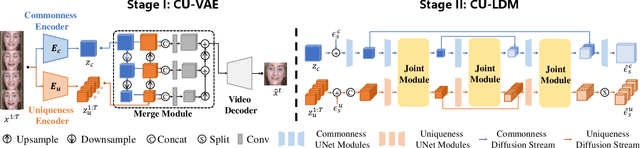
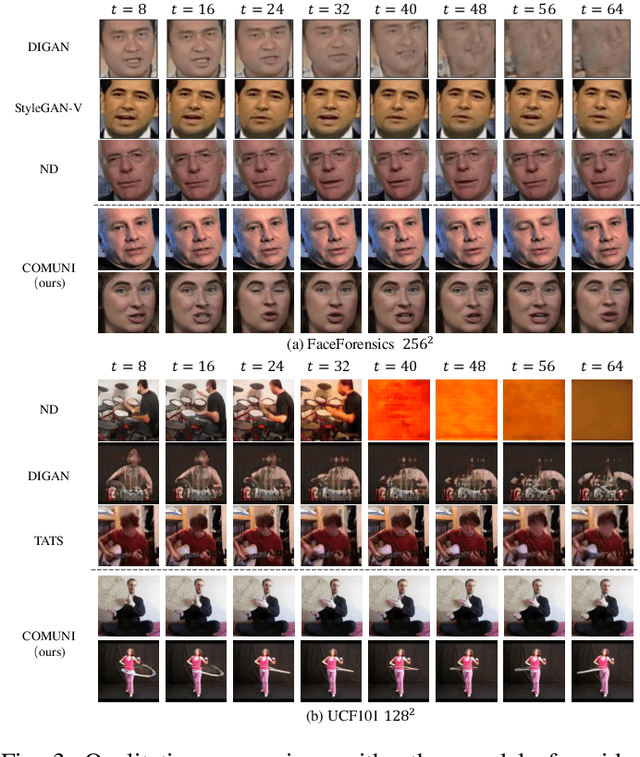
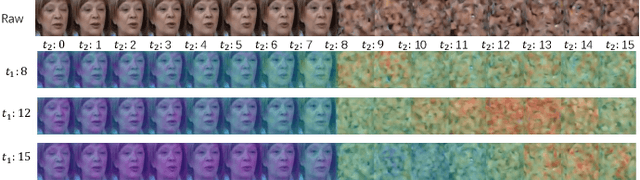
Since videos record objects moving coherently, adjacent video frames have commonness (similar object appearances) and uniqueness (slightly changed postures). To prevent redundant modeling of common video signals, we propose a novel diffusion-based framework, named COMUNI, which decomposes the COMmon and UNIque video signals to enable efficient video generation. Our approach separates the decomposition of video signals from the task of video generation, thus reducing the computation complexity of generative models. In particular, we introduce CU-VAE to decompose video signals and encode them into latent features. To train CU-VAE in a self-supervised manner, we employ a cascading merge module to reconstitute video signals and a time-agnostic video decoder to reconstruct video frames. Then we propose CU-LDM to model latent features for video generation, which adopts two specific diffusion streams to simultaneously model the common and unique latent features. We further utilize additional joint modules for cross modeling of the common and unique latent features, and a novel position embedding method to ensure the content consistency and motion coherence of generated videos. The position embedding method incorporates spatial and temporal absolute position information into the joint modules. Extensive experiments demonstrate the necessity of decomposing common and unique video signals for video generation and the effectiveness and efficiency of our proposed method.
VL-Mamba: Exploring State Space Models for Multimodal Learning
Mar 20, 2024
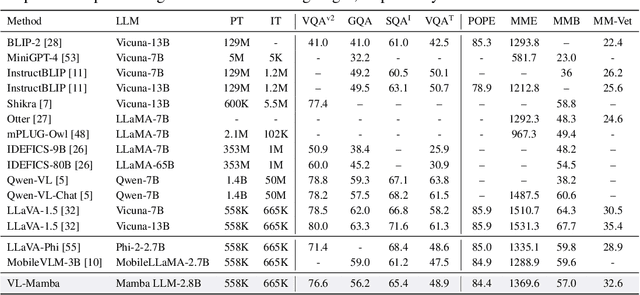


Multimodal large language models (MLLMs) have attracted widespread interest and have rich applications. However, the inherent attention mechanism in its Transformer structure requires quadratic complexity and results in expensive computational overhead. Therefore, in this work, we propose VL-Mamba, a multimodal large language model based on state space models, which have been shown to have great potential for long-sequence modeling with fast inference and linear scaling in sequence length. Specifically, we first replace the transformer-based backbone language model such as LLama or Vicuna with the pre-trained Mamba language model. Then, we empirically explore how to effectively apply the 2D vision selective scan mechanism for multimodal learning and the combinations of different vision encoders and variants of pretrained Mamba language models. The extensive experiments on diverse multimodal benchmarks with competitive performance show the effectiveness of our proposed VL-Mamba and demonstrate the great potential of applying state space models for multimodal learning tasks.
GLOBER: Coherent Non-autoregressive Video Generation via GLOBal Guided Video DecodER
Sep 23, 2023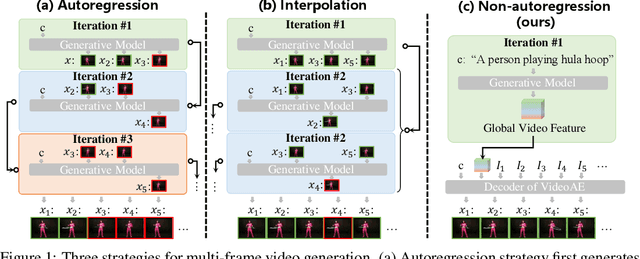
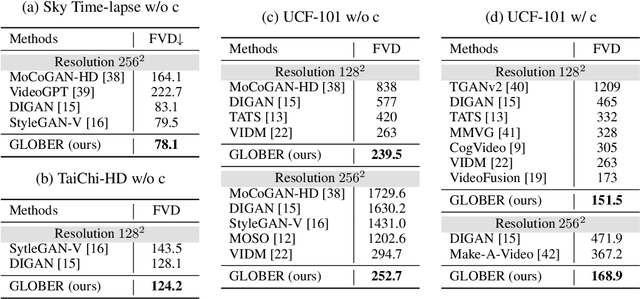
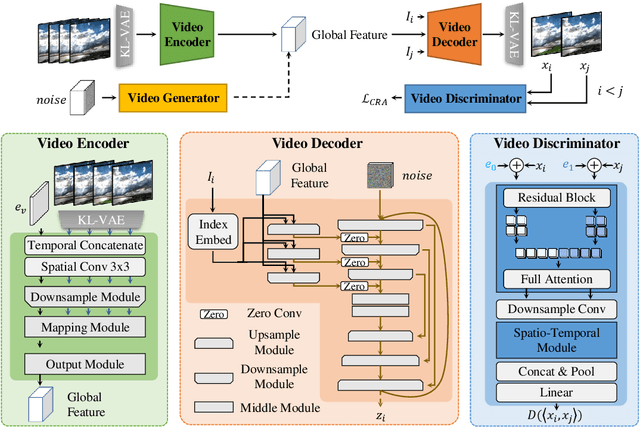

Video generation necessitates both global coherence and local realism. This work presents a novel non-autoregressive method GLOBER, which first generates global features to obtain comprehensive global guidance and then synthesizes video frames based on the global features to generate coherent videos. Specifically, we propose a video auto-encoder, where a video encoder encodes videos into global features, and a video decoder, built on a diffusion model, decodes the global features and synthesizes video frames in a non-autoregressive manner. To achieve maximum flexibility, our video decoder perceives temporal information through normalized frame indexes, which enables it to synthesize arbitrary sub video clips with predetermined starting and ending frame indexes. Moreover, a novel adversarial loss is introduced to improve the global coherence and local realism between the synthesized video frames. Finally, we employ a diffusion-based video generator to fit the global features outputted by the video encoder for video generation. Extensive experimental results demonstrate the effectiveness and efficiency of our proposed method, and new state-of-the-art results have been achieved on multiple benchmarks.
VAST: A Vision-Audio-Subtitle-Text Omni-Modality Foundation Model and Dataset
May 29, 2023



Vision and text have been fully explored in contemporary video-text foundational models, while other modalities such as audio and subtitles in videos have not received sufficient attention. In this paper, we resort to establish connections between multi-modality video tracks, including Vision, Audio, and Subtitle, and Text by exploring an automatically generated large-scale omni-modality video caption dataset called VAST-27M. Specifically, we first collect 27 million open-domain video clips and separately train a vision and an audio captioner to generate vision and audio captions. Then, we employ an off-the-shelf Large Language Model (LLM) to integrate the generated captions, together with subtitles and instructional prompts into omni-modality captions. Based on the proposed VAST-27M dataset, we train an omni-modality video-text foundational model named VAST, which can perceive and process vision, audio, and subtitle modalities from video, and better support various tasks including vision-text, audio-text, and multi-modal video-text tasks (retrieval, captioning and QA). Extensive experiments have been conducted to demonstrate the effectiveness of our proposed VAST-27M corpus and VAST foundation model. VAST achieves 22 new state-of-the-art results on various cross-modality benchmarks. Code, model and dataset will be released at https://github.com/TXH-mercury/VAST.
MOSO: Decomposing MOtion, Scene and Object for Video Prediction
Mar 16, 2023



Motion, scene and object are three primary visual components of a video. In particular, objects represent the foreground, scenes represent the background, and motion traces their dynamics. Based on this insight, we propose a two-stage MOtion, Scene and Object decomposition framework (MOSO) for video prediction, consisting of MOSO-VQVAE and MOSO-Transformer. In the first stage, MOSO-VQVAE decomposes a previous video clip into the motion, scene and object components, and represents them as distinct groups of discrete tokens. Then, in the second stage, MOSO-Transformer predicts the object and scene tokens of the subsequent video clip based on the previous tokens and adds dynamic motion at the token level to the generated object and scene tokens. Our framework can be easily extended to unconditional video generation and video frame interpolation tasks. Experimental results demonstrate that our method achieves new state-of-the-art performance on five challenging benchmarks for video prediction and unconditional video generation: BAIR, RoboNet, KTH, KITTI and UCF101. In addition, MOSO can produce realistic videos by combining objects and scenes from different videos.