 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausalDiffTab: Mixed-Type Causal-Aware Diffusion for Tabular Data Generation
Jun 17, 2025Training data has been proven to be one of the most critical components in training generative AI. However, obtaining high-quality data remains challenging, with data privacy issues presenting a significant hurdle. To address the need for high-quality data. Synthesize data has emerged as a mainstream solution, demonstrating impressive performance in areas such as images, audio, and video. Generating mixed-type data, especially high-quality tabular data, still faces significant challenges. These primarily include its inherent heterogeneous data types, complex inter-variable relationships, and intricate column-wise distributions. In this paper, we introduce CausalDiffTab, a diffusion model-based generative model specifically designed to handle mixed tabular data containing both numerical and categorical features, while being more flexible in capturing complex interactions among variables. We further propose a hybrid adaptive causal regularization method based on the principle of Hierarchical Prior Fusion. This approach adaptively controls the weight of causal regularization, enhancing the model's performance without compromising its generative capabilities. Comprehensive experiments conducted on seven datasets demonstrate that CausalDiffTab outperforms baseline methods across all metrics. Our code is publicly available at: https://github.com/Godz-z/CausalDiffTab.
Mixture of Routers
Mar 30, 2025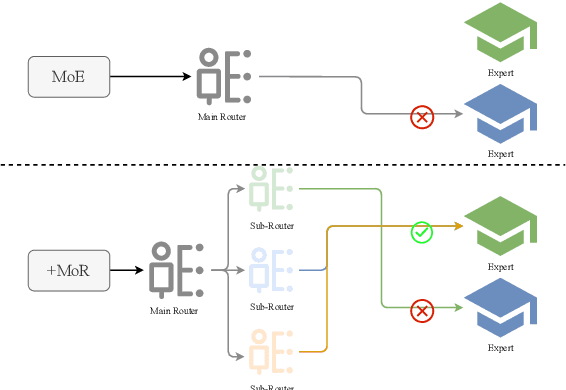
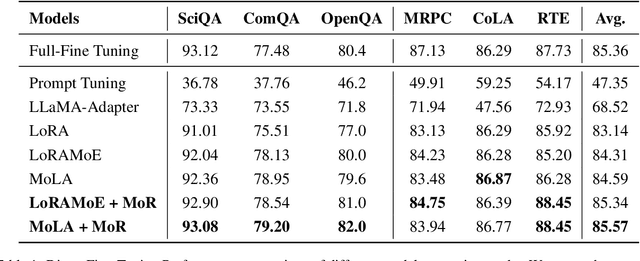
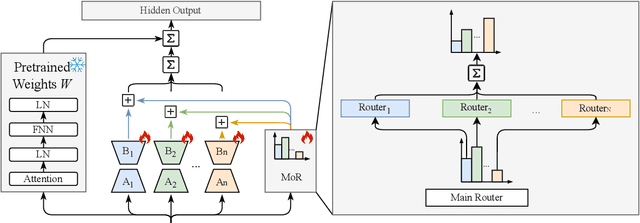
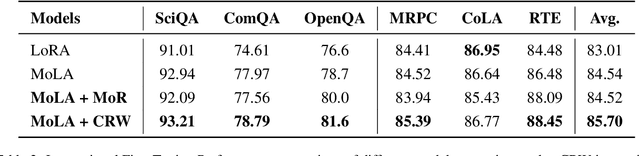
Supervised fine-tuning (SFT) is a milestone in aligning large language models with human instructions and adapting them to downstream tasks. In particular, Low-Rank Adaptation (LoRA) has gained widespread attention due to its parameter efficiency. However, its impact on improving the performance of large models remains limited. Recent studies suggest that combining LoRA with Mixture-of-Experts (MoE) can significantly enhance fine-tuning performance. MoE adapts to the diversity and complexity of datasets by dynamically selecting the most suitable experts, thereby improving task accuracy and efficiency. Despite impressive results, recent studies reveal issues in the MoE routing mechanism, such as incorrect assignments and imbalanced expert allocation. Inspired by the principles of Redundancy and Fault Tolerance Theory. We innovatively integrate the concept of Mixture of Experts into the routing mechanism and propose an efficient fine-tuning method called Mixture of Routers (MoR). It employs multiple sub-routers for joint selection and uses a learnable main router to determine the weights of the sub-routers. The results show that MoR outperforms baseline models on most tasks, achieving an average performance improvement of 1%. MoR can serve as a plug-and-play, parameter-efficient fine-tuning method suitable for a wide range of applications. Our code is available here: https://anonymous.4open.science/r/MoR-DFC6.
I2VControl: Disentangled and Unified Video Motion Synthesis Control
Nov 26, 2024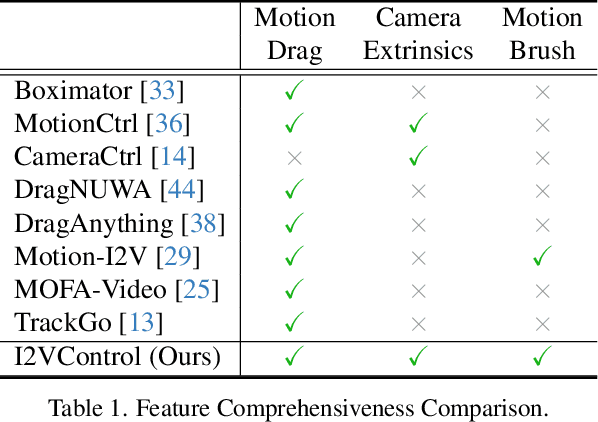
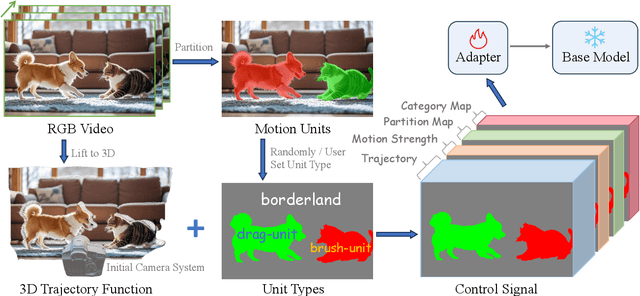
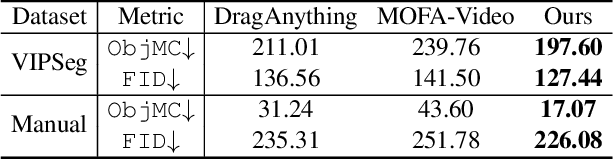

Video synthesis techniques are undergoing rapid progress, with controllability being a significant aspect of practical usability for end-users. Although text condition is an effective way to guide video synthesis, capturing the correct joint distribution between text descriptions and video motion remains a substantial challenge. In this paper, we present a disentangled and unified framework, namely I2VControl, that unifies multiple motion control tasks in image-to-video synthesis. Our approach partitions the video into individual motion units and represents each unit with disentangled control signals, which allows for various control types to be flexibly combined within our single system. Furthermore, our methodology seamlessly integrates as a plug-in for pre-trained models and remains agnostic to specific model architectures. We conduct extensive experiments, achieving excellent performance on various control tasks, and our method further facilitates user-driven creative combinations, enhancing innovation and creativity. The project page is: https://wanquanf.github.io/I2VControl .
WRHT: Efficient All-reduce for Distributed DNN Training in Optical Interconnect System
Jul 22, 2022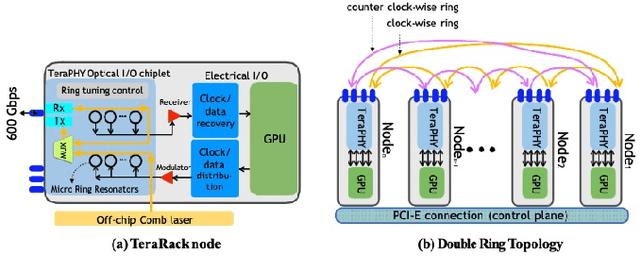
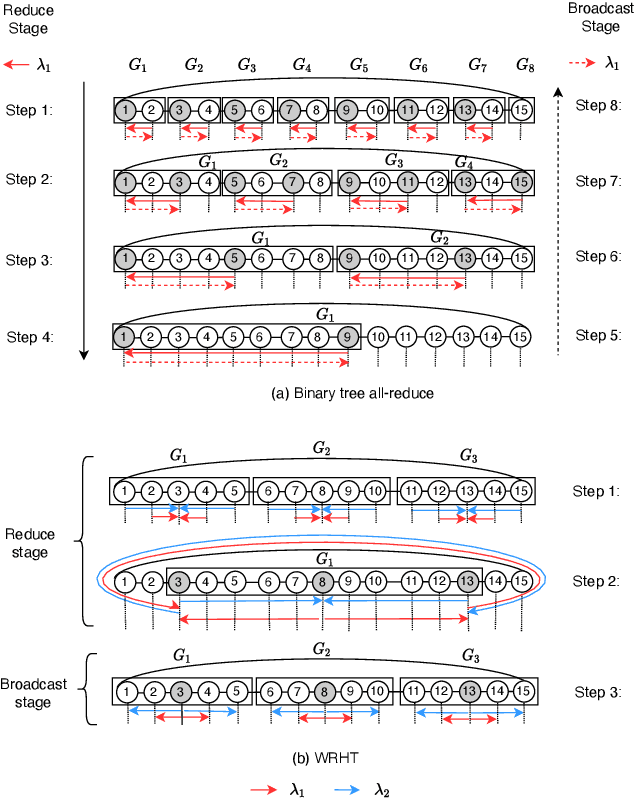
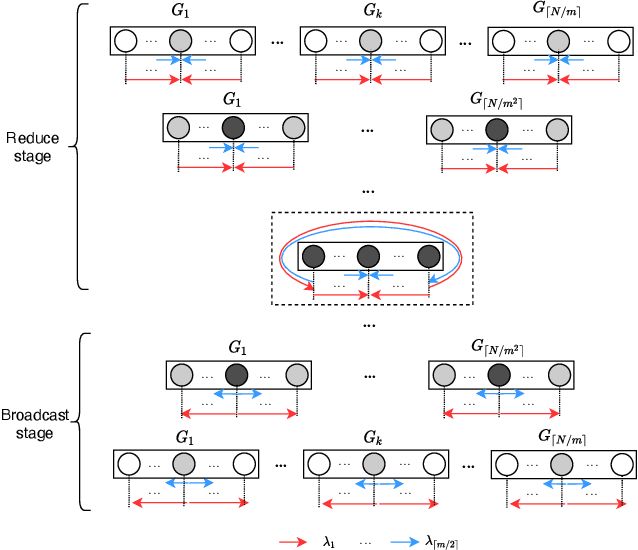
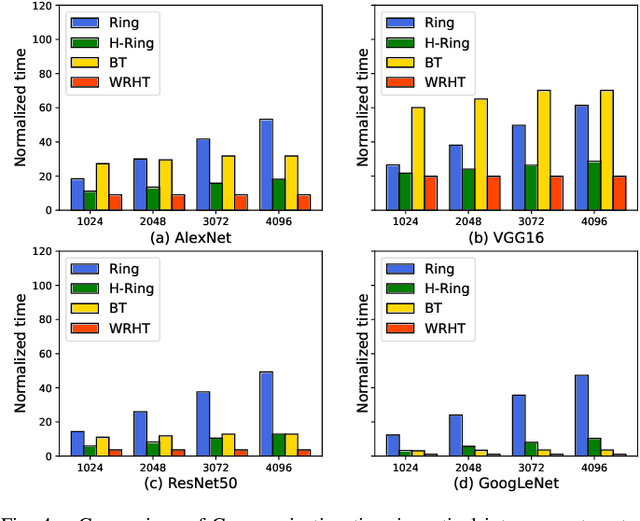
Communication efficiency plays an important role in accelerating the distributed training of Deep Neural Networks (DNN). All-reduce is the key communication primitive to reduce model parameters in distributed DNN training. Most existing all-reduce algorithms are designed for traditional electrical interconnect systems, which cannot meet the communication requirements for distributed training of large DNNs. One of the promising alternatives for electrical interconnect is optical interconnect, which can provide high bandwidth, low transmission delay, and low power cost. We propose an efficient scheme called WRHT (Wavelength Reused Hierarchical Tree) for implementing all-reduce operation in optical interconnect system, which can take advantage of WDM (Wavelength Division Multiplexing) to reduce the communication time of distributed data-parallel DNN training. We further derive the minimum number of communication steps and communication time to realize the all-reduce using WRHT. Simulation results show that the communication time of WRHT is reduced by 75.59%, 49.25%, and 70.1% respectively compared with three traditional all-reduce algorithms simulated in optical interconnect system. Simulation results also show that WRHT can reduce the communication time for all-reduce operation by 86.69% and 84.71% in comparison with two existing all-reduce algorithms in electrical interconnect system.
Accelerating Fully Connected Neural Network on Optical Network-on-Chip (ONoC)
Sep 30, 2021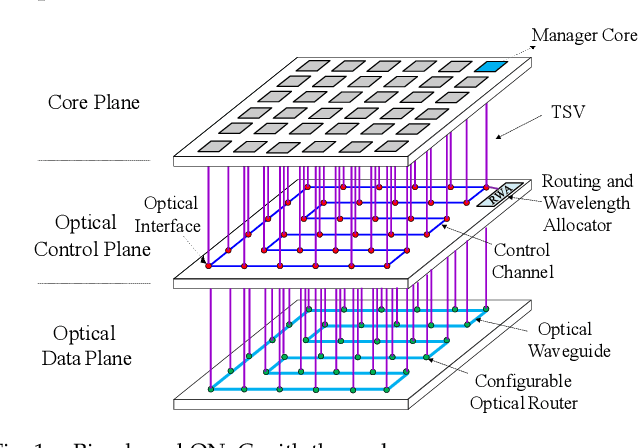

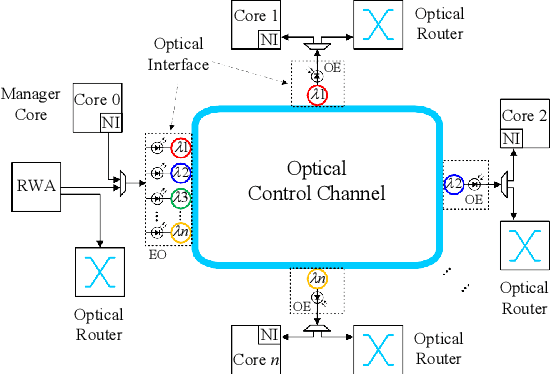
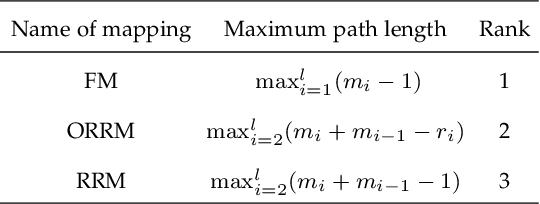
Fully Connected Neural Network (FCNN) is a class of Artificial Neural Networks widely used in computer science and engineering, whereas the training process can take a long time with large datasets in existing many-core systems. Optical Network-on-Chip (ONoC), an emerging chip-scale optical interconnection technology, has great potential to accelerate the training of FCNN with low transmission delay, low power consumption, and high throughput. However, existing methods based on Electrical Network-on-Chip (ENoC) cannot fit in ONoC because of the unique properties of ONoC. In this paper, we propose a fine-grained parallel computing model for accelerating FCNN training on ONoC and derive the optimal number of cores for each execution stage with the objective of minimizing the total amount of time to complete one epoch of FCNN training. To allocate the optimal number of cores for each execution stage, we present three mapping strategies and compare their advantages and disadvantages in terms of hotspot level, memory requirement, and state transitions. Simulation results show that the average prediction error for the optimal number of cores in NN benchmarks is within 2.3%. We further carry out extensive simulations which demonstrate that FCNN training time can be reduced by 22.28% and 4.91% on average using our proposed scheme, compared with traditional parallel computing methods that either allocate a fixed number of cores or allocate as many cores as possible, respectively. Compared with ENoC, simulation results show that under batch sizes of 64 and 128, on average ONoC can achieve 21.02% and 12.95% on reducing training time with 47.85% and 39.27% on saving energy, respectively.