 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavelet Mixture of Experts for Time Series Forecasting
Aug 12, 2025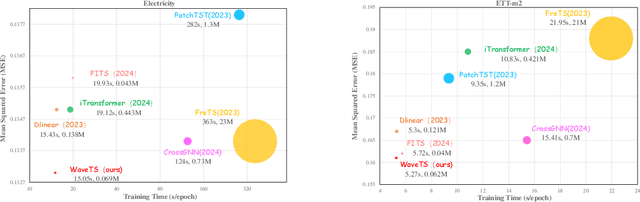
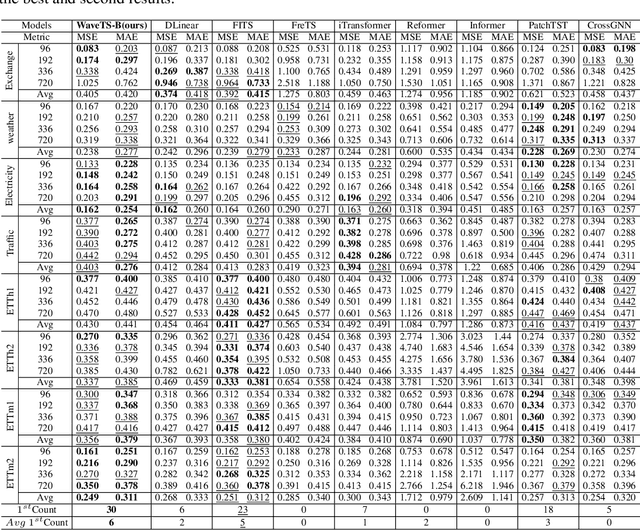
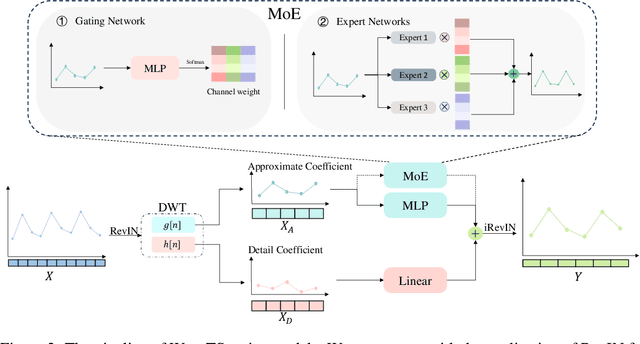
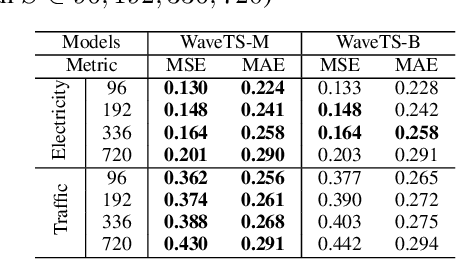
The field of time series forecasting is rapidly advancing, with recent large-scale Transformers and lightweight Multilayer Perceptron (MLP) models showing strong predictive performance. However, conventional Transformer models are often hindered by their large number of parameters and their limited ability to capture non-stationary features in data through smoothing. Similarly, MLP models struggle to manage multi-channel dependencies effectively. To address these limitations, we propose a novel, lightweight time series prediction model, WaveTS-B. This model combines wavelet transforms with MLP to capture both periodic and non-stationary characteristics of data in the wavelet domain. Building on this foundation, we propose a channel clustering strategy that incorporates a Mixture of Experts (MoE) framework, utilizing a gating mechanism and expert network to handle multi-channel dependencies efficiently. We propose WaveTS-M, an advanced model tailored for multi-channel time series prediction. Empirical evaluation across eight real-world time series datasets demonstrates that our WaveTS series models achieve state-of-the-art (SOTA) performance with significantly fewer parameters. Notably, WaveTS-M shows substantial improvements on multi-channel datasets, highlighting its effectiveness.
CausalDiffTab: Mixed-Type Causal-Aware Diffusion for Tabular Data Generation
Jun 17, 2025Training data has been proven to be one of the most critical components in training generative AI. However, obtaining high-quality data remains challenging, with data privacy issues presenting a significant hurdle. To address the need for high-quality data. Synthesize data has emerged as a mainstream solution, demonstrating impressive performance in areas such as images, audio, and video. Generating mixed-type data, especially high-quality tabular data, still faces significant challenges. These primarily include its inherent heterogeneous data types, complex inter-variable relationships, and intricate column-wise distributions. In this paper, we introduce CausalDiffTab, a diffusion model-based generative model specifically designed to handle mixed tabular data containing both numerical and categorical features, while being more flexible in capturing complex interactions among variables. We further propose a hybrid adaptive causal regularization method based on the principle of Hierarchical Prior Fusion. This approach adaptively controls the weight of causal regularization, enhancing the model's performance without compromising its generative capabilities. Comprehensive experiments conducted on seven datasets demonstrate that CausalDiffTab outperforms baseline methods across all metrics. Our code is publicly available at: https://github.com/Godz-z/CausalDiffTab.
Sugar-Coated Poison: Benign Generation Unlocks LLM Jailbreaking
Apr 08, 2025

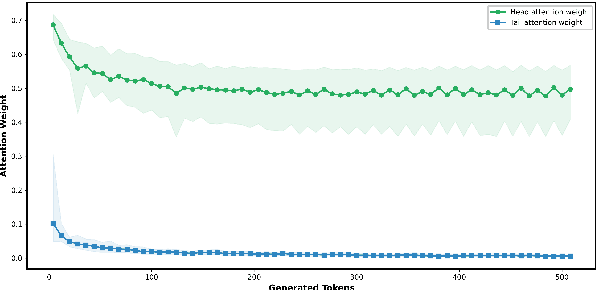

Large Language Models (LLMs) have become increasingly integral to a wide range of applications. However, they still remain the threat of jailbreak attacks, where attackers manipulate designed prompts to make the models elicit malicious outputs. Analyzing jailbreak methods can help us delve into the weakness of LLMs and improve it. In this paper, We reveal a vulnerability in large language models (LLMs), which we term Defense Threshold Decay (DTD), by analyzing the attention weights of the model's output on input and subsequent output on prior output: as the model generates substantial benign content, its attention weights shift from the input to prior output, making it more susceptible to jailbreak attacks. To demonstrate the exploitability of DTD, we propose a novel jailbreak attack method, Sugar-Coated Poison (SCP), which induces the model to generate substantial benign content through benign input and adversarial reasoning, subsequently producing malicious content. To mitigate such attacks, we introduce a simple yet effective defense strategy, POSD, which significantly reduces jailbreak success rates while preserving the model's generalization capabilities.
Mixture of Routers
Mar 30, 2025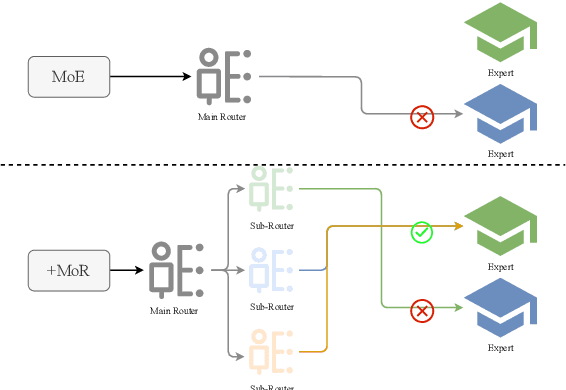
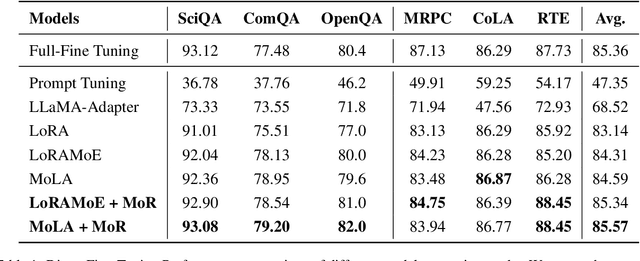
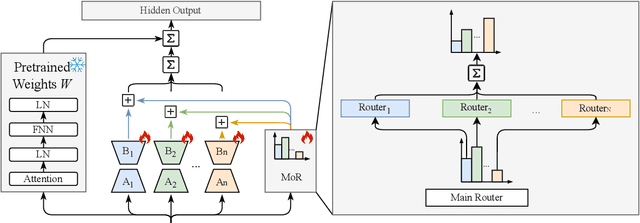
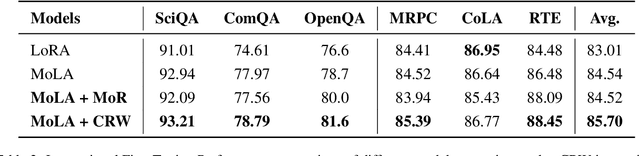
Supervised fine-tuning (SFT) is a milestone in aligning large language models with human instructions and adapting them to downstream tasks. In particular, Low-Rank Adaptation (LoRA) has gained widespread attention due to its parameter efficiency. However, its impact on improving the performance of large models remains limited. Recent studies suggest that combining LoRA with Mixture-of-Experts (MoE) can significantly enhance fine-tuning performance. MoE adapts to the diversity and complexity of datasets by dynamically selecting the most suitable experts, thereby improving task accuracy and efficiency. Despite impressive results, recent studies reveal issues in the MoE routing mechanism, such as incorrect assignments and imbalanced expert allocation. Inspired by the principles of Redundancy and Fault Tolerance Theory. We innovatively integrate the concept of Mixture of Experts into the routing mechanism and propose an efficient fine-tuning method called Mixture of Routers (MoR). It employs multiple sub-routers for joint selection and uses a learnable main router to determine the weights of the sub-routers. The results show that MoR outperforms baseline models on most tasks, achieving an average performance improvement of 1%. MoR can serve as a plug-and-play, parameter-efficient fine-tuning method suitable for a wide range of applications. Our code is available here: https://anonymous.4open.science/r/MoR-DFC6.
Understanding Before Reasoning: Enhancing Chain-of-Thought with Iterative Summarization Pre-Prompting
Jan 08, 2025Chain-of-Thought (CoT) Prompting is a dominant paradigm in Large Language Models (LLMs) to enhance complex reasoning. It guides LLMs to present multi-step reasoning, rather than generating the final answer directly. However, CoT encounters difficulties when key information required for reasoning is implicit or missing. This occurs because CoT emphasizes the sequence of reasoning steps while overlooking the early extraction of essential information. We propose a pre-prompting method called Iterative Summarization Pre-Prompting (ISP^2) to refine LLM reasoning when key information is not explicitly provided. First, entities and their corresponding descriptions are extracted to form potential key information pairs. Next, we use a reliability rating to assess these pairs, then merge the two lowest-ranked pairs into a new entity description. This process is repeated until a unique key information pair is obtained. Finally, that pair, along with the original question, is fed into LLMs to produce the answer. Extensive experiments demonstrate a 7.1% improvement compared to existing methods. Unlike traditional prompting, ISP^2 adopts an inductive approach with pre-prompting, offering flexible integration into diverse reasoning frameworks. The code is available at https://github.com/zdhgreat/ISP-2.
LoRA$^2$ : Multi-Scale Low-Rank Approximations for Fine-Tuning Large Language Models
Aug 13, 2024


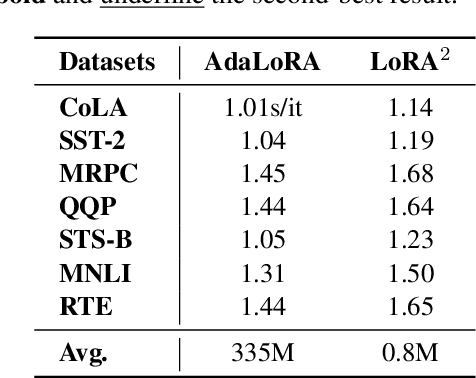
Fine-tuning large language models (LLMs) with high parameter efficiency for downstream tasks has become a new paradigm. Low-Rank Adaptation (LoRA) significantly reduces the number of trainable parameters for fine-tuning. Although it has demonstrated commendable performance, updating parameters within a single scale may not be the optimal choice for complex downstream tasks.In this paper, we extend the LoRA to multiple scales, dubbed as LoRA$^2$. We first combine orthogonal projection theory to train a set of LoRAs in two mutually orthogonal planes. Then, we improve the importance score algorithm, which reduce parameter sensitivity score calculations by approximately 98.5\%. By pruning singular values with lower importance scores, thereby enhancing adaptability to various downstream tasks. Extensive experiments are conducted on two widely used pre-trained models to validate the effectiveness of LoRA$^2$. Results show that it significantly reduces the number of trainable parameters to just 0.72\% compared to full fine-tuning, while still delivering highly impressive performance. Even when the parameters are further reduced to 0.17M, it still achieves comparable results to the baseline with 8 times more parameters. Our code is available here: https://anonymous.4open.science/r/LoRA-2-5B4C