 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Before Reasoning: Enhancing Chain-of-Thought with Iterative Summarization Pre-Prompting
Jan 08, 2025Chain-of-Thought (CoT) Prompting is a dominant paradigm in Large Language Models (LLMs) to enhance complex reasoning. It guides LLMs to present multi-step reasoning, rather than generating the final answer directly. However, CoT encounters difficulties when key information required for reasoning is implicit or missing. This occurs because CoT emphasizes the sequence of reasoning steps while overlooking the early extraction of essential information. We propose a pre-prompting method called Iterative Summarization Pre-Prompting (ISP^2) to refine LLM reasoning when key information is not explicitly provided. First, entities and their corresponding descriptions are extracted to form potential key information pairs. Next, we use a reliability rating to assess these pairs, then merge the two lowest-ranked pairs into a new entity description. This process is repeated until a unique key information pair is obtained. Finally, that pair, along with the original question, is fed into LLMs to produce the answer. Extensive experiments demonstrate a 7.1% improvement compared to existing methods. Unlike traditional prompting, ISP^2 adopts an inductive approach with pre-prompting, offering flexible integration into diverse reasoning frameworks. The code is available at https://github.com/zdhgreat/ISP-2.
LoRA$^2$ : Multi-Scale Low-Rank Approximations for Fine-Tuning Large Language Models
Aug 13, 2024


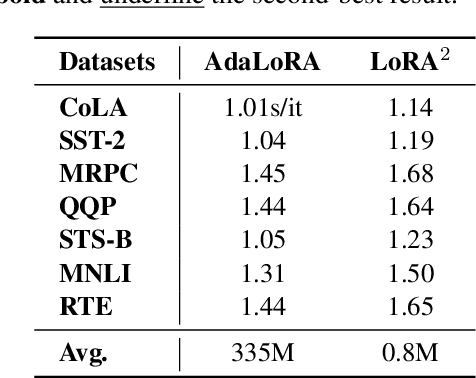
Fine-tuning large language models (LLMs) with high parameter efficiency for downstream tasks has become a new paradigm. Low-Rank Adaptation (LoRA) significantly reduces the number of trainable parameters for fine-tuning. Although it has demonstrated commendable performance, updating parameters within a single scale may not be the optimal choice for complex downstream tasks.In this paper, we extend the LoRA to multiple scales, dubbed as LoRA$^2$. We first combine orthogonal projection theory to train a set of LoRAs in two mutually orthogonal planes. Then, we improve the importance score algorithm, which reduce parameter sensitivity score calculations by approximately 98.5\%. By pruning singular values with lower importance scores, thereby enhancing adaptability to various downstream tasks. Extensive experiments are conducted on two widely used pre-trained models to validate the effectiveness of LoRA$^2$. Results show that it significantly reduces the number of trainable parameters to just 0.72\% compared to full fine-tuning, while still delivering highly impressive performance. Even when the parameters are further reduced to 0.17M, it still achieves comparable results to the baseline with 8 times more parameters. Our code is available here: https://anonymous.4open.science/r/LoRA-2-5B4C