 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Fully Connected Neural Network on Optical Network-on-Chip (ONoC)
Paper and Code
Sep 30, 2021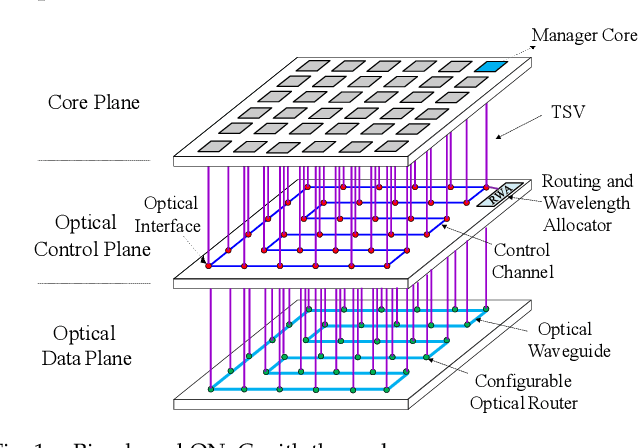

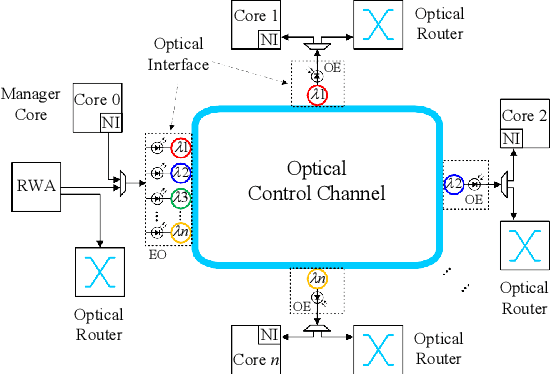
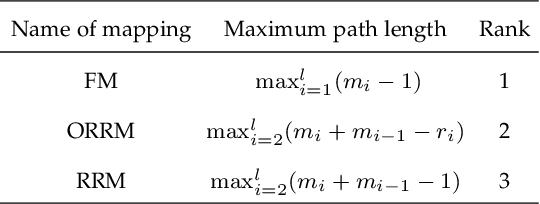
Fully Connected Neural Network (FCNN) is a class of Artificial Neural Networks widely used in computer science and engineering, whereas the training process can take a long time with large datasets in existing many-core systems. Optical Network-on-Chip (ONoC), an emerging chip-scale optical interconnection technology, has great potential to accelerate the training of FCNN with low transmission delay, low power consumption, and high throughput. However, existing methods based on Electrical Network-on-Chip (ENoC) cannot fit in ONoC because of the unique properties of ONoC. In this paper, we propose a fine-grained parallel computing model for accelerating FCNN training on ONoC and derive the optimal number of cores for each execution stage with the objective of minimizing the total amount of time to complete one epoch of FCNN training. To allocate the optimal number of cores for each execution stage, we present three mapping strategies and compare their advantages and disadvantages in terms of hotspot level, memory requirement, and state transitions. Simulation results show that the average prediction error for the optimal number of cores in NN benchmarks is within 2.3%. We further carry out extensive simulations which demonstrate that FCNN training time can be reduced by 22.28% and 4.91% on average using our proposed scheme, compared with traditional parallel computing methods that either allocate a fixed number of cores or allocate as many cores as possible, respectively. Compared with ENoC, simulation results show that under batch sizes of 64 and 128, on average ONoC can achieve 21.02% and 12.95% on reducing training time with 47.85% and 39.27% on saving energy, respectively.