 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning-Driven Student Performance Prediction for Enhancing Tiered Instruction
Feb 05, 2025



Student performance prediction is one of the most important subjects in educational data mining. As a modern technology, machine learning offers powerful capabilities in feature extraction and data modeling, providing essential support for diverse application scenarios, as evidenced by recent studies confirming its effectiveness in educational data mining. However, despite extensive prediction experiments, machine learning methods have not been effectively integrated into practical teaching strategies, hindering their application in modern education. In addition, massive features as input variables for machine learning algorithms often leads to information redundancy, which can negatively impact prediction accuracy. Therefore, how to effectively use machine learning methods to predict student performance and integrate the prediction results with actual teaching scenarios is a worthy research subject. To this end, this study integrates the results of machine learning-based student performance prediction with tiered instruction, aiming to enhance student outcomes in target course, which is significant for the application of educational data mining in contemporary teaching scenarios. Specifically, we collect original educational data and perform feature selection to reduce information redundancy. Then, the performance of five representative machine learning methods is analyzed and discussed with Random Forest showing the best performance. Furthermore, based on the results of the classification of students, tiered instruction is applied accordingly, and different teaching objectives and contents are set for all levels of students. The comparison of teaching outcomes between the control and experimental classes, along with the analysis of questionnaire results, demonstrates the effectiveness of the proposed framework.
Concept-Aware Latent and Explicit Knowledge Integration for Enhanced Cognitive Diagnosis
Feb 04, 2025



Cognitive diagnosis can infer the students' mastery of specific knowledge concepts based on historical response logs. However, the existing cognitive diagnostic models (CDMs) represent students' proficiency via a unidimensional perspective, which can't assess the students' mastery on each knowledge concept comprehensively. Moreover, the Q-matrix binarizes the relationship between exercises and knowledge concepts, and it can't represent the latent relationship between exercises and knowledge concepts. Especially, when the granularity of knowledge attributes refines increasingly, the Q-matrix becomes incomplete correspondingly and the sparse binary representation (0/1) fails to capture the intricate relationships among knowledge concepts. To address these issues, we propose a Concept-aware Latent and Explicit Knowledge Integration model for cognitive diagnosis (CLEKI-CD). Specifically, a multidimensional vector is constructed according to the students' mastery and exercise difficulty for each knowledge concept from multiple perspectives, which enhances the representation capabilities of the model. Moreover, a latent Q-matrix is generated by our proposed attention-based knowledge aggregation method, and it can uncover the coverage degree of exercises over latent knowledge. The latent Q-matrix can supplement the sparse explicit Q-matrix with the inherent relationships among knowledge concepts, and mitigate the knowledge coverage problem. Furthermore, we employ a combined cognitive diagnosis layer to integrate both latent and explicit knowledge, further enhancing cognitive diagnosis performance. Extensive experiments on real-world datasets demonstrate that CLEKI-CD outperforms the state-of-the-art models. The proposed CLEKI-CD is promising in practical applications in the field of intelligent education, as it exhibits good interpretability with diagnostic results.
WRHT: Efficient All-reduce for Distributed DNN Training in Optical Interconnect System
Jul 22, 2022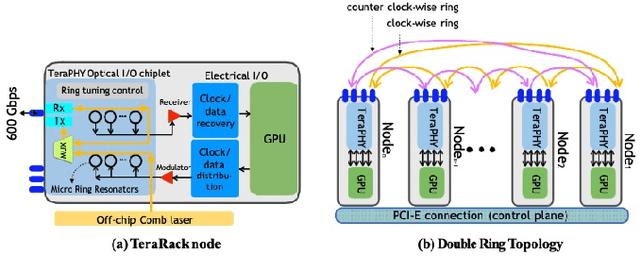
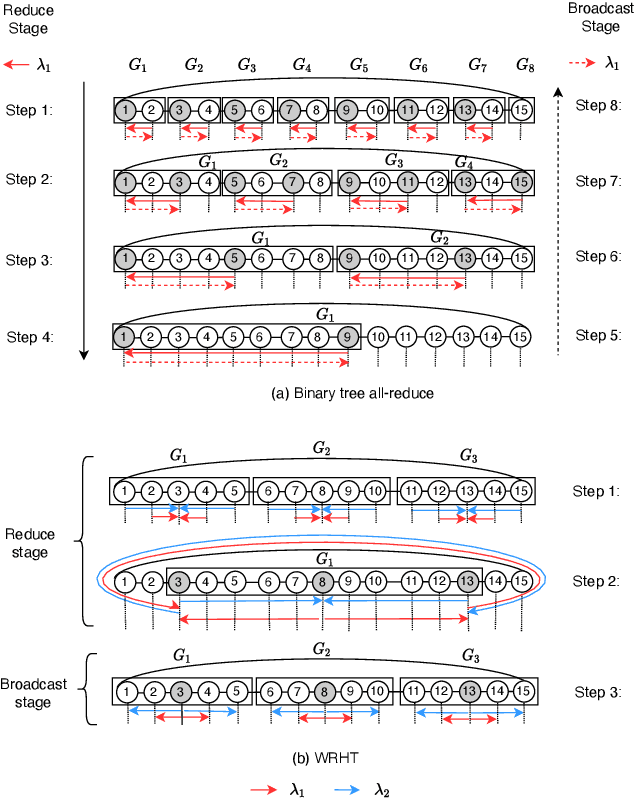
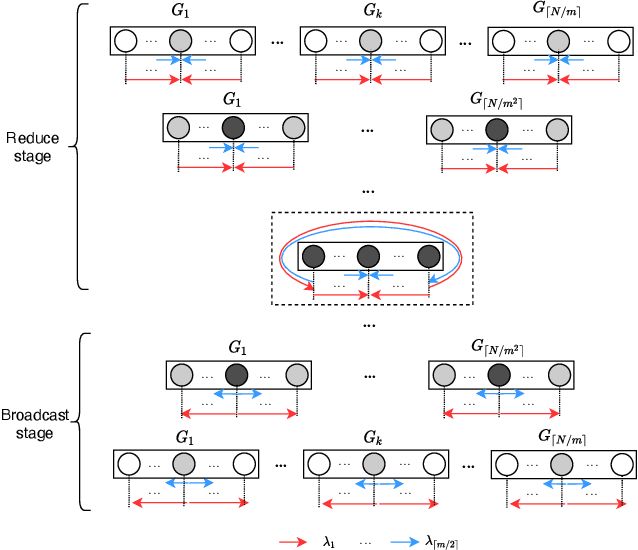
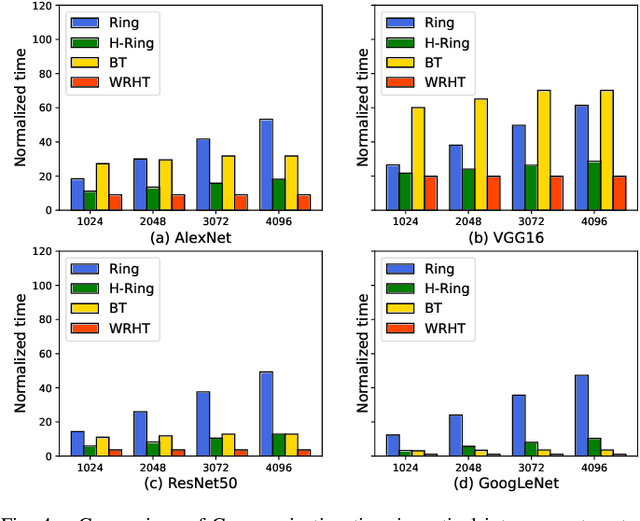
Communication efficiency plays an important role in accelerating the distributed training of Deep Neural Networks (DNN). All-reduce is the key communication primitive to reduce model parameters in distributed DNN training. Most existing all-reduce algorithms are designed for traditional electrical interconnect systems, which cannot meet the communication requirements for distributed training of large DNNs. One of the promising alternatives for electrical interconnect is optical interconnect, which can provide high bandwidth, low transmission delay, and low power cost. We propose an efficient scheme called WRHT (Wavelength Reused Hierarchical Tree) for implementing all-reduce operation in optical interconnect system, which can take advantage of WDM (Wavelength Division Multiplexing) to reduce the communication time of distributed data-parallel DNN training. We further derive the minimum number of communication steps and communication time to realize the all-reduce using WRHT. Simulation results show that the communication time of WRHT is reduced by 75.59%, 49.25%, and 70.1% respectively compared with three traditional all-reduce algorithms simulated in optical interconnect system. Simulation results also show that WRHT can reduce the communication time for all-reduce operation by 86.69% and 84.71% in comparison with two existing all-reduce algorithms in electrical interconnect system.
Accelerating Fully Connected Neural Network on Optical Network-on-Chip (ONoC)
Sep 30, 2021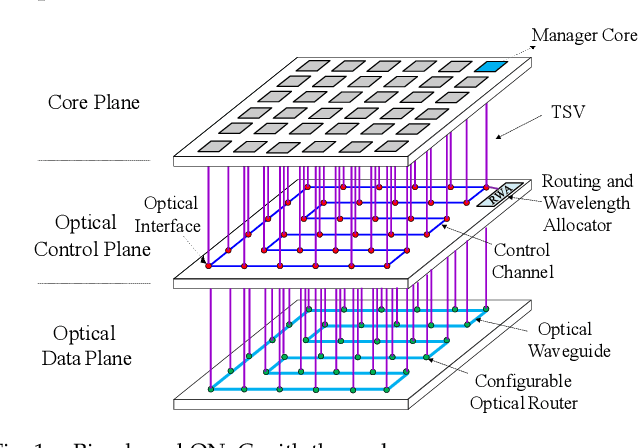

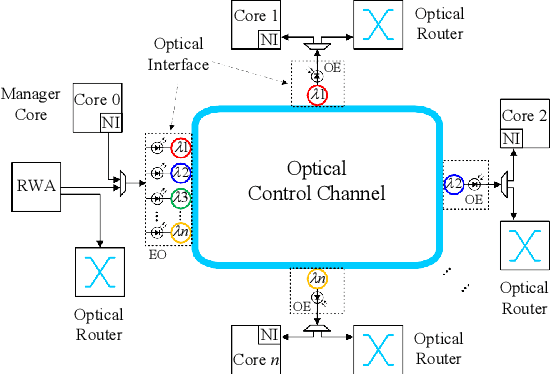
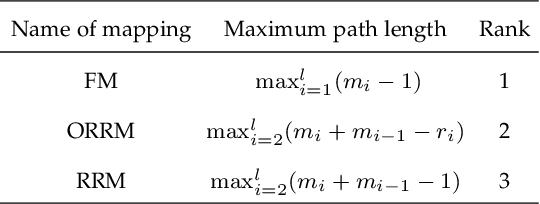
Fully Connected Neural Network (FCNN) is a class of Artificial Neural Networks widely used in computer science and engineering, whereas the training process can take a long time with large datasets in existing many-core systems. Optical Network-on-Chip (ONoC), an emerging chip-scale optical interconnection technology, has great potential to accelerate the training of FCNN with low transmission delay, low power consumption, and high throughput. However, existing methods based on Electrical Network-on-Chip (ENoC) cannot fit in ONoC because of the unique properties of ONoC. In this paper, we propose a fine-grained parallel computing model for accelerating FCNN training on ONoC and derive the optimal number of cores for each execution stage with the objective of minimizing the total amount of time to complete one epoch of FCNN training. To allocate the optimal number of cores for each execution stage, we present three mapping strategies and compare their advantages and disadvantages in terms of hotspot level, memory requirement, and state transitions. Simulation results show that the average prediction error for the optimal number of cores in NN benchmarks is within 2.3%. We further carry out extensive simulations which demonstrate that FCNN training time can be reduced by 22.28% and 4.91% on average using our proposed scheme, compared with traditional parallel computing methods that either allocate a fixed number of cores or allocate as many cores as possible, respectively. Compared with ENoC, simulation results show that under batch sizes of 64 and 128, on average ONoC can achieve 21.02% and 12.95% on reducing training time with 47.85% and 39.27% on saving energy, respectively.
Upper Extremity Load Reduction for Lower LimbExoskeleton Trajectory Generation Using AnkleTorque Minimization
Nov 09, 2020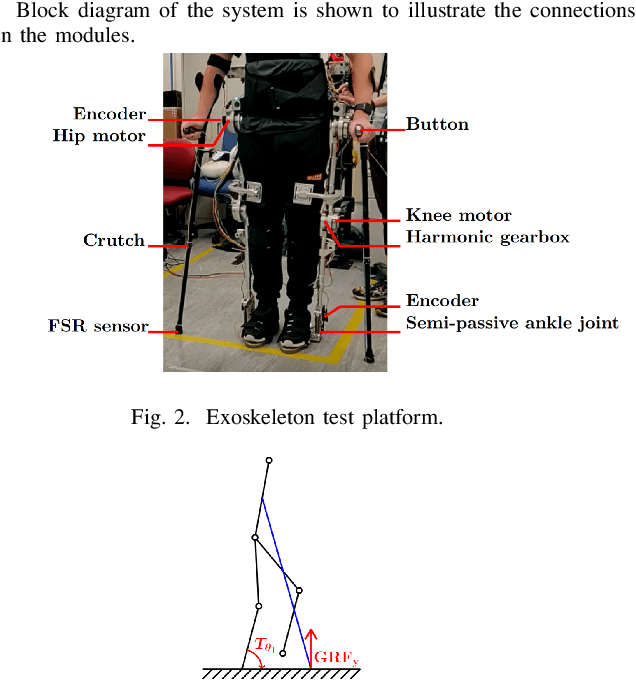
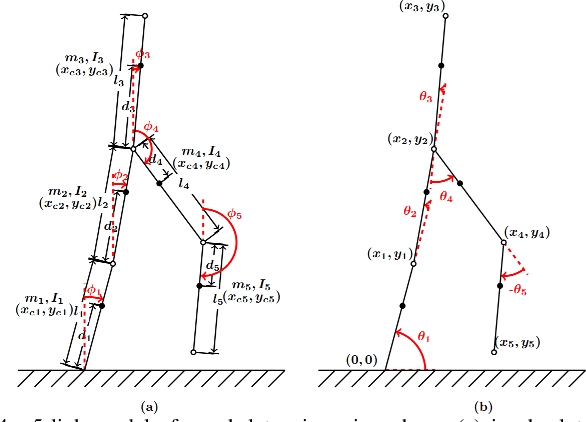
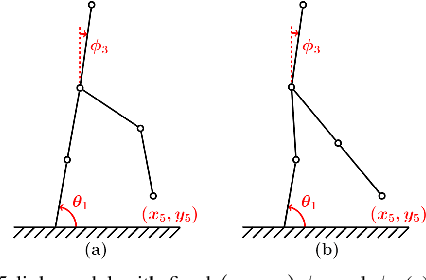
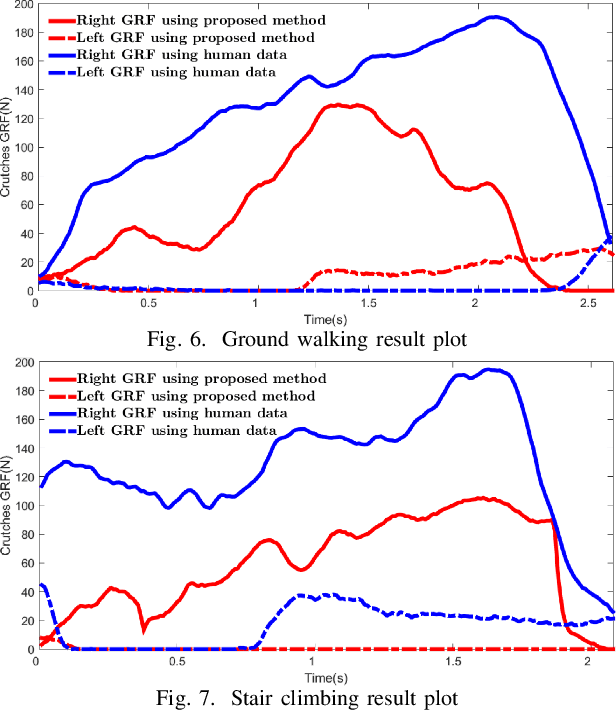
Recently, the lower limb exoskeletons which providemobility for paraplegic patients to support their daily life havedrawn much attention. However, the pilots are required to applyexcessive force through a pair of crutches to maintain balanceduring walking. This paper proposes a novel gait trajectorygeneration algorithm for exoskeleton locomotion on flat groundand stair which aims to minimize the force applied by the pilotwithout increasing the degree of freedom (DoF) of the system.First, the system is modelled as a five-link mechanism dynam-ically for torque computing. Then, an optimization approachis used to generate the trajectory minimizing the ankle torquewhich is correlated to the supporting force. Finally, experimentis conducted to compare the different gait generation algorithmsthrough measurement of ground reaction force (GRF) appliedon the crutches
Variable Stiffness Control with Strict Frequency Domain Constraints for Physical Human-Robot Interaction
Aug 09, 2020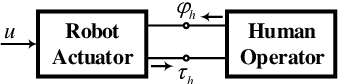
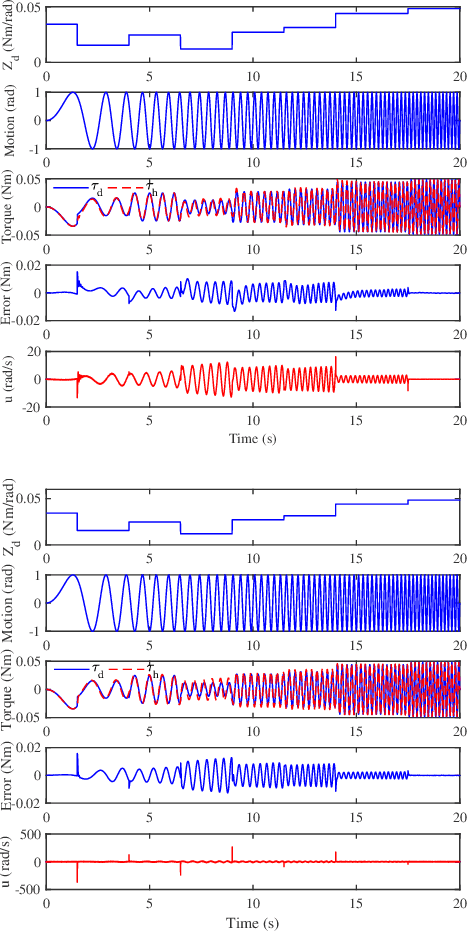
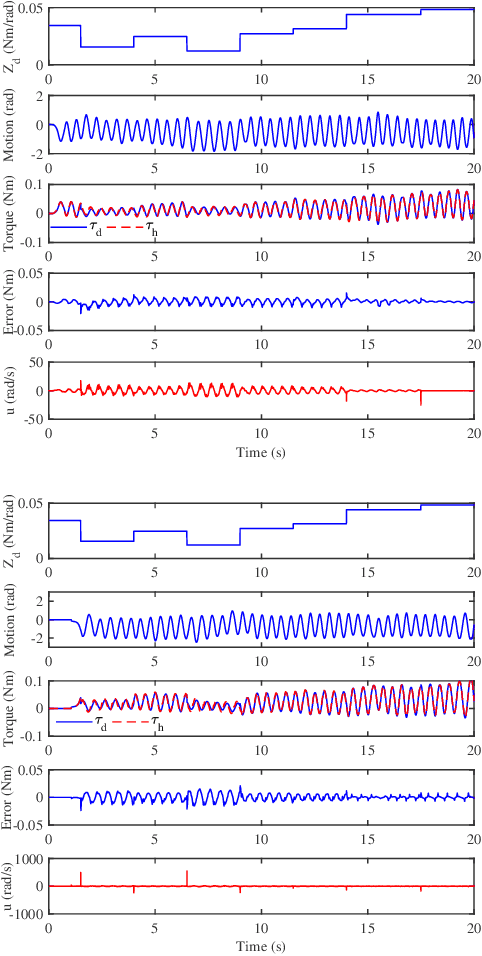

Variable impedance control is advantageous for physical human-robot interaction to improve safety, adaptability and many other aspects. This paper presents a gain-scheduled variable stiffness control approach under strict frequency-domain constraints. Firstly, to reduce conservativeness, we characterize and constrain the impedance rendering, actuator saturation, disturbance/noise rejection and passivity requirements into their specific frequency bands. This relaxation makes sense because of the restricted frequency properties of the interactive robots. Secondly, a gain-scheduled method is taken to regulate the controller gains with respect to the desired stiffness. Thirdly, the scheduling function is parameterized via a nonsmooth optimization method. Finally, the proposed approach is validated by simulations, experiments and comparisons with a gain-fixed passivity-based PID method.
* 6 pages, accepted by IROS2020
Improving Efficiency of SVM k-fold Cross-validation by Alpha Seeding
Feb 04, 2017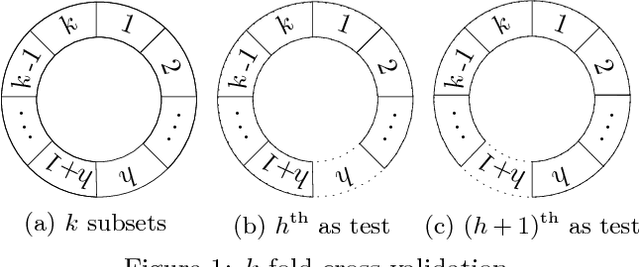

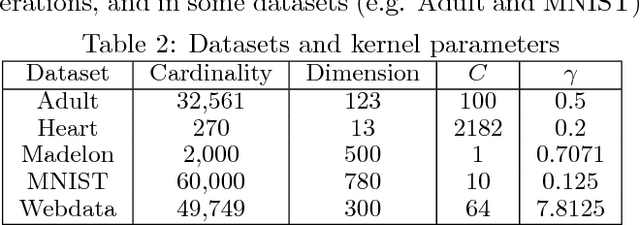
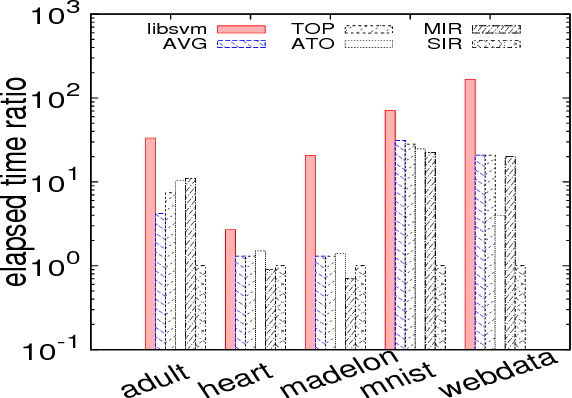
The k-fold cross-validation is commonly used to evaluate the effectiveness of SVMs with the selected hyper-parameters. It is known that the SVM k-fold cross-validation is expensive, since it requires training k SVMs. However, little work has explored reusing the h-th SVM for training the (h+1)-th SVM for improving the efficiency of k-fold cross-validation. In this paper, we propose three algorithms that reuse the h-th SVM for improving the efficiency of training the (h+1)-th SVM. Our key idea is to efficiently identify the support vectors and to accurately estimate their associated weights (also called alpha values) of the next SVM by using the previous SVM. Our experimental results show that our algorithms are several times faster than the k-fold cross-validation which does not make use of the previously trained SVM. Moreover, our algorithms produce the same results (hence same accuracy) as the k-fold cross-validation which does not make use of the previously trained SVM.