 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Efficiency of SVM k-fold Cross-validation by Alpha Seeding
Paper and Code
Feb 04, 2017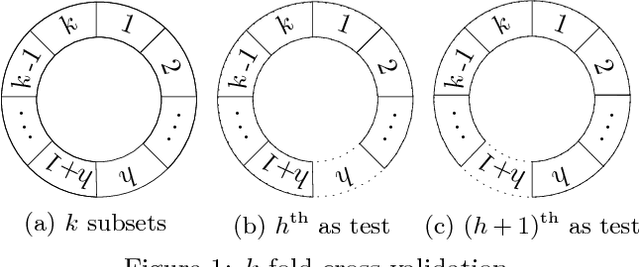

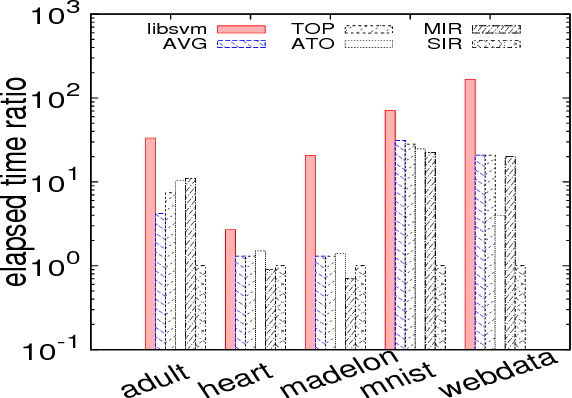
The k-fold cross-validation is commonly used to evaluate the effectiveness of SVMs with the selected hyper-parameters. It is known that the SVM k-fold cross-validation is expensive, since it requires training k SVMs. However, little work has explored reusing the h-th SVM for training the (h+1)-th SVM for improving the efficiency of k-fold cross-validation. In this paper, we propose three algorithms that reuse the h-th SVM for improving the efficiency of training the (h+1)-th SVM. Our key idea is to efficiently identify the support vectors and to accurately estimate their associated weights (also called alpha values) of the next SVM by using the previous SVM. Our experimental results show that our algorithms are several times faster than the k-fold cross-validation which does not make use of the previously trained SVM. Moreover, our algorithms produce the same results (hence same accuracy) as the k-fold cross-validation which does not make use of the previously trained SVM.