 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserving Data Privacy in Learning Causal Structure with Fully Homomorphic Encryption
Jun 03, 2026Preserving data privacy is an important topic in structural data management and data mining. However, the issue of privacy leakage in distributed causal structure learning is a persistent challenge, especially in cases where data transmission and computation are required. In this paper, we propose a method based on fully homomorphic encryption (FHE) that performs calculations on ciphertexts, keeping data encrypted in transition and computation. Nevertheless, adopting FHE to causal structure learning is challenging due to the high computation cost and limited support on division as well as logarithm operations in FHE. To tackle this challenge, we propose a series of novel techniques including (i) circuit simplification for better efficiency, (ii) approximation of division and logarithm through Newton-Raphson Reciprocal and Taylor expansion, and (iii) a batching technique with SIMD-acceleration to enhance the whole learning process. Additionally, our method can be easily extended beyond FHE by demonstration of its portability to support differential privacy. Empirical results show that our method achieves high consistency and comparable causal structure with the plaintext version in the datasets tested. Last, our method is efficient and practical to complete learning causal structures in tens of minutes even under the privacy protection of FHE.
Efficient Hyperparameter Optimization for LLM Reinforcement Learning
Jun 02, 2026Reinforcement learning (RL) for large language models (LLMs) is highly sensitive to hyperparameter configurations, making hyperparameter optimization (HPO) essential yet computationally expensive. Existing multi-fidelity HPO methods remain inefficient for LLM RL due to the massive model scale and resource-intensive training cycles. In this paper, we propose Joint Fidelity Hyperparameter Optimization (JF-HPO), which simultaneously adapts both model size and training budget as fidelity. JF-HPO is empowered by: (i) it leverages a small proxy model of the target LLM for efficient training and evaluation in each HPO trial; (ii) it integrates carefully designed early-stopping strategies based on training dynamics; (iii) it introduces an efficient checkpointing mechanism to eliminate redundant computations. Compared with existing HPO methods, JF-HPO significantly improves the computational efficiency of each trial (up to 14.9 times), while achieving better or competitive predictive accuracy under the same time budget. Notably, compared with utilizing hyperparameter configurations from the VeRL Recipe, JF-HPO delivers performance improvements ranging from 5.8% to 111.6%.
EntSQL: A Benchmark for Grounding Text-to-SQL in Long-Context Enterprise Knowledge
Jun 02, 2026Text-to-SQL enables natural language access to databases, and recent LLMs have substantially advanced its capabilities. Existing benchmarks such as Spider, BIRD, and Spider~2.0 evaluate schema generalization, large-scale databases, and realistic workflows, but largely overlook enterprise scenarios where SQL generation depends on private business knowledge, such as internal metrics, reporting conventions, and organizational rules. We introduce EntSQL, an enterprise-oriented Text-to-SQL benchmark for evaluating long-context grounding over proprietary business documents. EntSQL contains 1,066 aligned Chinese-English semantic examples across five business domains, with most examples requiring domain knowledge beyond the question and schema and involving complex SQL structures. On English inputs, the best evaluated system reaches only 15.9\% when long-form documents are provided, highlighting the difficulty of grounding SQL generation in enterprise knowledge.
Enhancing Online Recruitment with Category-Aware MoE and LLM-based Data Augmentation
Apr 23, 2026Person-Job Fit (PJF) is a critical component for online recruitment. Existing approaches face several challenges, particularly in handling low-quality job descriptions and similar candidate-job pairs, which impair model performance. To address these challenges, this paper proposes a large language model (LLM) based method with two novel techniques: (1) LLM-based data augmentation, which polishes and rewrites low-quality job descriptions by leveraging chain-of-thought (COT) prompts, and (2) category-aware Mixture of Experts (MoE) that assists in identifying similar candidate-job pairs. This MoE module incorporates category embeddings to dynamically assign weights to the experts and learns more distinguishable patterns for similar candidate-job pairs. We perform offline evaluations and online A/B tests on our recruitment platform. Our method relatively surpasses existing methods by 2.40% in AUC and 7.46% in GAUC, and boosts click-through conversion rate (CTCVR) by 19.4% in online tests, saving millions of CNY in external headhunting expenses.
DeInfer: Efficient Parallel Inferencing for Decomposed Large Language Models
Apr 20, 2026Existing works on large language model (LLM) decomposition mainly focus on improving performance on downstream tasks, but they ignore the poor parallel inference performance when trying to scale up the model size. To mitigate this important performance issue, this paper introduces DeInfer, a high-performance inference system dedicated to parallel inference of decomposed LLMs. It consists of multiple optimizations to maximize performance and be compatible with state-of-the-art optimization techniques. Extensive experiments are carried out to evaluate DeInfer's performance, where the results demonstrate its superiority, suggesting it can greatly facilitate the parallel inference of decomposed LLMs.
An Efficient Heterogeneous Co-Design for Fine-Tuning on a Single GPU
Mar 17, 2026Fine-tuning Large Language Models (LLMs) has become essential for domain adaptation, but its memory-intensive property exceeds the capabilities of most GPUs. To address this challenge and democratize LLM fine-tuning, we present SlideFormer, a novel system designed for single-GPU environments. Our innovations are: (1) A lightweight asynchronous engine that treats the GPU as a sliding window and overlaps GPU computation with CPU updates and multi-tier I/O. (2) A highly efficient heterogeneous memory management scheme significantly reduces peak memory usage. (3) Optimized Triton kernels to solve key bottlenecks and integrated advanced I/O. This collaborative design enables fine-tuning of the latest 123B+ models on a single RTX 4090, supporting up to 8x larger batch sizes and 6x larger models. In evaluations, SlideFormer achieves 1.40x to 6.27x higher throughput while roughly halving CPU/GPU memory usage compared to baselines, sustaining >95% peak performance on both NVIDIA and AMD GPUs.
Quasar: Quantized Self-Speculative Acceleration for Rapid Inference via Memory-Efficient Verification
Mar 02, 2026Speculative Decoding (SD) has emerged as a premier technique for accelerating Large Language Model (LLM) inference by decoupling token generation into rapid drafting and parallel verification. While recent advancements in self-speculation and lookahead decoding have successfully minimized drafting overhead, they have shifted the primary performance bottleneck to the verification phase. Since verification requires a full forward pass of the target model, it remains strictly memory-bandwidth bound, fundamentally limiting the maximum achievable speedup.In this paper, we introduce \textbf{Quasar} (\textbf{Qua}ntized \textbf{S}elf-speculative \textbf{A}cceleration for \textbf{R}apid Inference), a novel, training-free framework designed to overcome this "memory wall" by employing low-bit quantization specifically for the verification stage. Our empirical analysis reveals that while aggressive structural pruning significantly degrades verification accuracy, quantization-based verification preserves the logit distribution with high fidelity while effectively halving memory traffic. Extensive experiments on state-of-the-art models (e.g., OpenPangu and Qwen3) demonstrate that Quasar maintains a speculative acceptance length comparable to full-precision methods while achieving a $1.28\times$ improvement in end-to-end throughput. Being orthogonal to existing drafting strategies, Quasar offers a generic and efficient pathway to accelerate the verification leg of speculative execution. Code is available at https://github.com/Tom-HG/Quasar.
Taxon: Hierarchical Tax Code Prediction with Semantically Aligned LLM Expert Guidance
Jan 13, 2026Tax code prediction is a crucial yet underexplored task in automating invoicing and compliance management for large-scale e-commerce platforms. Each product must be accurately mapped to a node within a multi-level taxonomic hierarchy defined by national standards, where errors lead to financial inconsistencies and regulatory risks. This paper presents Taxon, a semantically aligned and expert-guided framework for hierarchical tax code prediction. Taxon integrates (i) a feature-gating mixture-of-experts architecture that adaptively routes multi-modal features across taxonomy levels, and (ii) a semantic consistency model distilled from large language models acting as domain experts to verify alignment between product titles and official tax definitions. To address noisy supervision in real business records, we design a multi-source training pipeline that combines curated tax databases, invoice validation logs, and merchant registration data to provide both structural and semantic supervision. Extensive experiments on the proprietary TaxCode dataset and public benchmarks demonstrate that Taxon achieves state-of-the-art performance, outperforming strong baselines. Further, an additional full hierarchical paths reconstruction procedure significantly improves structural consistency, yielding the highest overall F1 scores. Taxon has been deployed in production within Alibaba's tax service system, handling an average of over 500,000 tax code queries per day and reaching peak volumes above five million requests during business event with improved accuracy, interpretability, and robustness.
SEAL: Structure and Element Aware Learning to Improve Long Structured Document Retrieval
Aug 28, 2025



In long structured document retrieval, existing methods typically fine-tune pre-trained language models (PLMs) using contrastive learning on datasets lacking explicit structural information. This practice suffers from two critical issues: 1) current methods fail to leverage structural features and element-level semantics effectively, and 2) the lack of datasets containing structural metadata. To bridge these gaps, we propose \our, a novel contrastive learning framework. It leverages structure-aware learning to preserve semantic hierarchies and masked element alignment for fine-grained semantic discrimination. Furthermore, we release \dataset, a long structured document retrieval dataset with rich structural annotations. Extensive experiments on both released and industrial datasets across various modern PLMs, along with online A/B testing, demonstrate consistent performance improvements, boosting NDCG@10 from 73.96\% to 77.84\% on BGE-M3. The resources are available at https://github.com/xinhaoH/SEAL.
Fast-PGM: Fast Probabilistic Graphical Model Learning and Inference
May 28, 2024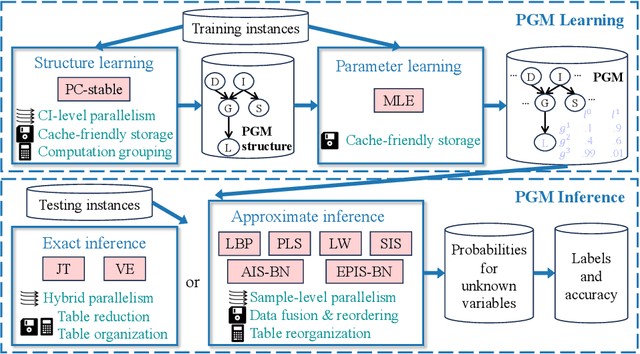
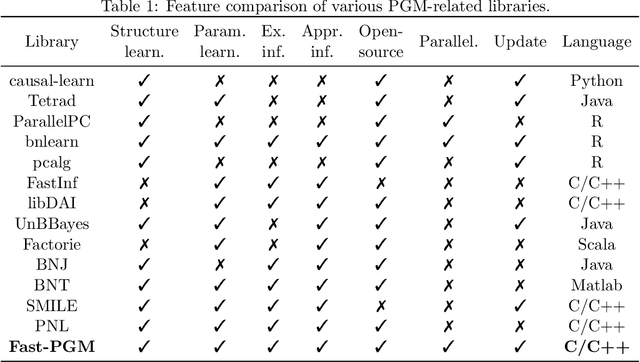
Probabilistic graphical models (PGMs) serve as a powerful framework for modeling complex systems with uncertainty and extracting valuable insights from data. However, users face challenges when applying PGMs to their problems in terms of efficiency and usability. This paper presents Fast-PGM, an efficient and open-source library for PGM learning and inference. Fast-PGM supports comprehensive tasks on PGMs, including structure and parameter learning, as well as exact and approximate inference, and enhances efficiency of the tasks through computational and memory optimizations and parallelization techniques. Concurrently, Fast-PGM furnishes developers with flexible building blocks, furnishes learners with detailed documentation, and affords non-experts user-friendly interfaces, thereby ameliorating the usability of PGMs to users across a spectrum of expertise levels. The source code of Fast-PGM is available at https://github.com/jjiantong/FastPGM.