 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMBD: A Model-Based Debiasing Framework Across User, Content, and Model Dimensions
Mar 15, 2026Modern recommendation systems rank candidates by aggregating multiple behavioral signals through a value model. However, many commonly used signals are inherently affected by heterogeneous biases. For example, watch time naturally favors long-form content, loop rate favors short - form content, and comment probability favors videos over images. Such biases introduce two critical issues: (1) value model scores may be systematically misaligned with users' relative preferences - for instance, a seemingly low absolute like probability may represent exceptionally strong interest for a user who rarely engages; and (2) changes in value modeling rules can trigger abrupt and undesirable ecosystem shifts. In this work, we ask a fundamental question: can biased behavioral signals be systematically transformed into unbiased signals, under a user - defined notion of ``unbiasedness'', that are both personalized and adaptive? We propose a general, model-based debiasing (MBD) framework that addresses this challenge by augmenting it with distributional modeling. By conditioning on a flexible subset of features (partial feature set), we explicitly estimate the contextual mean and variance of the engagement distribution for arbitrary cohorts (e.g., specific video lengths or user regions) directly alongside the main prediction. This integration allows the framework to convert biased raw signals into unbiased representations, enabling the construction of higher-level, calibrated signals (such as percentiles or z - scores) suitable for the value model. Importantly, the definition of unbiasedness is flexible and controllable, allowing the system to adapt to different personalization objectives and modeling preferences. Crucially, this is implemented as a lightweight, built-in branch of the existing MTML ranking model, requiring no separate serving infrastructure.
Towards Terrain-Aware Safe Locomotion for Quadrupedal Robots Using Proprioceptive Sensing
Mar 10, 2026Achieving safe quadrupedal locomotion in real-world environments has attracted much attention in recent years. When walking over uneven terrain, achieving reliable estimation and realising safety-critical control based on the obtained information is still an open question. To address this challenge, especially for low-cost robots equipped solely with proprioceptive sensors (e.g., IMUs, joint encoders, and contact force sensors), this work first presents an estimation framework that generates a 2.5-D terrain map and extracts support plane parameters, which are then integrated into contact and state estimation. Then, we integrate this estimation framework into a safety-critical control pipeline by formulating control barrier functions that provide rigorous safety guarantees. Experiments demonstrate that the proposed terrain estimation method provides smooth terrain representations. Moreover, the coupled estimation framework of terrain, state, and contact reduces the mean absolute error of base position estimation by 64.8%, decreases the estimation variance by 47.2%, and improves the robustness of contact estimation compared to a decoupled framework. The terrain-informed CBFs integrate historical terrain information and current proprioceptive measurements to ensure global safety by keeping the robot out of hazardous areas and local safety by preventing body-terrain collision, relying solely on proprioceptive sensing.
Versatile, Robust, and Explosive Locomotion with Rigid and Articulated Compliant Quadrupeds
Apr 17, 2025Achieving versatile and explosive motion with robustness against dynamic uncertainties is a challenging task. Introducing parallel compliance in quadrupedal design is deemed to enhance locomotion performance, which, however, makes the control task even harder. This work aims to address this challenge by proposing a general template model and establishing an efficient motion planning and control pipeline. To start, we propose a reduced-order template model-the dual-legged actuated spring-loaded inverted pendulum with trunk rotation-which explicitly models parallel compliance by decoupling spring effects from active motor actuation. With this template model, versatile acrobatic motions, such as pronking, froggy jumping, and hop-turn, are generated by a dual-layer trajectory optimization, where the singularity-free body rotation representation is taken into consideration. Integrated with a linear singularity-free tracking controller, enhanced quadrupedal locomotion is achieved. Comparisons with the existing template model reveal the improved accuracy and generalization of our model. Hardware experiments with a rigid quadruped and a newly designed compliant quadruped demonstrate that i) the template model enables generating versatile dynamic motion; ii) parallel elasticity enhances explosive motion. For example, the maximal pronking distance, hop-turn yaw angle, and froggy jumping distance increase at least by 25%, 15% and 25%, respectively; iii) parallel elasticity improves the robustness against dynamic uncertainties, including modelling errors and external disturbances. For example, the allowable support surface height variation increases by 100% for robust froggy jumping.
Regulating Model Reliance on Non-Robust Features by Smoothing Input Marginal Density
Jul 05, 2024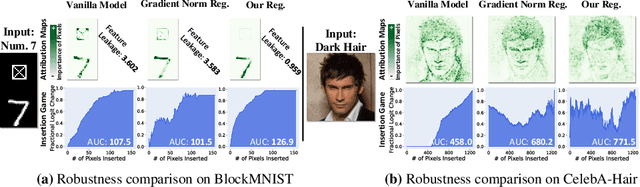
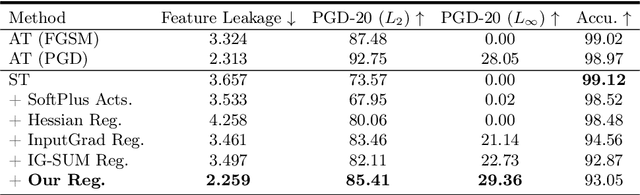
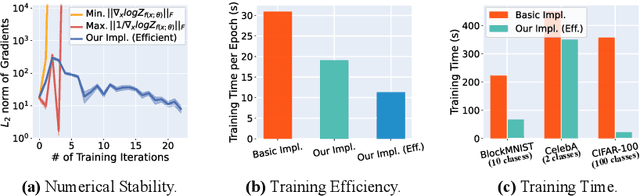

Trustworthy machine learning necessitates meticulous regulation of model reliance on non-robust features. We propose a framework to delineate and regulate such features by attributing model predictions to the input. Within our approach, robust feature attributions exhibit a certain consistency, while non-robust feature attributions are susceptible to fluctuations. This behavior allows identification of correlation between model reliance on non-robust features and smoothness of marginal density of the input samples. Hence, we uniquely regularize the gradients of the marginal density w.r.t. the input features for robustness. We also devise an efficient implementation of our regularization to address the potential numerical instability of the underlying optimization process. Moreover, we analytically reveal that, as opposed to our marginal density smoothing, the prevalent input gradient regularization smoothens conditional or joint density of the input, which can cause limited robustness. Our experiments validate the effectiveness of the proposed method, providing clear evidence of its capability to address the feature leakage problem and mitigate spurious correlations. Extensive results further establish that our technique enables the model to exhibit robustness against perturbations in pixel values, input gradients, and density.
Fast-PGM: Fast Probabilistic Graphical Model Learning and Inference
May 28, 2024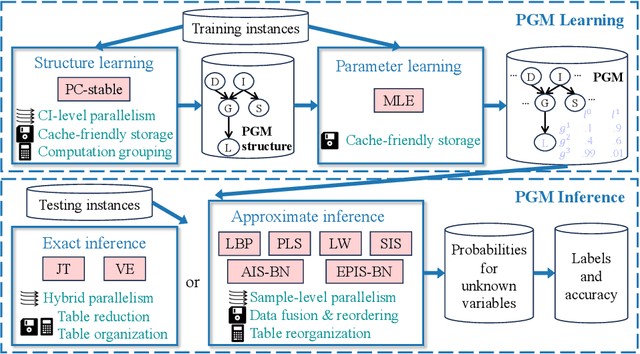
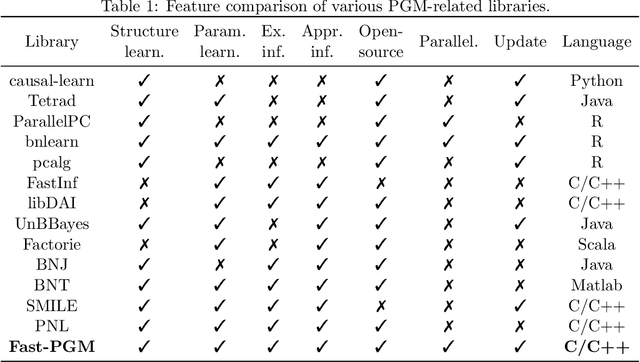
Probabilistic graphical models (PGMs) serve as a powerful framework for modeling complex systems with uncertainty and extracting valuable insights from data. However, users face challenges when applying PGMs to their problems in terms of efficiency and usability. This paper presents Fast-PGM, an efficient and open-source library for PGM learning and inference. Fast-PGM supports comprehensive tasks on PGMs, including structure and parameter learning, as well as exact and approximate inference, and enhances efficiency of the tasks through computational and memory optimizations and parallelization techniques. Concurrently, Fast-PGM furnishes developers with flexible building blocks, furnishes learners with detailed documentation, and affords non-experts user-friendly interfaces, thereby ameliorating the usability of PGMs to users across a spectrum of expertise levels. The source code of Fast-PGM is available at https://github.com/jjiantong/FastPGM.
Backdoor-based Explainable AI Benchmark for High Fidelity Evaluation of Attribution Methods
May 02, 2024

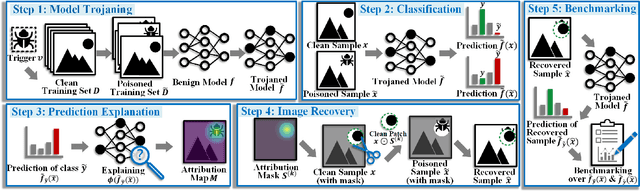

Attribution methods compute importance scores for input features to explain the output predictions of deep models. However, accurate assessment of attribution methods is challenged by the lack of benchmark fidelity for attributing model predictions. Moreover, other confounding factors in attribution estimation, including the setup choices of post-processing techniques and explained model predictions, further compromise the reliability of the evaluation. In this work, we first identify a set of fidelity criteria that reliable benchmarks for attribution methods are expected to fulfill, thereby facilitating a systematic assessment of attribution benchmarks. Next, we introduce a Backdoor-based eXplainable AI benchmark (BackX) that adheres to the desired fidelity criteria. We theoretically establish the superiority of our approach over the existing benchmarks for well-founded attribution evaluation. With extensive analysis, we also identify a setup for a consistent and fair benchmarking of attribution methods across different underlying methodologies. This setup is ultimately employed for a comprehensive comparison of existing methods using our BackX benchmark. Finally, our analysis also provides guidance for defending against backdoor attacks with the help of attribution methods.
AnoOnly: Semi-Supervised Anomaly Detection without Loss on Normal Data
May 30, 2023
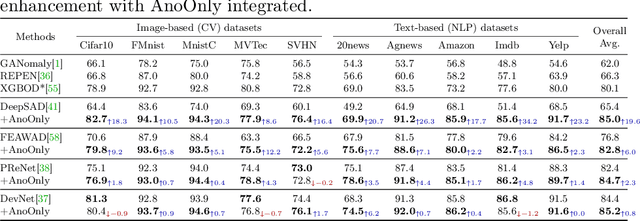

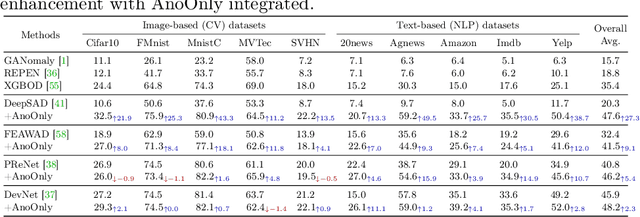
Semi-supervised anomaly detection (SSAD) methods have demonstrated their effectiveness in enhancing unsupervised anomaly detection (UAD) by leveraging few-shot but instructive abnormal instances. However, the dominance of homogeneous normal data over anomalies biases the SSAD models against effectively perceiving anomalies. To address this issue and achieve balanced supervision between heavily imbalanced normal and abnormal data, we develop a novel framework called AnoOnly (Anomaly Only). Unlike existing SSAD methods that resort to strict loss supervision, AnoOnly suspends it and introduces a form of weak supervision for normal data. This weak supervision is instantiated through the utilization of batch normalization, which implicitly performs cluster learning on normal data. When integrated into existing SSAD methods, the proposed AnoOnly demonstrates remarkable performance enhancements across various models and datasets, achieving new state-of-the-art performance. Additionally, our AnoOnly is natively robust to label noise when suffering from data contamination. Our code is publicly available at https://github.com/cool-xuan/AnoOnly.