 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 The Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images. Building upon the success of the first edition, this challenge attracted a wide range of impressive solutions, all developed and evaluated on our real-world Raindrop Clarity dataset~\cite{jin2024raindrop}. For this edition, we adjust the dataset with 14,139 images for training, 407 images for validation, and 593 images for testing. The primary goal of this challenge is to establish a strong and practical benchmark for the removal of raindrops under various illumination and focus conditions. In total, 168 teams have registered for the competition, and 17 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the Raindrop Clarity dataset, demonstrating the growing progress in this challenging task.
Language-Grounded Decoupled Action Representation for Robotic Manipulation
Mar 13, 2026The heterogeneity between high-level vision-language understanding and low-level action control remains a fundamental challenge in robotic manipulation. Although recent methods have advanced task-specific action alignment, they often struggle to generate robust and accurate actions for novel or semantically related tasks. To address this, we propose the Language-Grounded Decoupled Action Representation (LaDA) framework, which leverages natural language as a semantic bridge to connect perception and control. LaDA introduces a fine-grained intermediate layer of three interpretable action primitives--translation, rotation, and gripper control--providing explicit semantic structure for low-level actions. It further employs a semantic-guided soft-label contrastive learning objective to align similar action primitives across tasks, enhancing generalization and motion consistency. An adaptive weighting strategy, inspired by curriculum learning, dynamically balances contrastive and imitation objectives for stable and effective training. Extensive experiments on simulated benchmarks (LIBERO and MimicGen) and real-world demonstrations validate that LaDA achieves strong performance and generalizes effectively to unseen or related tasks.
MiVLA: Towards Generalizable Vision-Language-Action Model with Human-Robot Mutual Imitation Pre-training
Dec 19, 2025While leveraging abundant human videos and simulated robot data poses a scalable solution to the scarcity of real-world robot data, the generalization capability of existing vision-language-action models (VLAs) remains limited by mismatches in camera views, visual appearance, and embodiment morphologies. To overcome this limitation, we propose MiVLA, a generalizable VLA empowered by human-robot mutual imitation pre-training, which leverages inherent behavioral similarity between human hands and robotic arms to build a foundation of strong behavioral priors for both human actions and robotic control. Specifically, our method utilizes kinematic rules with left/right hand coordinate systems for bidirectional alignment between human and robot action spaces. Given human or simulated robot demonstrations, MiVLA is trained to forecast behavior trajectories for one embodiment, and imitate behaviors for another one unseen in the demonstration. Based on this mutual imitation, it integrates the behavioral fidelity of real-world human data with the manipulative diversity of simulated robot data into a unified model, thereby enhancing the generalization capability for downstream tasks. Extensive experiments conducted on both simulation and real-world platforms with three robots (ARX, PiPer and LocoMan), demonstrate that MiVLA achieves strong improved generalization capability, outperforming state-of-the-art VLAs (e.g., $\boldsymbolπ_{0}$, $\boldsymbolπ_{0.5}$ and H-RDT) by 25% in simulation, and 14% in real-world robot control tasks.
What Makes Reasoning Invalid: Echo Reflection Mitigation for Large Language Models
Nov 09, 2025
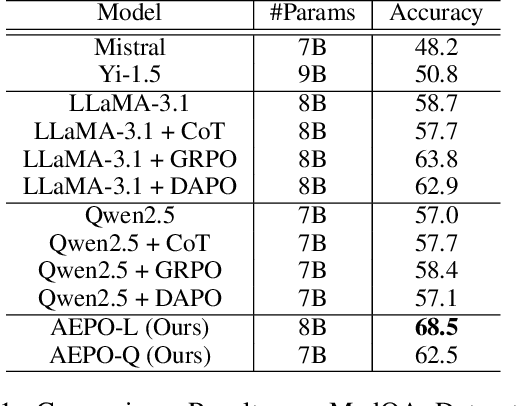
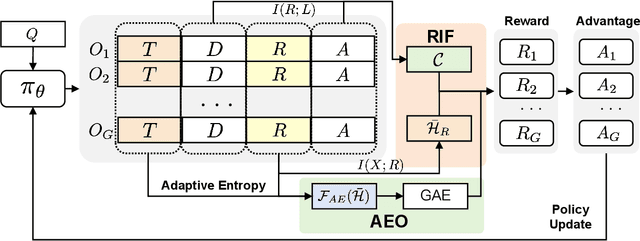
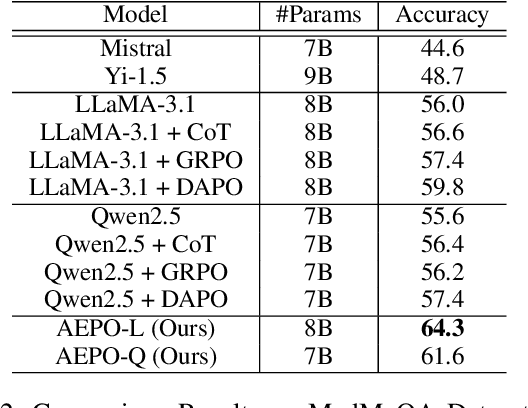
Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of reasoning tasks. Recent methods have further improved LLM performance in complex mathematical reasoning. However, when extending these methods beyond the domain of mathematical reasoning to tasks involving complex domain-specific knowledge, we observe a consistent failure of LLMs to generate novel insights during the reflection stage. Instead of conducting genuine cognitive refinement, the model tends to mechanically reiterate earlier reasoning steps without introducing new information or perspectives, a phenomenon referred to as "Echo Reflection". We attribute this behavior to two key defects: (1) Uncontrollable information flow during response generation, which allows premature intermediate thoughts to propagate unchecked and distort final decisions; (2) Insufficient exploration of internal knowledge during reflection, leading to repeating earlier findings rather than generating new cognitive insights. Building on these findings, we proposed a novel reinforcement learning method termed Adaptive Entropy Policy Optimization (AEPO). Specifically, the AEPO framework consists of two major components: (1) Reflection-aware Information Filtration, which quantifies the cognitive information flow and prevents the final answer from being affected by earlier bad cognitive information; (2) Adaptive-Entropy Optimization, which dynamically balances exploration and exploitation across different reasoning stages, promoting both reflective diversity and answer correctness. Extensive experiments demonstrate that AEPO consistently achieves state-of-the-art performance over mainstream reinforcement learning baselines across diverse benchmarks.
Parameter-Free Structural-Diversity Message Passing for Graph Neural Networks
Aug 28, 2025Graph Neural Networks (GNNs) have shown remarkable performance in structured data modeling tasks such as node classification. However, mainstream approaches generally rely on a large number of trainable parameters and fixed aggregation rules, making it difficult to adapt to graph data with strong structural heterogeneity and complex feature distributions. This often leads to over-smoothing of node representations and semantic degradation. To address these issues, this paper proposes a parameter-free graph neural network framework based on structural diversity, namely SDGNN (Structural-Diversity Graph Neural Network). The framework is inspired by structural diversity theory and designs a unified structural-diversity message passing mechanism that simultaneously captures the heterogeneity of neighborhood structures and the stability of feature semantics, without introducing additional trainable parameters. Unlike traditional parameterized methods, SDGNN does not rely on complex model training, but instead leverages complementary modeling from both structure-driven and feature-driven perspectives, thereby effectively improving adaptability across datasets and scenarios. Experimental results show that on eight public benchmark datasets and an interdisciplinary PubMed citation network, SDGNN consistently outperforms mainstream GNNs under challenging conditions such as low supervision, class imbalance, and cross-domain transfer. This work provides a new theoretical perspective and general approach for the design of parameter-free graph neural networks, and further validates the importance of structural diversity as a core signal in graph representation learning. To facilitate reproducibility and further research, the full implementation of SDGNN has been released at: https://github.com/mingyue15694/SGDNN/tree/main
Mitigating Object Hallucination via Robust Local Perception Search
Jun 07, 2025Recent advancements in Multimodal Large Language Models (MLLMs) have enabled them to effectively integrate vision and language, addressing a variety of downstream tasks. However, despite their significant success, these models still exhibit hallucination phenomena, where the outputs appear plausible but do not align with the content of the images. To mitigate this issue, we introduce Local Perception Search (LPS), a decoding method during inference that is both simple and training-free, yet effectively suppresses hallucinations. This method leverages local visual prior information as a value function to correct the decoding process. Additionally, we observe that the impact of the local visual prior on model performance is more pronounced in scenarios with high levels of image noise. Notably, LPS is a plug-and-play approach that is compatible with various models. Extensive experiments on widely used hallucination benchmarks and noisy data demonstrate that LPS significantly reduces the incidence of hallucinations compared to the baseline, showing exceptional performance, particularly in noisy settings.
Truth in the Few: High-Value Data Selection for Efficient Multi-Modal Reasoning
Jun 05, 2025While multi-modal large language models (MLLMs) have made significant progress in complex reasoning tasks via reinforcement learning, it is commonly believed that extensive training data is necessary for improving multi-modal reasoning ability, inevitably leading to data redundancy and substantial computational costs. However, can smaller high-value datasets match or outperform full corpora for multi-modal reasoning in MLLMs? In this work, we challenge this assumption through a key observation: meaningful multi-modal reasoning is triggered by only a sparse subset of training samples, termed cognitive samples, whereas the majority contribute marginally. Building on this insight, we propose a novel data selection paradigm termed Reasoning Activation Potential (RAP), which identifies cognitive samples by estimating each sample's potential to stimulate genuine multi-modal reasoning by two complementary estimators: 1) Causal Discrepancy Estimator (CDE) based on the potential outcome model principle, eliminates samples that overly rely on language priors by comparing outputs between multi-modal and text-only inputs; 2) Attention Confidence Estimator (ACE), which exploits token-level self-attention to discard samples dominated by irrelevant but over-emphasized tokens in intermediate reasoning stages. Moreover, we introduce a Difficulty-aware Replacement Module (DRM) to substitute trivial instances with cognitively challenging ones, thereby ensuring complexity for robust multi-modal reasoning. Experiments on six datasets show that our RAP method consistently achieves superior performance using only 9.3% of the training data, while reducing computational costs by over 43%. Our code is available at https://github.com/Leo-ssl/RAP.
MSCRS: Multi-modal Semantic Graph Prompt Learning Framework for Conversational Recommender Systems
Apr 15, 2025Conversational Recommender Systems (CRSs) aim to provide personalized recommendations by interacting with users through conversations. Most existing studies of CRS focus on extracting user preferences from conversational contexts. However, due to the short and sparse nature of conversational contexts, it is difficult to fully capture user preferences by conversational contexts only. We argue that multi-modal semantic information can enrich user preference expressions from diverse dimensions (e.g., a user preference for a certain movie may stem from its magnificent visual effects and compelling storyline). In this paper, we propose a multi-modal semantic graph prompt learning framework for CRS, named MSCRS. First, we extract textual and image features of items mentioned in the conversational contexts. Second, we capture higher-order semantic associations within different semantic modalities (collaborative, textual, and image) by constructing modality-specific graph structures. Finally, we propose an innovative integration of multi-modal semantic graphs with prompt learning, harnessing the power of large language models to comprehensively explore high-dimensional semantic relationships. Experimental results demonstrate that our proposed method significantly improves accuracy in item recommendation, as well as generates more natural and contextually relevant content in response generation. We have released the code and the expanded multi-modal CRS datasets to facilitate further exploration in related research\footnote{https://github.com/BIAOBIAO12138/MSCRS-main}.
ReCon: Enhancing True Correspondence Discrimination through Relation Consistency for Robust Noisy Correspondence Learning
Feb 27, 2025Can we accurately identify the true correspondences from multimodal datasets containing mismatched data pairs? Existing methods primarily emphasize the similarity matching between the representations of objects across modalities, potentially neglecting the crucial relation consistency within modalities that are particularly important for distinguishing the true and false correspondences. Such an omission often runs the risk of misidentifying negatives as positives, thus leading to unanticipated performance degradation. To address this problem, we propose a general Relation Consistency learning framework, namely ReCon, to accurately discriminate the true correspondences among the multimodal data and thus effectively mitigate the adverse impact caused by mismatches. Specifically, ReCon leverages a novel relation consistency learning to ensure the dual-alignment, respectively of, the cross-modal relation consistency between different modalities and the intra-modal relation consistency within modalities. Thanks to such dual constrains on relations, ReCon significantly enhances its effectiveness for true correspondence discrimination and therefore reliably filters out the mismatched pairs to mitigate the risks of wrong supervisions. Extensive experiments on three widely-used benchmark datasets, including Flickr30K, MS-COCO, and Conceptual Captions, are conducted to demonstrate the effectiveness and superiority of ReCon compared with other SOTAs. The code is available at: https://github.com/qxzha/ReCon.
TANGNN: a Concise, Scalable and Effective Graph Neural Networks with Top-m Attention Mechanism for Graph Representation Learning
Nov 23, 2024



In the field of deep learning, Graph Neural Networks (GNNs) and Graph Transformer models, with their outstanding performance and flexible architectural designs, have become leading technologies for processing structured data, especially graph data. Traditional GNNs often face challenges in capturing information from distant vertices effectively. In contrast, Graph Transformer models are particularly adept at managing long-distance node relationships. Despite these advantages, Graph Transformer models still encounter issues with computational and storage efficiency when scaled to large graph datasets. To address these challenges, we propose an innovative Graph Neural Network (GNN) architecture that integrates a Top-m attention mechanism aggregation component and a neighborhood aggregation component, effectively enhancing the model's ability to aggregate relevant information from both local and extended neighborhoods at each layer. This method not only improves computational efficiency but also enriches the node features, facilitating a deeper analysis of complex graph structures. Additionally, to assess the effectiveness of our proposed model, we have applied it to citation sentiment prediction, a novel task previously unexplored in the GNN field. Accordingly, we constructed a dedicated citation network, ArXivNet. In this dataset, we specifically annotated the sentiment polarity of the citations (positive, neutral, negative) to enable in-depth sentiment analysis. Our approach has shown superior performance across a variety of tasks including vertex classification, link prediction, sentiment prediction, graph regression, and visualization. It outperforms existing methods in terms of effectiveness, as demonstrated by experimental results on multiple datasets.