 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Temporal Difference Transformer for Video-Text Retrieval
Paper and Code
Jun 23, 2024

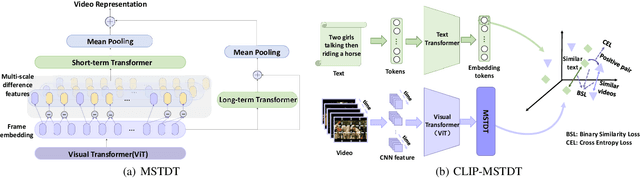
Currently, in the field of video-text retrieval, there are many transformer-based methods. Most of them usually stack frame features and regrade frames as tokens, then use transformers for video temporal modeling. However, they commonly neglect the inferior ability of the transformer modeling local temporal information. To tackle this problem, we propose a transformer variant named Multi-Scale Temporal Difference Transformer (MSTDT). MSTDT mainly addresses the defects of the traditional transformer which has limited ability to capture local temporal information. Besides, in order to better model the detailed dynamic information, we make use of the difference feature between frames, which practically reflects the dynamic movement of a video. We extract the inter-frame difference feature and integrate the difference and frame feature by the multi-scale temporal transformer. In general, our proposed MSTDT consists of a short-term multi-scale temporal difference transformer and a long-term temporal transformer. The former focuses on modeling local temporal information, the latter aims at modeling global temporal information. At last, we propose a new loss to narrow the distance of similar samples. Extensive experiments show that backbone, such as CLIP, with MSTDT has attained a new state-of-the-art result.