 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-HRNet: Towards Lightweight Human Pose Estimation with Spatially Unidimensional Self-Attention
Paper and Code

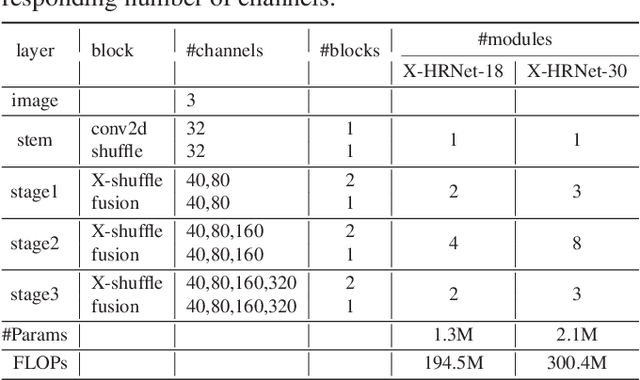
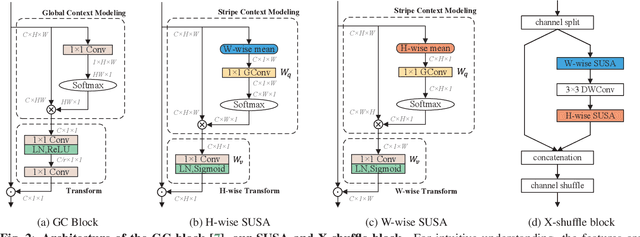
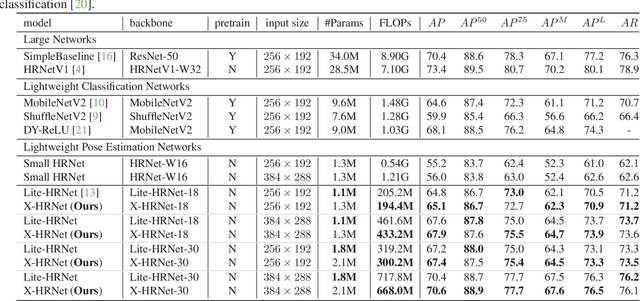
High-resolution representation is necessary for human pose estimation to achieve high performance, and the ensuing problem is high computational complexity. In particular, predominant pose estimation methods estimate human joints by 2D single-peak heatmaps. Each 2D heatmap can be horizontally and vertically projected to and reconstructed by a pair of 1D heat vectors. Inspired by this observation, we introduce a lightweight and powerful alternative, Spatially Unidimensional Self-Attention (SUSA), to the pointwise (1x1) convolution that is the main computational bottleneck in the depthwise separable 3c3 convolution. Our SUSA reduces the computational complexity of the pointwise (1x1) convolution by 96% without sacrificing accuracy. Furthermore, we use the SUSA as the main module to build our lightweight pose estimation backbone X-HRNet, where `X' represents the estimated cross-shape attention vectors. Extensive experiments on the COCO benchmark demonstrate the superiority of our X-HRNet, and comprehensive ablation studies show the effectiveness of the SUSA modules. The code is publicly available at https://github.com/cool-xuan/x-hrnet.