 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiVLA: Towards Generalizable Vision-Language-Action Model with Human-Robot Mutual Imitation Pre-training
Dec 19, 2025While leveraging abundant human videos and simulated robot data poses a scalable solution to the scarcity of real-world robot data, the generalization capability of existing vision-language-action models (VLAs) remains limited by mismatches in camera views, visual appearance, and embodiment morphologies. To overcome this limitation, we propose MiVLA, a generalizable VLA empowered by human-robot mutual imitation pre-training, which leverages inherent behavioral similarity between human hands and robotic arms to build a foundation of strong behavioral priors for both human actions and robotic control. Specifically, our method utilizes kinematic rules with left/right hand coordinate systems for bidirectional alignment between human and robot action spaces. Given human or simulated robot demonstrations, MiVLA is trained to forecast behavior trajectories for one embodiment, and imitate behaviors for another one unseen in the demonstration. Based on this mutual imitation, it integrates the behavioral fidelity of real-world human data with the manipulative diversity of simulated robot data into a unified model, thereby enhancing the generalization capability for downstream tasks. Extensive experiments conducted on both simulation and real-world platforms with three robots (ARX, PiPer and LocoMan), demonstrate that MiVLA achieves strong improved generalization capability, outperforming state-of-the-art VLAs (e.g., $\boldsymbolπ_{0}$, $\boldsymbolπ_{0.5}$ and H-RDT) by 25% in simulation, and 14% in real-world robot control tasks.
Learning Generalizable and Efficient Image Watermarking via Hierarchical Two-Stage Optimization
Aug 12, 2025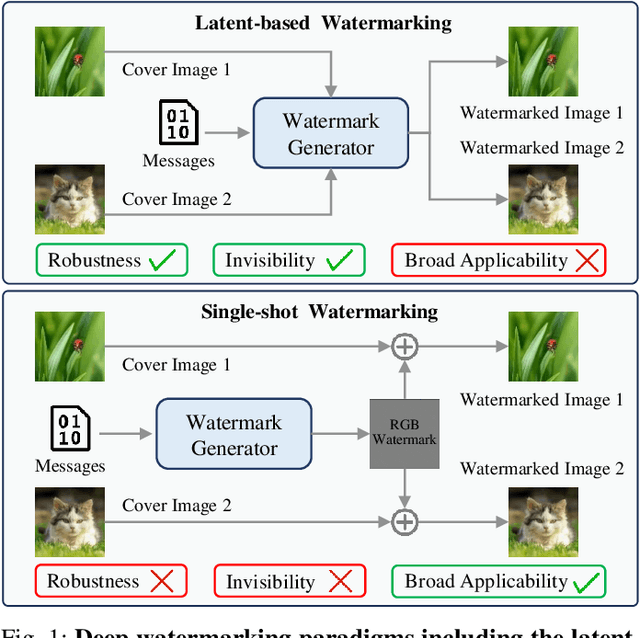

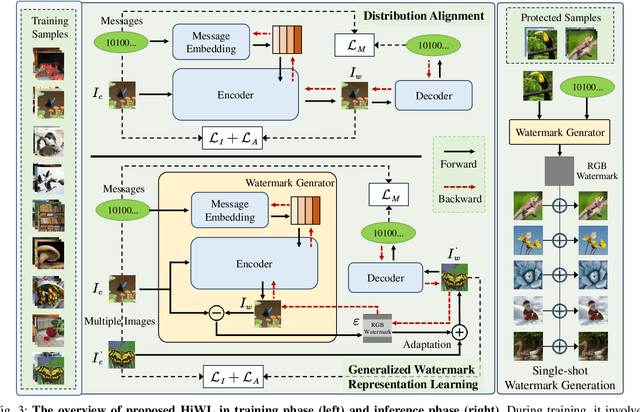

Deep image watermarking, which refers to enable imperceptible watermark embedding and reliable extraction in cover images, has shown to be effective for copyright protection of image assets. However, existing methods face limitations in simultaneously satisfying three essential criteria for generalizable watermarking: 1) invisibility (imperceptible hide of watermarks), 2) robustness (reliable watermark recovery under diverse conditions), and 3) broad applicability (low latency in watermarking process). To address these limitations, we propose a Hierarchical Watermark Learning (HiWL), a two-stage optimization that enable a watermarking model to simultaneously achieve three criteria. In the first stage, distribution alignment learning is designed to establish a common latent space with two constraints: 1) visual consistency between watermarked and non-watermarked images, and 2) information invariance across watermark latent representations. In this way, multi-modal inputs including watermark message (binary codes) and cover images (RGB pixels) can be well represented, ensuring the invisibility of watermarks and robustness in watermarking process thereby. The second stage employs generalized watermark representation learning to establish a disentanglement policy for separating watermarks from image content in RGB space. In particular, it strongly penalizes substantial fluctuations in separated RGB watermarks corresponding to identical messages. Consequently, HiWL effectively learns generalizable latent-space watermark representations while maintaining broad applicability. Extensive experiments demonstrate the effectiveness of proposed method. In particular, it achieves 7.6\% higher accuracy in watermark extraction than existing methods, while maintaining extremely low latency (100K images processed in 8s).
Dynamic Pattern Alignment Learning for Pretraining Lightweight Human-Centric Vision Models
Aug 10, 2025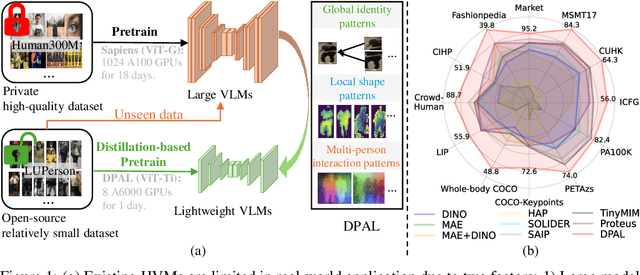
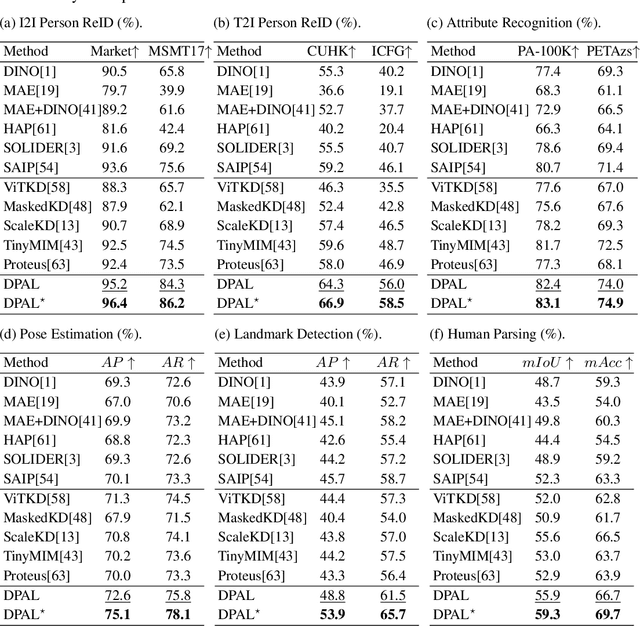
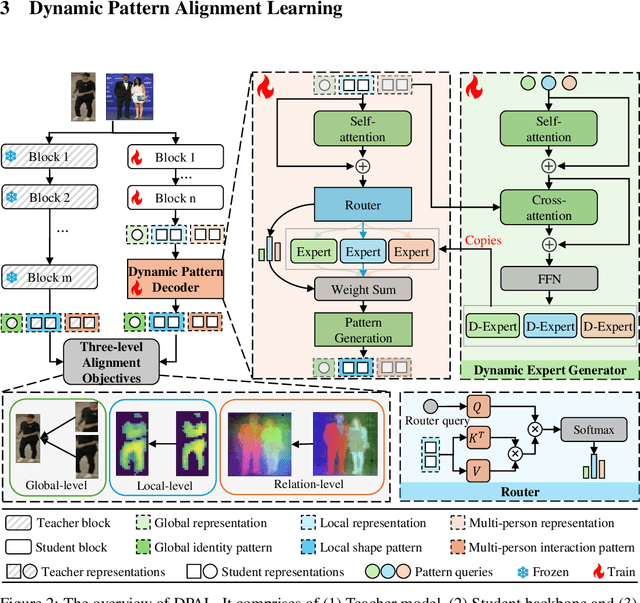
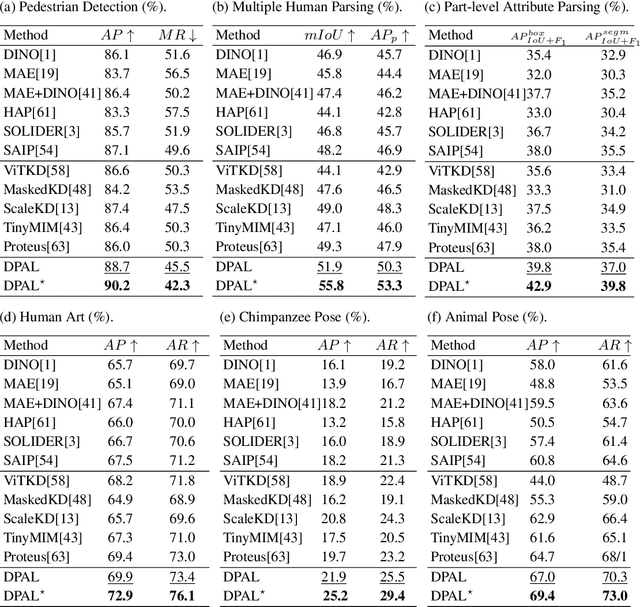
Human-centric vision models (HVMs) have achieved remarkable generalization due to large-scale pretraining on massive person images. However, their dependence on large neural architectures and the restricted accessibility of pretraining data significantly limits their practicality in real-world applications. To address this limitation, we propose Dynamic Pattern Alignment Learning (DPAL), a novel distillation-based pretraining framework that efficiently trains lightweight HVMs to acquire strong generalization from large HVMs. In particular, human-centric visual perception are highly dependent on three typical visual patterns, including global identity pattern, local shape pattern and multi-person interaction pattern. To achieve generalizable lightweight HVMs, we firstly design a dynamic pattern decoder (D-PaDe), acting as a dynamic Mixture of Expert (MoE) model. It incorporates three specialized experts dedicated to adaptively extract typical visual patterns, conditioned on both input image and pattern queries. And then, we present three levels of alignment objectives, which aims to minimize generalization gap between lightweight HVMs and large HVMs at global image level, local pixel level, and instance relation level. With these two deliberate designs, the DPAL effectively guides lightweight model to learn all typical human visual patterns from large HVMs, which can generalize to various human-centric vision tasks. Extensive experiments conducted on 15 challenging datasets demonstrate the effectiveness of the DPAL. Remarkably, when employing PATH-B as the teacher, DPAL-ViT/Ti (5M parameters) achieves surprising generalizability similar to existing large HVMs such as PATH-B (84M) and Sapiens-L (307M), and outperforms previous distillation-based pretraining methods including Proteus-ViT/Ti (5M) and TinyMiM-ViT/Ti (5M) by a large margin.
Scale-Aware Pre-Training for Human-Centric Visual Perception: Enabling Lightweight and Generalizable Models
Mar 11, 2025Human-centric visual perception (HVP) has recently achieved remarkable progress due to advancements in large-scale self-supervised pretraining (SSP). However, existing HVP models face limitations in adapting to real-world applications, which require general visual patterns for downstream tasks while maintaining computationally sustainable costs to ensure compatibility with edge devices. These limitations primarily arise from two issues: 1) the pretraining objectives focus solely on specific visual patterns, limiting the generalizability of the learned patterns for diverse downstream tasks; and 2) HVP models often exhibit excessively large model sizes, making them incompatible with real-world applications. To address these limitations, we introduce Scale-Aware Image Pretraining (SAIP), a novel SSP framework enabling lightweight vision models to acquire general patterns for HVP. Specifically, SAIP incorporates three learning objectives based on the principle of cross-scale consistency: 1) Cross-scale Matching (CSM) which contrastively learns image-level invariant patterns from multi-scale single-person images; 2) Cross-scale Reconstruction (CSR) which learns pixel-level consistent visual structures from multi-scale masked single-person images; and 3) Cross-scale Search (CSS) which learns to capture diverse patterns from multi-scale multi-person images. Three objectives complement one another, enabling lightweight models to learn multi-scale generalizable patterns essential for HVP downstream tasks.Extensive experiments conducted across 12 HVP datasets demonstrate that SAIP exhibits remarkable generalization capabilities across 9 human-centric vision tasks. Moreover, it achieves significant performance improvements over existing methods, with gains of 3%-13% in single-person discrimination tasks, 1%-11% in dense prediction tasks, and 1%-6% in multi-person visual understanding tasks.
Realistic Corner Case Generation for Autonomous Vehicles with Multimodal Large Language Model
Nov 29, 2024


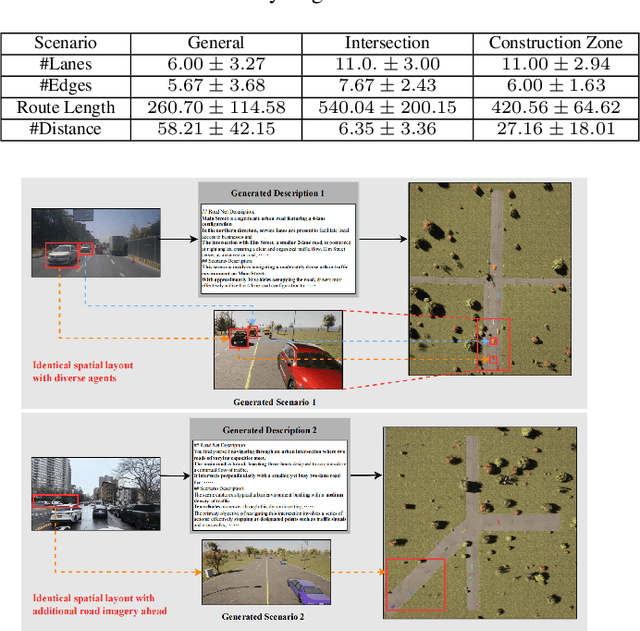
To guarantee the safety and reliability of autonomous vehicle (AV) systems, corner cases play a crucial role in exploring the system's behavior under rare and challenging conditions within simulation environments. However, current approaches often fall short in meeting diverse testing needs and struggle to generalize to novel, high-risk scenarios that closely mirror real-world conditions. To tackle this challenge, we present AutoScenario, a multimodal Large Language Model (LLM)-based framework for realistic corner case generation. It converts safety-critical real-world data from multiple sources into textual representations, enabling the generalization of key risk factors while leveraging the extensive world knowledge and advanced reasoning capabilities of LLMs.Furthermore, it integrates tools from the Simulation of Urban Mobility (SUMO) and CARLA simulators to simplify and execute the code generated by LLMs. Our experiments demonstrate that AutoScenario can generate realistic and challenging test scenarios, precisely tailored to specific testing requirements or textual descriptions. Additionally, we validated its ability to produce diverse and novel scenarios derived from multimodal real-world data involving risky situations, harnessing the powerful generalization capabilities of LLMs to effectively simulate a wide range of corner cases.
Multimodal Large Language Model Driven Scenario Testing for Autonomous Vehicles
Sep 10, 2024The generation of corner cases has become increasingly crucial for efficiently testing autonomous vehicles prior to road deployment. However, existing methods struggle to accommodate diverse testing requirements and often lack the ability to generalize to unseen situations, thereby reducing the convenience and usability of the generated scenarios. A method that facilitates easily controllable scenario generation for efficient autonomous vehicles (AV) testing with realistic and challenging situations is greatly needed. To address this, we proposed OmniTester: a multimodal Large Language Model (LLM) based framework that fully leverages the extensive world knowledge and reasoning capabilities of LLMs. OmniTester is designed to generate realistic and diverse scenarios within a simulation environment, offering a robust solution for testing and evaluating AVs. In addition to prompt engineering, we employ tools from Simulation of Urban Mobility to simplify the complexity of codes generated by LLMs. Furthermore, we incorporate Retrieval-Augmented Generation and a self-improvement mechanism to enhance the LLM's understanding of scenarios, thereby increasing its ability to produce more realistic scenes. In the experiments, we demonstrated the controllability and realism of our approaches in generating three types of challenging and complex scenarios. Additionally, we showcased its effectiveness in reconstructing new scenarios described in crash report, driven by the generalization capability of LLMs.
Any Target Can be Offense: Adversarial Example Generation via Generalized Latent Infection
Jul 17, 2024Targeted adversarial attack, which aims to mislead a model to recognize any image as a target object by imperceptible perturbations, has become a mainstream tool for vulnerability assessment of deep neural networks (DNNs). Since existing targeted attackers only learn to attack known target classes, they cannot generalize well to unknown classes. To tackle this issue, we propose $\bf{G}$eneralized $\bf{A}$dversarial attac$\bf{KER}$ ($\bf{GAKer}$), which is able to construct adversarial examples to any target class. The core idea behind GAKer is to craft a latently infected representation during adversarial example generation. To this end, the extracted latent representations of the target object are first injected into intermediate features of an input image in an adversarial generator. Then, the generator is optimized to ensure visual consistency with the input image while being close to the target object in the feature space. Since the GAKer is class-agnostic yet model-agnostic, it can be regarded as a general tool that not only reveals the vulnerability of more DNNs but also identifies deficiencies of DNNs in a wider range of classes. Extensive experiments have demonstrated the effectiveness of our proposed method in generating adversarial examples for both known and unknown classes. Notably, compared with other generative methods, our method achieves an approximately $14.13\%$ higher attack success rate for unknown classes and an approximately $4.23\%$ higher success rate for known classes. Our code is available in https://github.com/VL-Group/GAKer.
X-HRNet: Towards Lightweight Human Pose Estimation with Spatially Unidimensional Self-Attention
Oct 12, 2023
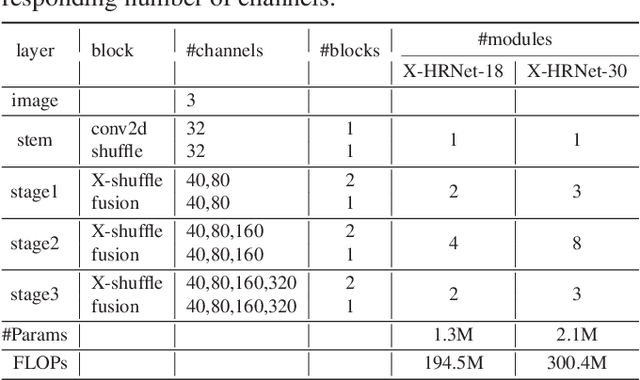
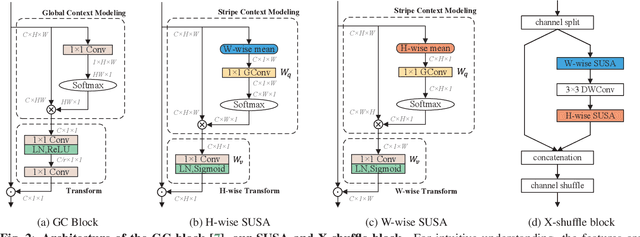
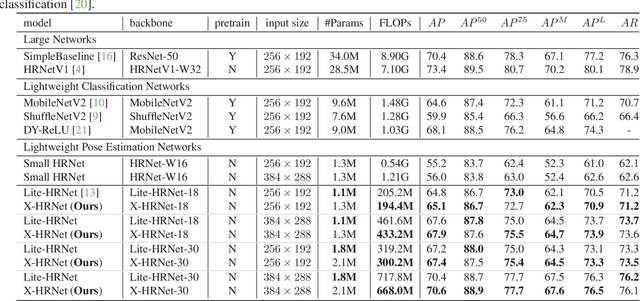
High-resolution representation is necessary for human pose estimation to achieve high performance, and the ensuing problem is high computational complexity. In particular, predominant pose estimation methods estimate human joints by 2D single-peak heatmaps. Each 2D heatmap can be horizontally and vertically projected to and reconstructed by a pair of 1D heat vectors. Inspired by this observation, we introduce a lightweight and powerful alternative, Spatially Unidimensional Self-Attention (SUSA), to the pointwise (1x1) convolution that is the main computational bottleneck in the depthwise separable 3c3 convolution. Our SUSA reduces the computational complexity of the pointwise (1x1) convolution by 96% without sacrificing accuracy. Furthermore, we use the SUSA as the main module to build our lightweight pose estimation backbone X-HRNet, where `X' represents the estimated cross-shape attention vectors. Extensive experiments on the COCO benchmark demonstrate the superiority of our X-HRNet, and comprehensive ablation studies show the effectiveness of the SUSA modules. The code is publicly available at https://github.com/cool-xuan/x-hrnet.
CIParsing: Unifying Causality Properties into Multiple Human Parsing
Aug 23, 2023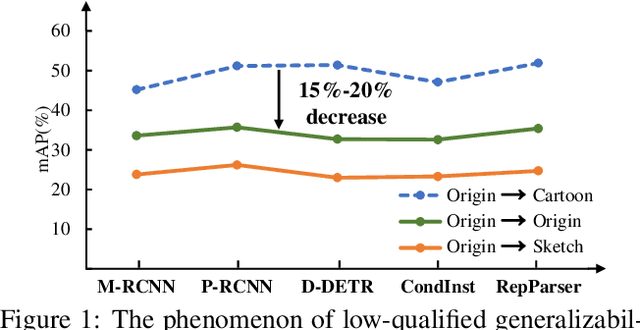
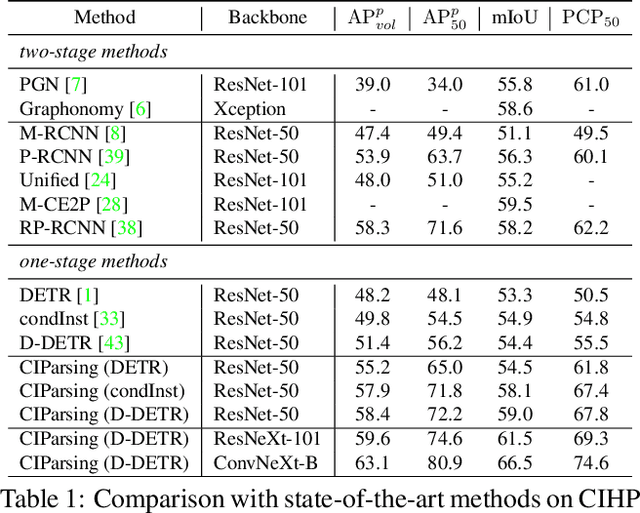
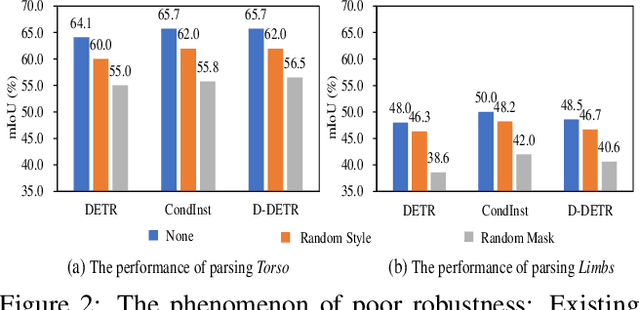
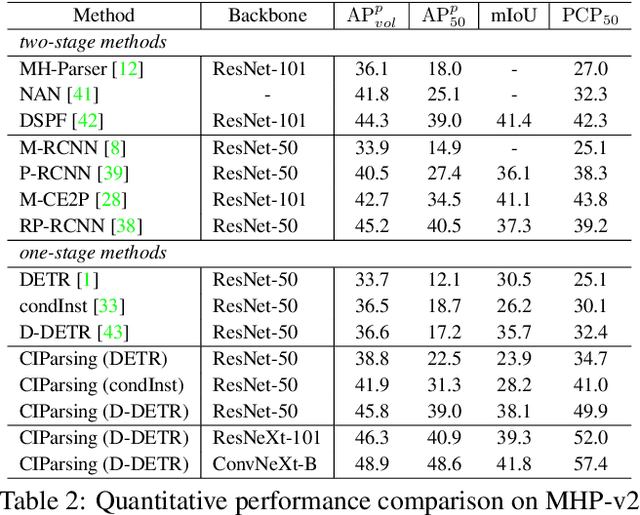
Existing methods of multiple human parsing (MHP) apply statistical models to acquire underlying associations between images and labeled body parts. However, acquired associations often contain many spurious correlations that degrade model generalization, leading statistical models to be vulnerable to visually contextual variations in images (e.g., unseen image styles/external interventions). To tackle this, we present a causality inspired parsing paradigm termed CIParsing, which follows fundamental causal principles involving two causal properties for human parsing (i.e., the causal diversity and the causal invariance). Specifically, we assume that an input image is constructed by a mix of causal factors (the characteristics of body parts) and non-causal factors (external contexts), where only the former ones cause the generation process of human parsing.Since causal/non-causal factors are unobservable, a human parser in proposed CIParsing is required to construct latent representations of causal factors and learns to enforce representations to satisfy the causal properties. In this way, the human parser is able to rely on causal factors w.r.t relevant evidence rather than non-causal factors w.r.t spurious correlations, thus alleviating model degradation and yielding improved parsing ability. Notably, the CIParsing is designed in a plug-and-play fashion and can be integrated into any existing MHP models. Extensive experiments conducted on two widely used benchmarks demonstrate the effectiveness and generalizability of our method.
RepParser: End-to-End Multiple Human Parsing with Representative Parts
Aug 27, 2022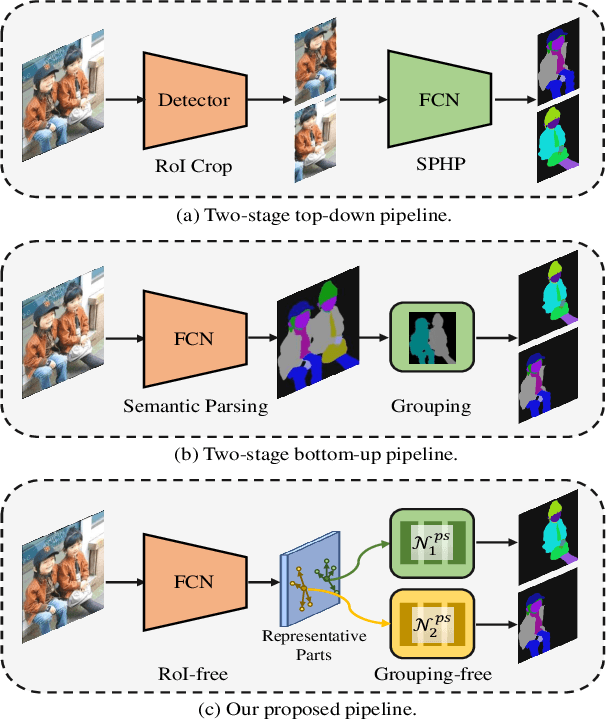
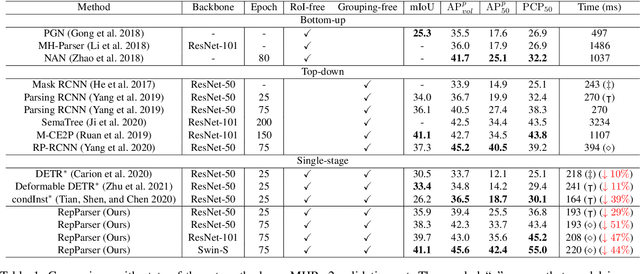
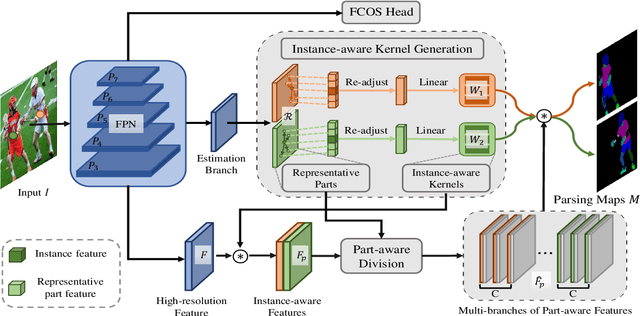
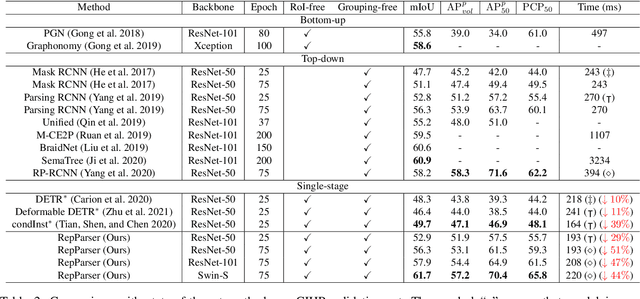
Existing methods of multiple human parsing usually adopt a two-stage strategy (typically top-down and bottom-up), which suffers from either strong dependence on prior detection or highly computational redundancy during post-grouping. In this work, we present an end-to-end multiple human parsing framework using representative parts, termed RepParser. Different from mainstream methods, RepParser solves the multiple human parsing in a new single-stage manner without resorting to person detection or post-grouping.To this end, RepParser decouples the parsing pipeline into instance-aware kernel generation and part-aware human parsing, which are responsible for instance separation and instance-specific part segmentation, respectively. In particular, we empower the parsing pipeline by representative parts, since they are characterized by instance-aware keypoints and can be utilized to dynamically parse each person instance. Specifically, representative parts are obtained by jointly localizing centers of instances and estimating keypoints of body part regions. After that, we dynamically predict instance-aware convolution kernels through representative parts, thus encoding person-part context into each kernel responsible for casting an image feature as an instance-specific representation.Furthermore, a multi-branch structure is adopted to divide each instance-specific representation into several part-aware representations for separate part segmentation.In this way, RepParser accordingly focuses on person instances with the guidance of representative parts and directly outputs parsing results for each person instance, thus eliminating the requirement of the prior detection or post-grouping.Extensive experiments on two challenging benchmarks demonstrate that our proposed RepParser is a simple yet effective framework and achieves very competitive performance.