 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenLKA: an open dataset of lane keeping assist from market autonomous vehicles
Jan 06, 2025



The Lane Keeping Assist (LKA) system has become a standard feature in recent car models. While marketed as providing auto-steering capabilities, the system's operational characteristics and safety performance remain underexplored, primarily due to a lack of real-world testing and comprehensive data. To fill this gap, we extensively tested mainstream LKA systems from leading U.S. automakers in Tampa, Florida. Using an innovative method, we collected a comprehensive dataset that includes full Controller Area Network (CAN) messages with LKA attributes, as well as video, perception, and lateral trajectory data from a high-quality front-facing camera equipped with advanced vision detection and trajectory planning algorithms. Our tests spanned diverse, challenging conditions, including complex road geometry, adverse weather, degraded lane markings, and their combinations. A vision language model (VLM) further annotated the videos to capture weather, lighting, and traffic features. Based on this dataset, we present an empirical overview of LKA's operational features and safety performance. Key findings indicate: (i) LKA is vulnerable to faint markings and low pavement contrast; (ii) it struggles in lane transitions (merges, diverges, intersections), often causing unintended departures or disengagements; (iii) steering torque limitations lead to frequent deviations on sharp turns, posing safety risks; and (iv) LKA systems consistently maintain rigid lane-centering, lacking adaptability on tight curves or near large vehicles such as trucks. We conclude by demonstrating how this dataset can guide both infrastructure planning and self-driving technology. In view of LKA's limitations, we recommend improvements in road geometry and pavement maintenance. Additionally, we illustrate how the dataset supports the development of human-like LKA systems via VLM fine-tuning and Chain of Thought reasoning.
Any Target Can be Offense: Adversarial Example Generation via Generalized Latent Infection
Jul 17, 2024Targeted adversarial attack, which aims to mislead a model to recognize any image as a target object by imperceptible perturbations, has become a mainstream tool for vulnerability assessment of deep neural networks (DNNs). Since existing targeted attackers only learn to attack known target classes, they cannot generalize well to unknown classes. To tackle this issue, we propose $\bf{G}$eneralized $\bf{A}$dversarial attac$\bf{KER}$ ($\bf{GAKer}$), which is able to construct adversarial examples to any target class. The core idea behind GAKer is to craft a latently infected representation during adversarial example generation. To this end, the extracted latent representations of the target object are first injected into intermediate features of an input image in an adversarial generator. Then, the generator is optimized to ensure visual consistency with the input image while being close to the target object in the feature space. Since the GAKer is class-agnostic yet model-agnostic, it can be regarded as a general tool that not only reveals the vulnerability of more DNNs but also identifies deficiencies of DNNs in a wider range of classes. Extensive experiments have demonstrated the effectiveness of our proposed method in generating adversarial examples for both known and unknown classes. Notably, compared with other generative methods, our method achieves an approximately $14.13\%$ higher attack success rate for unknown classes and an approximately $4.23\%$ higher success rate for known classes. Our code is available in https://github.com/VL-Group/GAKer.
Natural Color Fool: Towards Boosting Black-box Unrestricted Attacks
Oct 05, 2022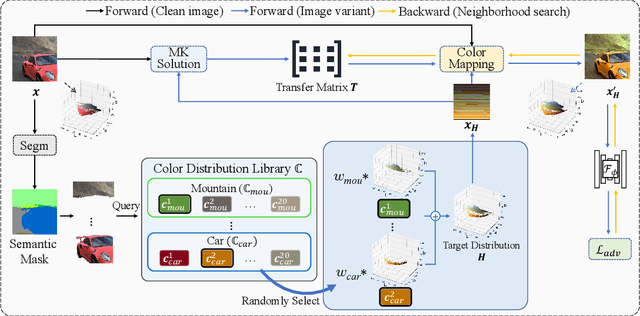
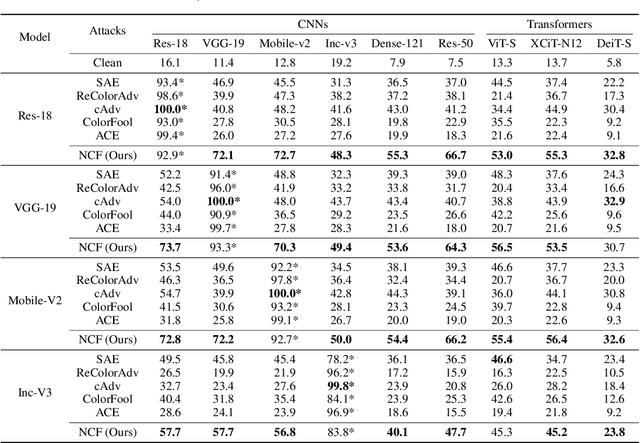

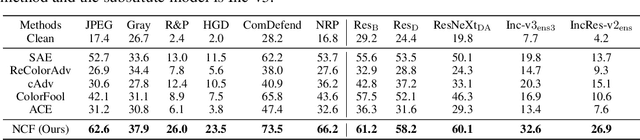
Unrestricted color attacks, which manipulate semantically meaningful color of an image, have shown their stealthiness and success in fooling both human eyes and deep neural networks. However, current works usually sacrifice the flexibility of the uncontrolled setting to ensure the naturalness of adversarial examples. As a result, the black-box attack performance of these methods is limited. To boost transferability of adversarial examples without damaging image quality, we propose a novel Natural Color Fool (NCF) which is guided by realistic color distributions sampled from a publicly available dataset and optimized by our neighborhood search and initialization reset. By conducting extensive experiments and visualizations, we convincingly demonstrate the effectiveness of our proposed method. Notably, on average, results show that our NCF can outperform state-of-the-art approaches by 15.0%$\sim$32.9% for fooling normally trained models and 10.0%$\sim$25.3% for evading defense methods. Our code is available at https://github.com/ylhz/Natural-Color-Fool.