 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafePTR: Token-Level Jailbreak Defense in Multimodal LLMs via Prune-then-Restore Mechanism
Jul 02, 2025By incorporating visual inputs, Multimodal Large Language Models (MLLMs) extend LLMs to support visual reasoning. However, this integration also introduces new vulnerabilities, making MLLMs susceptible to multimodal jailbreak attacks and hindering their safe deployment.Existing defense methods, including Image-to-Text Translation, Safe Prompting, and Multimodal Safety Tuning, attempt to address this by aligning multimodal inputs with LLMs' built-in safeguards.Yet, they fall short in uncovering root causes of multimodal vulnerabilities, particularly how harmful multimodal tokens trigger jailbreak in MLLMs? Consequently, they remain vulnerable to text-driven multimodal jailbreaks, often exhibiting overdefensive behaviors and imposing heavy training overhead.To bridge this gap, we present an comprehensive analysis of where, how and which harmful multimodal tokens bypass safeguards in MLLMs. Surprisingly, we find that less than 1% tokens in early-middle layers are responsible for inducing unsafe behaviors, highlighting the potential of precisely removing a small subset of harmful tokens, without requiring safety tuning, can still effectively improve safety against jailbreaks. Motivated by this, we propose Safe Prune-then-Restore (SafePTR), an training-free defense framework that selectively prunes harmful tokens at vulnerable layers while restoring benign features at subsequent layers.Without incurring additional computational overhead, SafePTR significantly enhances the safety of MLLMs while preserving efficiency. Extensive evaluations across three MLLMs and five benchmarks demonstrate SafePTR's state-of-the-art performance in mitigating jailbreak risks without compromising utility.
Attention Hijackers: Detect and Disentangle Attention Hijacking in LVLMs for Hallucination Mitigation
Mar 11, 2025



Despite their success, Large Vision-Language Models (LVLMs) remain vulnerable to hallucinations. While existing studies attribute the cause of hallucinations to insufficient visual attention to image tokens, our findings indicate that hallucinations also arise from interference from instruction tokens during decoding. Intuitively, certain instruction tokens continuously distort LVLMs' visual perception during decoding, hijacking their visual attention toward less discriminative visual regions. This distortion prevents them integrating broader contextual information from images, ultimately leading to hallucinations. We term this phenomenon 'Attention Hijacking', where disruptive instruction tokens act as 'Attention Hijackers'. To address this, we propose a novel, training-free strategy namely Attention HIjackers Detection and Disentanglement (AID), designed to isolate the influence of Hijackers, enabling LVLMs to rely on their context-aware intrinsic attention map. Specifically, AID consists of three components: First, Attention Hijackers Detection identifies Attention Hijackers by calculating instruction-driven visual salience. Next, Attention Disentanglement mechanism is proposed to mask the visual attention of these identified Hijackers, and thereby mitigate their disruptive influence on subsequent tokens. Finally, Re-Disentanglement recalculates the balance between instruction-driven and image-driven visual salience to avoid over-masking effects. Extensive experiments demonstrate that AID significantly reduces hallucination across various LVLMs on several benchmarks.
Alleviating Hallucinations in Large Vision-Language Models through Hallucination-Induced Optimization
May 24, 2024



Although Large Visual Language Models (LVLMs) have demonstrated exceptional abilities in understanding multimodal data, they invariably suffer from hallucinations, leading to a disconnect between the generated text and the corresponding images. Almost all current visual contrastive decoding methods attempt to mitigate these hallucinations by introducing visual uncertainty information that appropriately widens the contrastive logits gap between hallucinatory and targeted ones. However, due to uncontrollable nature of the global visual uncertainty, they struggle to precisely induce the hallucinatory tokens, which severely limits their effectiveness in mitigating hallucinations and may even lead to the generation of undesired hallucinations. To tackle this issue, we conducted the theoretical analysis to promote the effectiveness of contrast decoding. Building on this insight, we introduce a novel optimization strategy named Hallucination-Induced Optimization (HIO). This strategy seeks to amplify the contrast between hallucinatory and targeted tokens relying on a fine-tuned theoretical preference model (i.e., Contrary Bradley-Terry Model), thereby facilitating efficient contrast decoding to alleviate hallucinations in LVLMs. Extensive experimental research demonstrates that our HIO strategy can effectively reduce hallucinations in LVLMs, outperforming state-of-the-art methods across various benchmarks.
CIParsing: Unifying Causality Properties into Multiple Human Parsing
Aug 23, 2023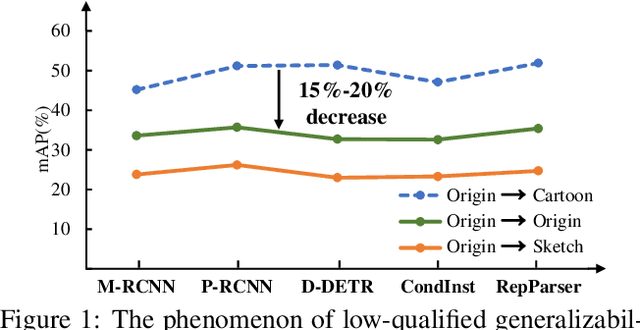
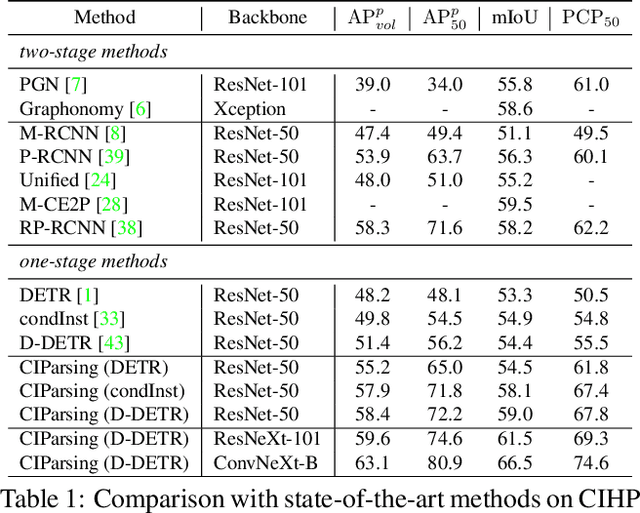
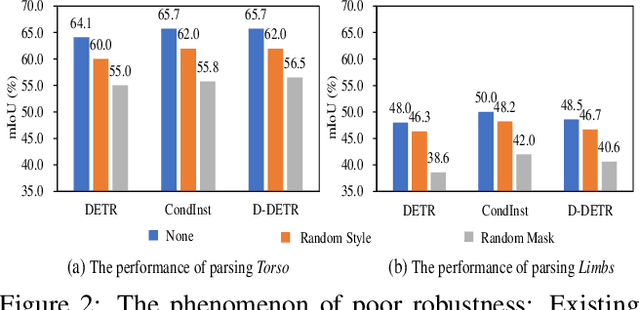
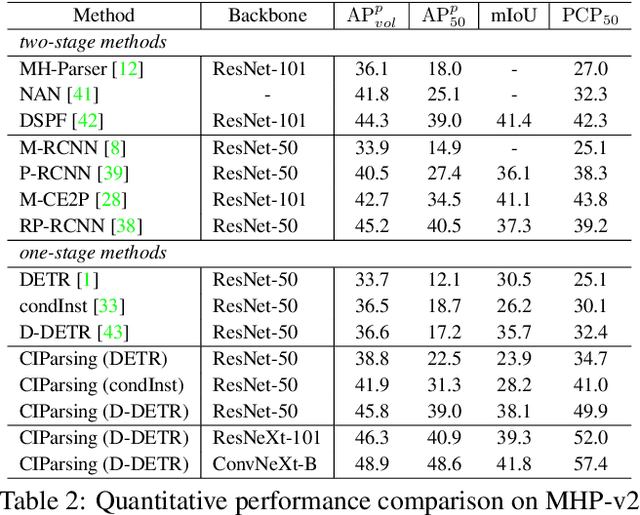
Existing methods of multiple human parsing (MHP) apply statistical models to acquire underlying associations between images and labeled body parts. However, acquired associations often contain many spurious correlations that degrade model generalization, leading statistical models to be vulnerable to visually contextual variations in images (e.g., unseen image styles/external interventions). To tackle this, we present a causality inspired parsing paradigm termed CIParsing, which follows fundamental causal principles involving two causal properties for human parsing (i.e., the causal diversity and the causal invariance). Specifically, we assume that an input image is constructed by a mix of causal factors (the characteristics of body parts) and non-causal factors (external contexts), where only the former ones cause the generation process of human parsing.Since causal/non-causal factors are unobservable, a human parser in proposed CIParsing is required to construct latent representations of causal factors and learns to enforce representations to satisfy the causal properties. In this way, the human parser is able to rely on causal factors w.r.t relevant evidence rather than non-causal factors w.r.t spurious correlations, thus alleviating model degradation and yielding improved parsing ability. Notably, the CIParsing is designed in a plug-and-play fashion and can be integrated into any existing MHP models. Extensive experiments conducted on two widely used benchmarks demonstrate the effectiveness and generalizability of our method.