 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIParsing: Unifying Causality Properties into Multiple Human Parsing
Aug 23, 2023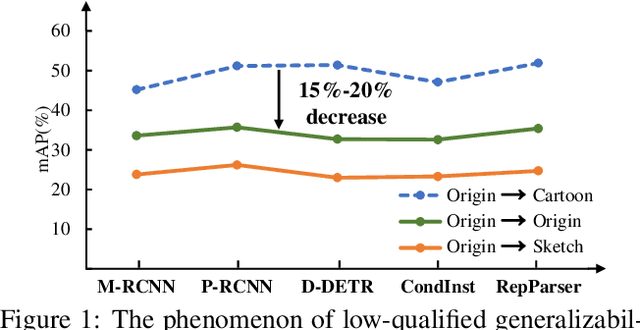
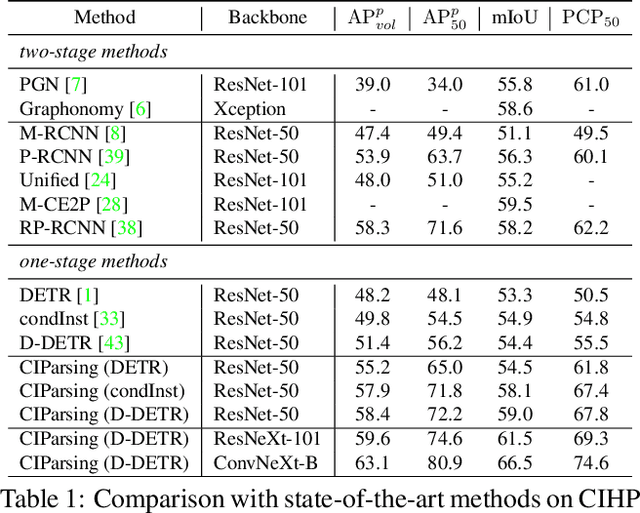
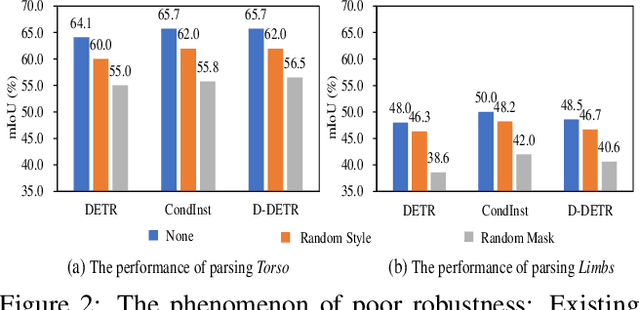
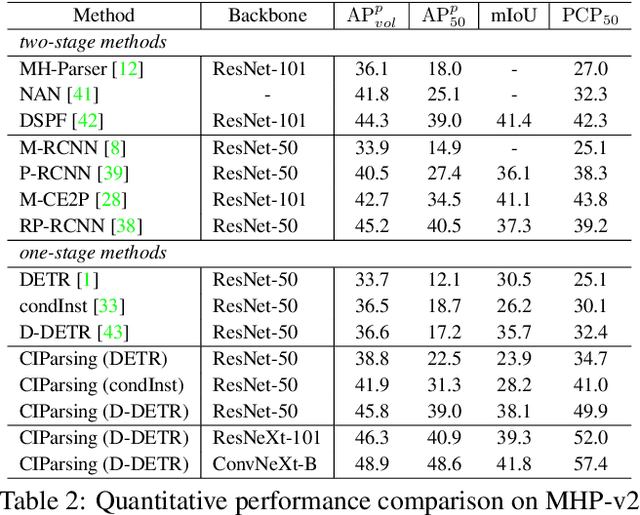
Existing methods of multiple human parsing (MHP) apply statistical models to acquire underlying associations between images and labeled body parts. However, acquired associations often contain many spurious correlations that degrade model generalization, leading statistical models to be vulnerable to visually contextual variations in images (e.g., unseen image styles/external interventions). To tackle this, we present a causality inspired parsing paradigm termed CIParsing, which follows fundamental causal principles involving two causal properties for human parsing (i.e., the causal diversity and the causal invariance). Specifically, we assume that an input image is constructed by a mix of causal factors (the characteristics of body parts) and non-causal factors (external contexts), where only the former ones cause the generation process of human parsing.Since causal/non-causal factors are unobservable, a human parser in proposed CIParsing is required to construct latent representations of causal factors and learns to enforce representations to satisfy the causal properties. In this way, the human parser is able to rely on causal factors w.r.t relevant evidence rather than non-causal factors w.r.t spurious correlations, thus alleviating model degradation and yielding improved parsing ability. Notably, the CIParsing is designed in a plug-and-play fashion and can be integrated into any existing MHP models. Extensive experiments conducted on two widely used benchmarks demonstrate the effectiveness and generalizability of our method.
RepParser: End-to-End Multiple Human Parsing with Representative Parts
Aug 27, 2022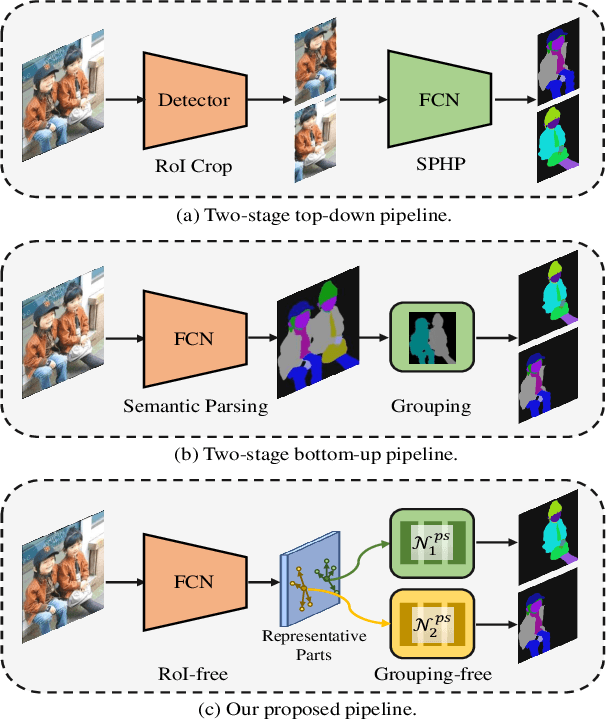
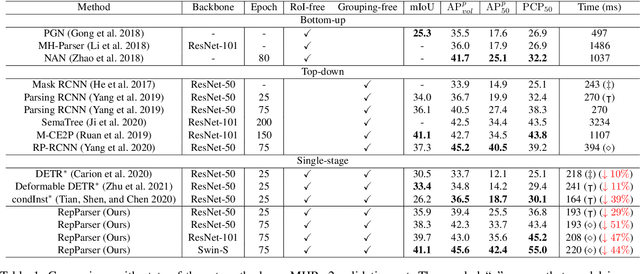
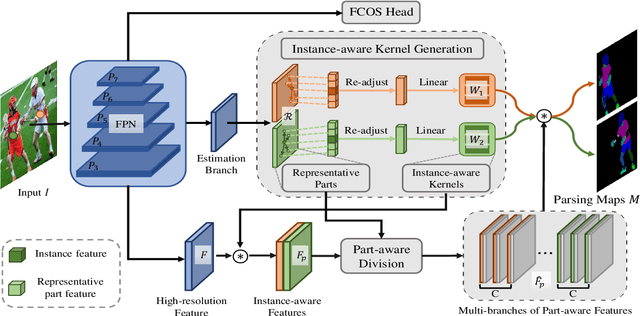
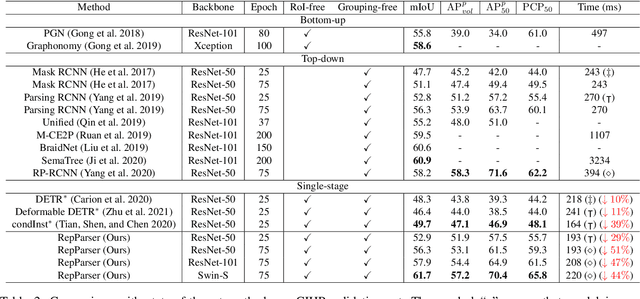
Existing methods of multiple human parsing usually adopt a two-stage strategy (typically top-down and bottom-up), which suffers from either strong dependence on prior detection or highly computational redundancy during post-grouping. In this work, we present an end-to-end multiple human parsing framework using representative parts, termed RepParser. Different from mainstream methods, RepParser solves the multiple human parsing in a new single-stage manner without resorting to person detection or post-grouping.To this end, RepParser decouples the parsing pipeline into instance-aware kernel generation and part-aware human parsing, which are responsible for instance separation and instance-specific part segmentation, respectively. In particular, we empower the parsing pipeline by representative parts, since they are characterized by instance-aware keypoints and can be utilized to dynamically parse each person instance. Specifically, representative parts are obtained by jointly localizing centers of instances and estimating keypoints of body part regions. After that, we dynamically predict instance-aware convolution kernels through representative parts, thus encoding person-part context into each kernel responsible for casting an image feature as an instance-specific representation.Furthermore, a multi-branch structure is adopted to divide each instance-specific representation into several part-aware representations for separate part segmentation.In this way, RepParser accordingly focuses on person instances with the guidance of representative parts and directly outputs parsing results for each person instance, thus eliminating the requirement of the prior detection or post-grouping.Extensive experiments on two challenging benchmarks demonstrate that our proposed RepParser is a simple yet effective framework and achieves very competitive performance.
KE-RCNN: Unifying Knowledge based Reasoning into Part-level Attribute Parsing
Jun 21, 2022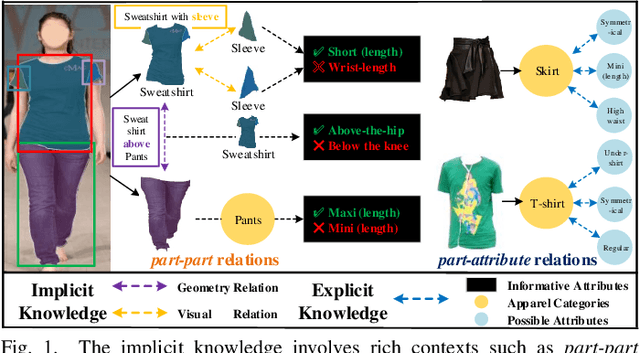
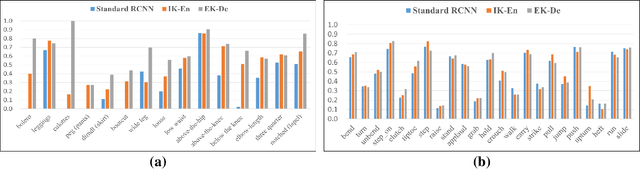
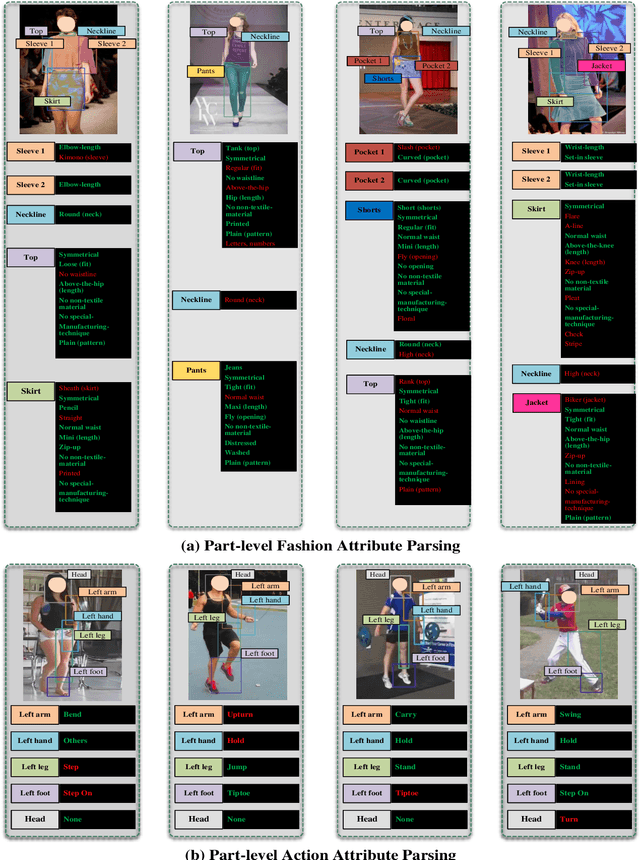
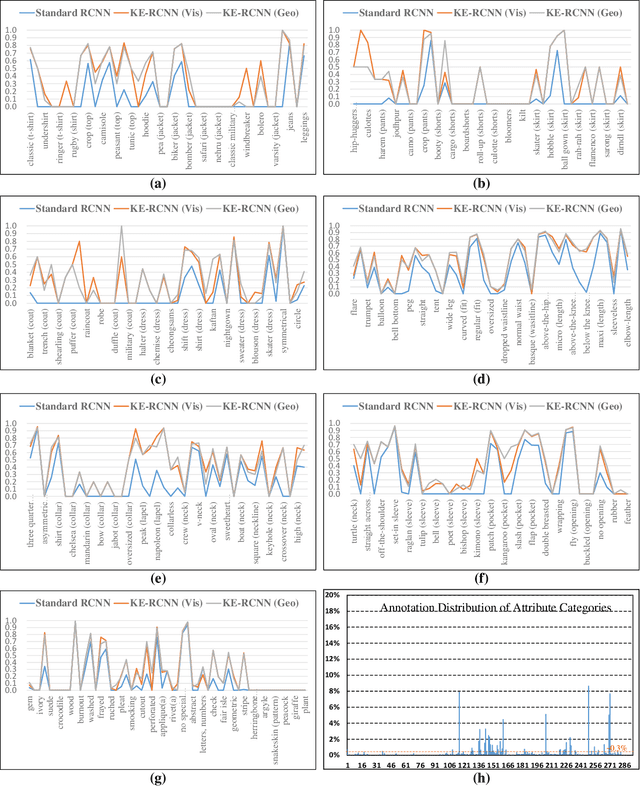
Part-level attribute parsing is a fundamental but challenging task, which requires the region-level visual understanding to provide explainable details of body parts. Most existing approaches address this problem by adding a regional convolutional neural network (RCNN) with an attribute prediction head to a two-stage detector, in which attributes of body parts are identified from local-wise part boxes. However, local-wise part boxes with limit visual clues (i.e., part appearance only) lead to unsatisfying parsing results, since attributes of body parts are highly dependent on comprehensive relations among them. In this article, we propose a Knowledge Embedded RCNN (KE-RCNN) to identify attributes by leveraging rich knowledges, including implicit knowledge (e.g., the attribute ``above-the-hip'' for a shirt requires visual/geometry relations of shirt-hip) and explicit knowledge (e.g., the part of ``shorts'' cannot have the attribute of ``hoodie'' or ``lining''). Specifically, the KE-RCNN consists of two novel components, i.e., Implicit Knowledge based Encoder (IK-En) and Explicit Knowledge based Decoder (EK-De). The former is designed to enhance part-level representation by encoding part-part relational contexts into part boxes, and the latter one is proposed to decode attributes with a guidance of prior knowledge about \textit{part-attribute} relations. In this way, the KE-RCNN is plug-and-play, which can be integrated into any two-stage detectors, e.g., Attribute-RCNN, Cascade-RCNN, HRNet based RCNN and SwinTransformer based RCNN. Extensive experiments conducted on two challenging benchmarks, e.g., Fashionpedia and Kinetics-TPS, demonstrate the effectiveness and generalizability of the KE-RCNN. In particular, it achieves higher improvements over all existing methods, reaching around 3% of AP on Fashionpedia and around 4% of Acc on Kinetics-TPS.
Technical Report: Disentangled Action Parsing Networks for Accurate Part-level Action Parsing
Nov 05, 2021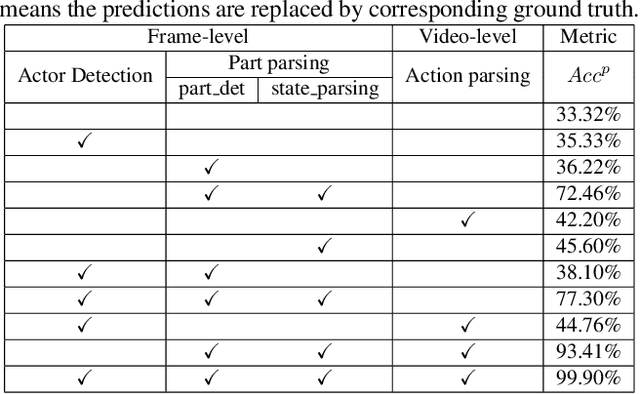
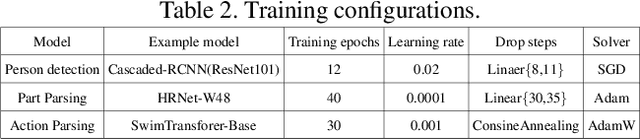


Part-level Action Parsing aims at part state parsing for boosting action recognition in videos. Despite of dramatic progresses in the area of video classification research, a severe problem faced by the community is that the detailed understanding of human actions is ignored. Our motivation is that parsing human actions needs to build models that focus on the specific problem. We present a simple yet effective approach, named disentangled action parsing (DAP). Specifically, we divided the part-level action parsing into three stages: 1) person detection, where a person detector is adopted to detect all persons from videos as well as performs instance-level action recognition; 2) Part parsing, where a part-parsing model is proposed to recognize human parts from detected person images; and 3) Action parsing, where a multi-modal action parsing network is used to parse action category conditioning on all detection results that are obtained from previous stages. With these three major models applied, our approach of DAP records a global mean of $0.605$ score in 2021 Kinetics-TPS Challenge.