 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnical Report: Disentangled Action Parsing Networks for Accurate Part-level Action Parsing
Paper and Code
Nov 05, 2021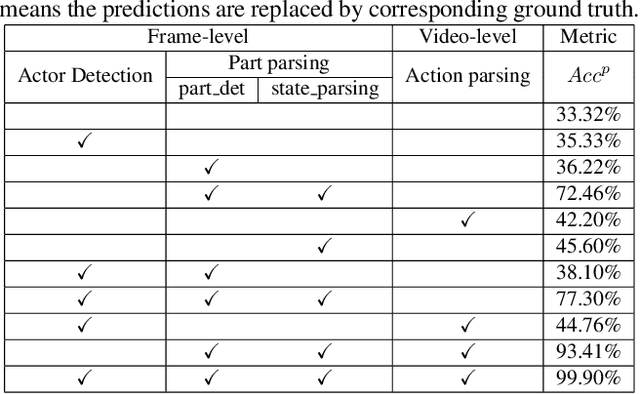
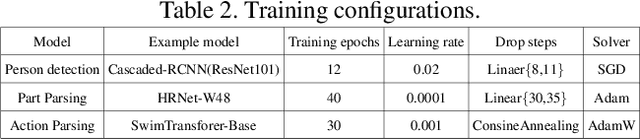


Part-level Action Parsing aims at part state parsing for boosting action recognition in videos. Despite of dramatic progresses in the area of video classification research, a severe problem faced by the community is that the detailed understanding of human actions is ignored. Our motivation is that parsing human actions needs to build models that focus on the specific problem. We present a simple yet effective approach, named disentangled action parsing (DAP). Specifically, we divided the part-level action parsing into three stages: 1) person detection, where a person detector is adopted to detect all persons from videos as well as performs instance-level action recognition; 2) Part parsing, where a part-parsing model is proposed to recognize human parts from detected person images; and 3) Action parsing, where a multi-modal action parsing network is used to parse action category conditioning on all detection results that are obtained from previous stages. With these three major models applied, our approach of DAP records a global mean of $0.605$ score in 2021 Kinetics-TPS Challenge.