 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepParser: End-to-End Multiple Human Parsing with Representative Parts
Paper and Code
Aug 27, 2022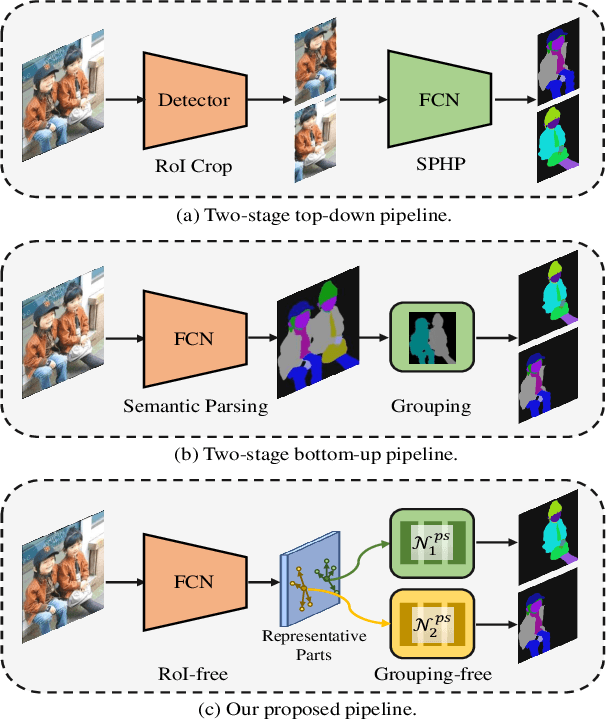
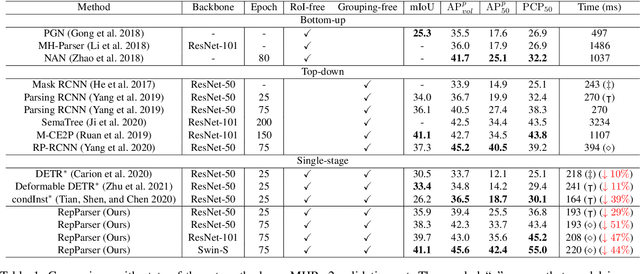
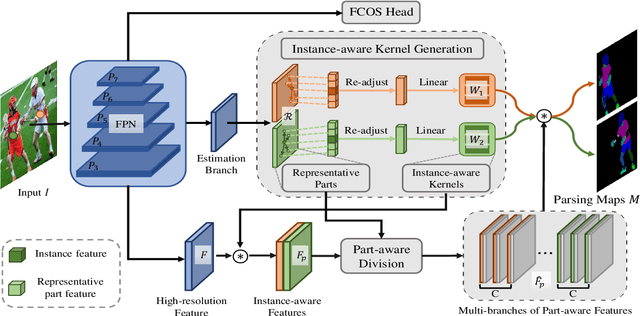
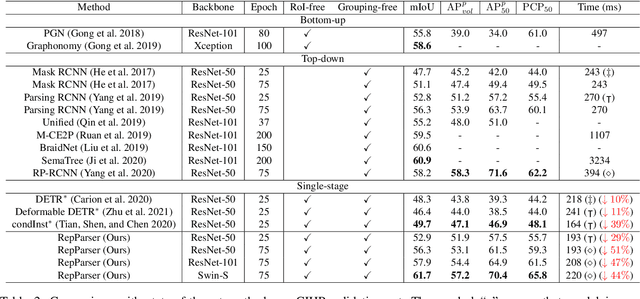
Existing methods of multiple human parsing usually adopt a two-stage strategy (typically top-down and bottom-up), which suffers from either strong dependence on prior detection or highly computational redundancy during post-grouping. In this work, we present an end-to-end multiple human parsing framework using representative parts, termed RepParser. Different from mainstream methods, RepParser solves the multiple human parsing in a new single-stage manner without resorting to person detection or post-grouping.To this end, RepParser decouples the parsing pipeline into instance-aware kernel generation and part-aware human parsing, which are responsible for instance separation and instance-specific part segmentation, respectively. In particular, we empower the parsing pipeline by representative parts, since they are characterized by instance-aware keypoints and can be utilized to dynamically parse each person instance. Specifically, representative parts are obtained by jointly localizing centers of instances and estimating keypoints of body part regions. After that, we dynamically predict instance-aware convolution kernels through representative parts, thus encoding person-part context into each kernel responsible for casting an image feature as an instance-specific representation.Furthermore, a multi-branch structure is adopted to divide each instance-specific representation into several part-aware representations for separate part segmentation.In this way, RepParser accordingly focuses on person instances with the guidance of representative parts and directly outputs parsing results for each person instance, thus eliminating the requirement of the prior detection or post-grouping.Extensive experiments on two challenging benchmarks demonstrate that our proposed RepParser is a simple yet effective framework and achieves very competitive performance.