 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafePTR: Token-Level Jailbreak Defense in Multimodal LLMs via Prune-then-Restore Mechanism
Jul 02, 2025By incorporating visual inputs, Multimodal Large Language Models (MLLMs) extend LLMs to support visual reasoning. However, this integration also introduces new vulnerabilities, making MLLMs susceptible to multimodal jailbreak attacks and hindering their safe deployment.Existing defense methods, including Image-to-Text Translation, Safe Prompting, and Multimodal Safety Tuning, attempt to address this by aligning multimodal inputs with LLMs' built-in safeguards.Yet, they fall short in uncovering root causes of multimodal vulnerabilities, particularly how harmful multimodal tokens trigger jailbreak in MLLMs? Consequently, they remain vulnerable to text-driven multimodal jailbreaks, often exhibiting overdefensive behaviors and imposing heavy training overhead.To bridge this gap, we present an comprehensive analysis of where, how and which harmful multimodal tokens bypass safeguards in MLLMs. Surprisingly, we find that less than 1% tokens in early-middle layers are responsible for inducing unsafe behaviors, highlighting the potential of precisely removing a small subset of harmful tokens, without requiring safety tuning, can still effectively improve safety against jailbreaks. Motivated by this, we propose Safe Prune-then-Restore (SafePTR), an training-free defense framework that selectively prunes harmful tokens at vulnerable layers while restoring benign features at subsequent layers.Without incurring additional computational overhead, SafePTR significantly enhances the safety of MLLMs while preserving efficiency. Extensive evaluations across three MLLMs and five benchmarks demonstrate SafePTR's state-of-the-art performance in mitigating jailbreak risks without compromising utility.
Attention Hijackers: Detect and Disentangle Attention Hijacking in LVLMs for Hallucination Mitigation
Mar 11, 2025Despite their success, Large Vision-Language Models (LVLMs) remain vulnerable to hallucinations. While existing studies attribute the cause of hallucinations to insufficient visual attention to image tokens, our findings indicate that hallucinations also arise from interference from instruction tokens during decoding. Intuitively, certain instruction tokens continuously distort LVLMs' visual perception during decoding, hijacking their visual attention toward less discriminative visual regions. This distortion prevents them integrating broader contextual information from images, ultimately leading to hallucinations. We term this phenomenon 'Attention Hijacking', where disruptive instruction tokens act as 'Attention Hijackers'. To address this, we propose a novel, training-free strategy namely Attention HIjackers Detection and Disentanglement (AID), designed to isolate the influence of Hijackers, enabling LVLMs to rely on their context-aware intrinsic attention map. Specifically, AID consists of three components: First, Attention Hijackers Detection identifies Attention Hijackers by calculating instruction-driven visual salience. Next, Attention Disentanglement mechanism is proposed to mask the visual attention of these identified Hijackers, and thereby mitigate their disruptive influence on subsequent tokens. Finally, Re-Disentanglement recalculates the balance between instruction-driven and image-driven visual salience to avoid over-masking effects. Extensive experiments demonstrate that AID significantly reduces hallucination across various LVLMs on several benchmarks.
ASER: Activation Smoothing and Error Reconstruction for Large Language Model Quantization
Nov 12, 2024Quantization stands as a pivotal technique for large language model (LLM) serving, yet it poses significant challenges particularly in achieving effective low-bit quantization. The limited numerical mapping makes the quantized model produce a non-trivial error, bringing out intolerable performance degration. This paper is anchored in the basic idea of model compression objectives, and delves into the layer-wise error distribution of LLMs during post-training quantization. Subsequently, we introduce ASER, an algorithm consisting of (1) Error Reconstruction: low-rank compensation for quantization error with LoRA-style matrices constructed by whitening SVD; (2) Activation Smoothing: outlier extraction to gain smooth activation and better error compensation. ASER is capable of quantizing typical LLMs to low-bit ones, particularly preserving accuracy even in W4A8 per-channel setup. Experimental results show that ASER is competitive among the state-of-the-art quantization algorithms, showing potential to activation quantization, with minor overhead.
Alleviating Hallucinations in Large Vision-Language Models through Hallucination-Induced Optimization
May 24, 2024



Although Large Visual Language Models (LVLMs) have demonstrated exceptional abilities in understanding multimodal data, they invariably suffer from hallucinations, leading to a disconnect between the generated text and the corresponding images. Almost all current visual contrastive decoding methods attempt to mitigate these hallucinations by introducing visual uncertainty information that appropriately widens the contrastive logits gap between hallucinatory and targeted ones. However, due to uncontrollable nature of the global visual uncertainty, they struggle to precisely induce the hallucinatory tokens, which severely limits their effectiveness in mitigating hallucinations and may even lead to the generation of undesired hallucinations. To tackle this issue, we conducted the theoretical analysis to promote the effectiveness of contrast decoding. Building on this insight, we introduce a novel optimization strategy named Hallucination-Induced Optimization (HIO). This strategy seeks to amplify the contrast between hallucinatory and targeted tokens relying on a fine-tuned theoretical preference model (i.e., Contrary Bradley-Terry Model), thereby facilitating efficient contrast decoding to alleviate hallucinations in LVLMs. Extensive experimental research demonstrates that our HIO strategy can effectively reduce hallucinations in LVLMs, outperforming state-of-the-art methods across various benchmarks.
Text-Video Retrieval with Global-Local Semantic Consistent Learning
May 21, 2024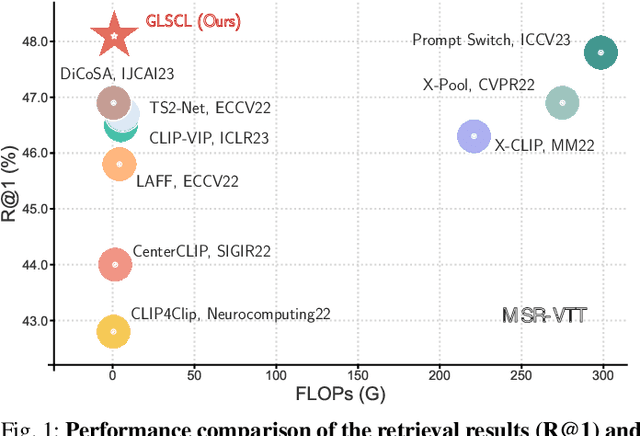
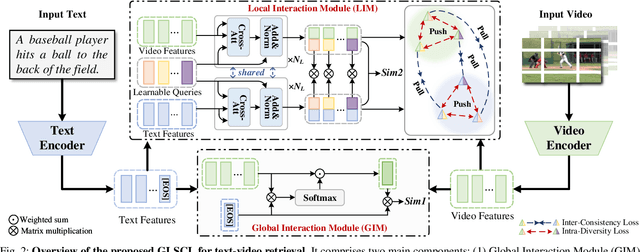
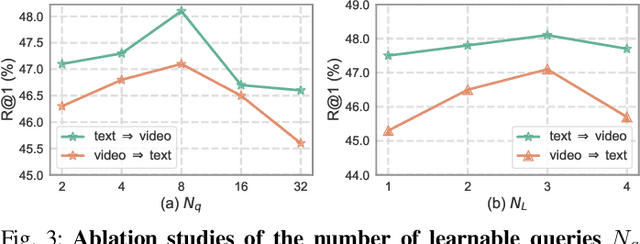
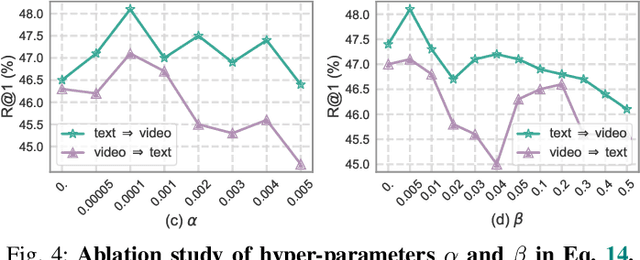
Adapting large-scale image-text pre-training models, e.g., CLIP, to the video domain represents the current state-of-the-art for text-video retrieval. The primary approaches involve transferring text-video pairs to a common embedding space and leveraging cross-modal interactions on specific entities for semantic alignment. Though effective, these paradigms entail prohibitive computational costs, leading to inefficient retrieval. To address this, we propose a simple yet effective method, Global-Local Semantic Consistent Learning (GLSCL), which capitalizes on latent shared semantics across modalities for text-video retrieval. Specifically, we introduce a parameter-free global interaction module to explore coarse-grained alignment. Then, we devise a shared local interaction module that employs several learnable queries to capture latent semantic concepts for learning fine-grained alignment. Furthermore, an Inter-Consistency Loss (ICL) is devised to accomplish the concept alignment between the visual query and corresponding textual query, and an Intra-Diversity Loss (IDL) is developed to repulse the distribution within visual (textual) queries to generate more discriminative concepts. Extensive experiments on five widely used benchmarks (i.e., MSR-VTT, MSVD, DiDeMo, LSMDC, and ActivityNet) substantiate the superior effectiveness and efficiency of the proposed method. Remarkably, our method achieves comparable performance with SOTA as well as being nearly 220 times faster in terms of computational cost. Code is available at: https://github.com/zchoi/GLSCL.
Context-based Transfer and Efficient Iterative Learning for Unbiased Scene Graph Generation
Dec 29, 2023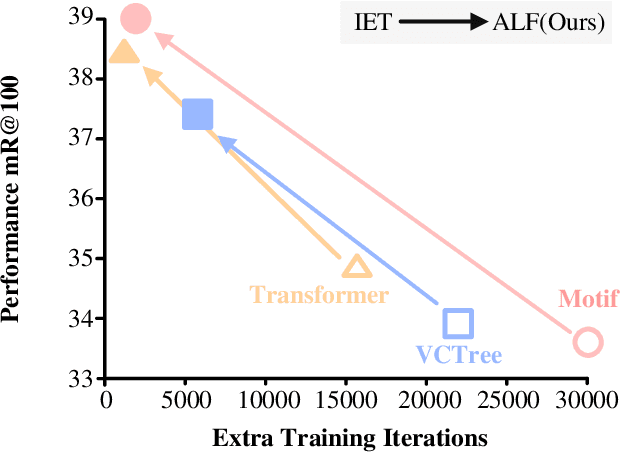
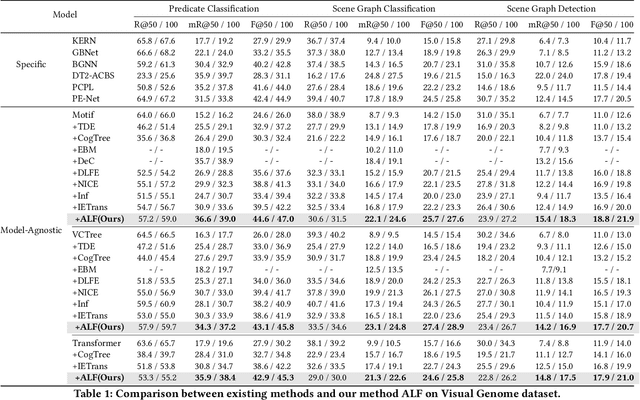
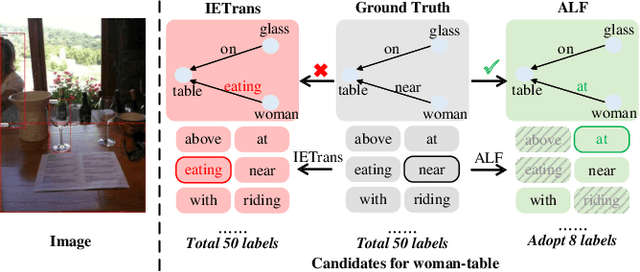
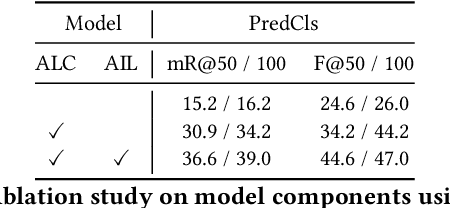
Unbiased Scene Graph Generation (USGG) aims to address biased predictions in SGG. To that end, data transfer methods are designed to convert coarse-grained predicates into fine-grained ones, mitigating imbalanced distribution. However, them overlook contextual relevance between transferred labels and subject-object pairs, such as unsuitability of 'eating' for 'woman-table'. Furthermore, they typically involve a two-stage process with significant computational costs, starting with pre-training a model for data transfer, followed by training from scratch using transferred labels. Thus, we introduce a plug-and-play method named CITrans, which iteratively trains SGG models with progressively enhanced data. First, we introduce Context-Restricted Transfer (CRT), which imposes subject-object constraints within predicates' semantic space to achieve fine-grained data transfer. Subsequently, Efficient Iterative Learning (EIL) iteratively trains models and progressively generates enhanced labels which are consistent with model's learning state, thereby accelerating the training process. Finally, extensive experiments show that CITrans achieves state-of-the-art and results with high efficiency.
Informative Scene Graph Generation via Debiasing
Aug 10, 2023Scene graph generation aims to detect visual relationship triplets, (subject, predicate, object). Due to biases in data, current models tend to predict common predicates, e.g. "on" and "at", instead of informative ones, e.g. "standing on" and "looking at". This tendency results in the loss of precise information and overall performance. If a model only uses "stone on road" rather than "stone blocking road" to describe an image, it may be a grave misunderstanding. We argue that this phenomenon is caused by two imbalances: semantic space level imbalance and training sample level imbalance. For this problem, we propose DB-SGG, an effective framework based on debiasing but not the conventional distribution fitting. It integrates two components: Semantic Debiasing (SD) and Balanced Predicate Learning (BPL), for these imbalances. SD utilizes a confusion matrix and a bipartite graph to construct predicate relationships. BPL adopts a random undersampling strategy and an ambiguity removing strategy to focus on informative predicates. Benefiting from the model-agnostic process, our method can be easily applied to SGG models and outperforms Transformer by 136.3%, 119.5%, and 122.6% on mR@20 at three SGG sub-tasks on the SGG-VG dataset. Our method is further verified on another complex SGG dataset (SGG-GQA) and two downstream tasks (sentence-to-graph retrieval and image captioning).
Local-Global Information Interaction Debiasing for Dynamic Scene Graph Generation
Aug 10, 2023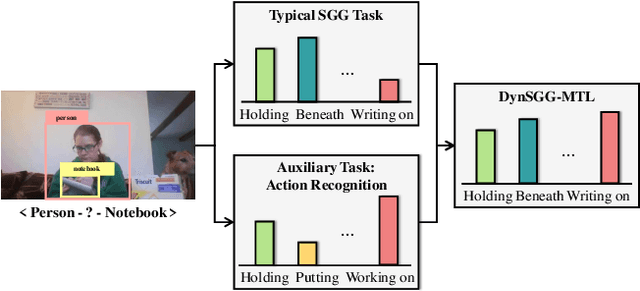
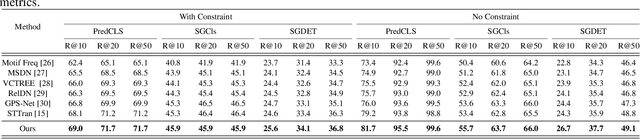
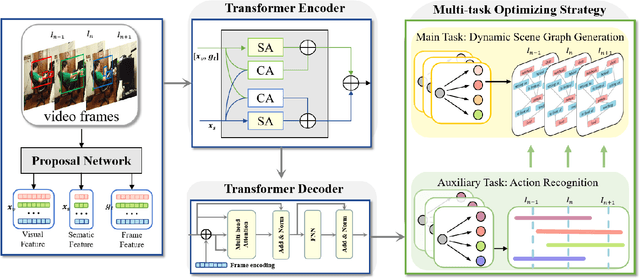
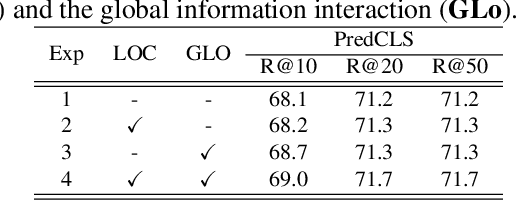
The task of dynamic scene graph generation (DynSGG) aims to generate scene graphs for given videos, which involves modeling the spatial-temporal information in the video. However, due to the long-tailed distribution of samples in the dataset, previous DynSGG models fail to predict the tail predicates. We argue that this phenomenon is due to previous methods that only pay attention to the local spatial-temporal information and neglect the consistency of multiple frames. To solve this problem, we propose a novel DynSGG model based on multi-task learning, DynSGG-MTL, which introduces the local interaction information and global human-action interaction information. The interaction between objects and frame features makes the model more fully understand the visual context of the single image. Long-temporal human actions supervise the model to generate multiple scene graphs that conform to the global constraints and avoid the model being unable to learn the tail predicates. Extensive experiments on Action Genome dataset demonstrate the efficacy of our proposed framework, which not only improves the dynamic scene graph generation but also alleviates the long-tail problem.
Generalized Unbiased Scene Graph Generation
Aug 09, 2023Existing Unbiased Scene Graph Generation (USGG) methods only focus on addressing the predicate-level imbalance that high-frequency classes dominate predictions of rare ones, while overlooking the concept-level imbalance. Actually, even if predicates themselves are balanced, there is still a significant concept-imbalance within them due to the long-tailed distribution of contexts (i.e., subject-object combinations). This concept-level imbalance poses a more pervasive and challenging issue compared to the predicate-level imbalance since subject-object pairs are inherently complex in combinations. Hence, we introduce a novel research problem: Generalized Unbiased Scene Graph Generation (G-USGG), which takes into account both predicate-level and concept-level imbalance. To the end, we propose the Multi-Concept Learning (MCL) framework, which ensures a balanced learning process across rare/ uncommon/ common concepts. MCL first quantifies the concept-level imbalance across predicates in terms of different amounts of concepts, representing as multiple concept-prototypes within the same class. It then effectively learns concept-prototypes by applying the Concept Regularization (CR) technique. Furthermore, to achieve balanced learning over different concepts, we introduce the Balanced Prototypical Memory (BPM), which guides SGG models to generate balanced representations for concept-prototypes. Extensive experiments demonstrate the remarkable efficacy of our model-agnostic strategy in enhancing the performance of benchmark models on both VG-SGG and OI-SGG datasets, leading to new state-of-the-art achievements in two key aspects: predicate-level unbiased relation recognition and concept-level compositional generability.
Prototype-based Embedding Network for Scene Graph Generation
Mar 13, 2023Current Scene Graph Generation (SGG) methods explore contextual information to predict relationships among entity pairs. However, due to the diverse visual appearance of numerous possible subject-object combinations, there is a large intra-class variation within each predicate category, e.g., "man-eating-pizza, giraffe-eating-leaf", and the severe inter-class similarity between different classes, e.g., "man-holding-plate, man-eating-pizza", in model's latent space. The above challenges prevent current SGG methods from acquiring robust features for reliable relation prediction. In this paper, we claim that the predicate's category-inherent semantics can serve as class-wise prototypes in the semantic space for relieving the challenges. To the end, we propose the Prototype-based Embedding Network (PE-Net), which models entities/predicates with prototype-aligned compact and distinctive representations and thereby establishes matching between entity pairs and predicates in a common embedding space for relation recognition. Moreover, Prototype-guided Learning (PL) is introduced to help PE-Net efficiently learn such entitypredicate matching, and Prototype Regularization (PR) is devised to relieve the ambiguous entity-predicate matching caused by the predicate's semantic overlap. Extensive experiments demonstrate that our method gains superior relation recognition capability on SGG, achieving new state-of-the-art performances on both Visual Genome and Open Images datasets.