 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototype-based Embedding Network for Scene Graph Generation
Mar 13, 2023Current Scene Graph Generation (SGG) methods explore contextual information to predict relationships among entity pairs. However, due to the diverse visual appearance of numerous possible subject-object combinations, there is a large intra-class variation within each predicate category, e.g., "man-eating-pizza, giraffe-eating-leaf", and the severe inter-class similarity between different classes, e.g., "man-holding-plate, man-eating-pizza", in model's latent space. The above challenges prevent current SGG methods from acquiring robust features for reliable relation prediction. In this paper, we claim that the predicate's category-inherent semantics can serve as class-wise prototypes in the semantic space for relieving the challenges. To the end, we propose the Prototype-based Embedding Network (PE-Net), which models entities/predicates with prototype-aligned compact and distinctive representations and thereby establishes matching between entity pairs and predicates in a common embedding space for relation recognition. Moreover, Prototype-guided Learning (PL) is introduced to help PE-Net efficiently learn such entitypredicate matching, and Prototype Regularization (PR) is devised to relieve the ambiguous entity-predicate matching caused by the predicate's semantic overlap. Extensive experiments demonstrate that our method gains superior relation recognition capability on SGG, achieving new state-of-the-art performances on both Visual Genome and Open Images datasets.
Dual-branch Hybrid Learning Network for Unbiased Scene Graph Generation
Jul 16, 2022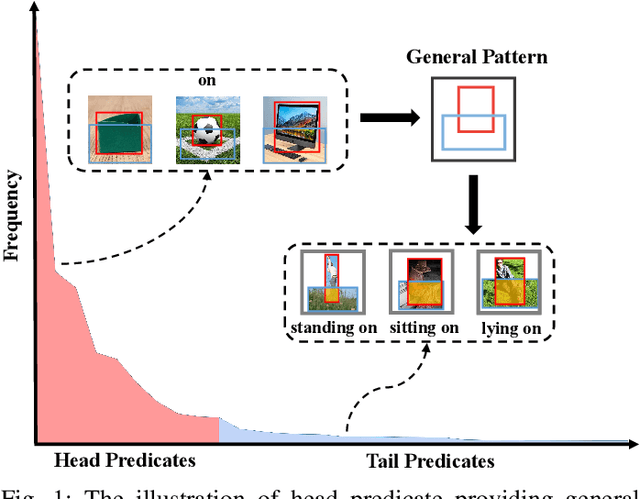
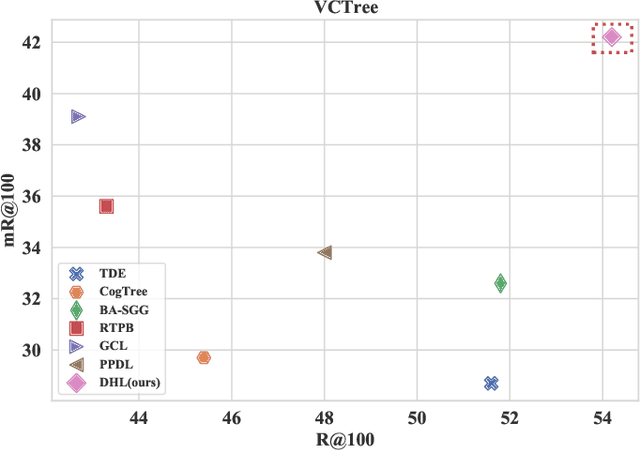
The current studies of Scene Graph Generation (SGG) focus on solving the long-tailed problem for generating unbiased scene graphs. However, most de-biasing methods overemphasize the tail predicates and underestimate head ones throughout training, thereby wrecking the representation ability of head predicate features. Furthermore, these impaired features from head predicates harm the learning of tail predicates. In fact, the inference of tail predicates heavily depends on the general patterns learned from head ones, e.g., "standing on" depends on "on". Thus, these de-biasing SGG methods can neither achieve excellent performance on tail predicates nor satisfying behaviors on head ones. To address this issue, we propose a Dual-branch Hybrid Learning network (DHL) to take care of both head predicates and tail ones for SGG, including a Coarse-grained Learning Branch (CLB) and a Fine-grained Learning Branch (FLB). Specifically, the CLB is responsible for learning expertise and robust features of head predicates, while the FLB is expected to predict informative tail predicates. Furthermore, DHL is equipped with a Branch Curriculum Schedule (BCS) to make the two branches work well together. Experiments show that our approach achieves a new state-of-the-art performance on VG and GQA datasets and makes a trade-off between the performance of tail predicates and head ones. Moreover, extensive experiments on two downstream tasks (i.e., Image Captioning and Sentence-to-Graph Retrieval) further verify the generalization and practicability of our method.
Learning To Generate Scene Graph from Head to Tail
Jun 23, 2022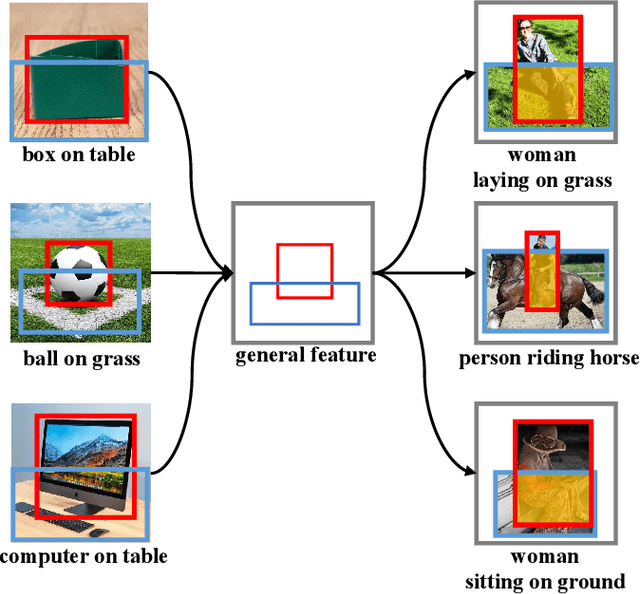
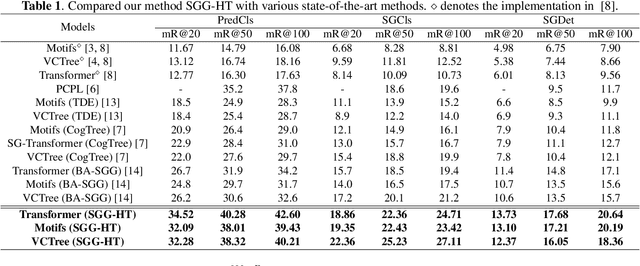
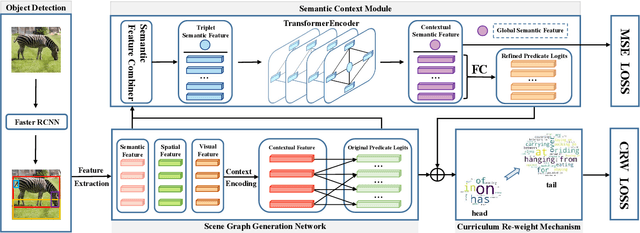
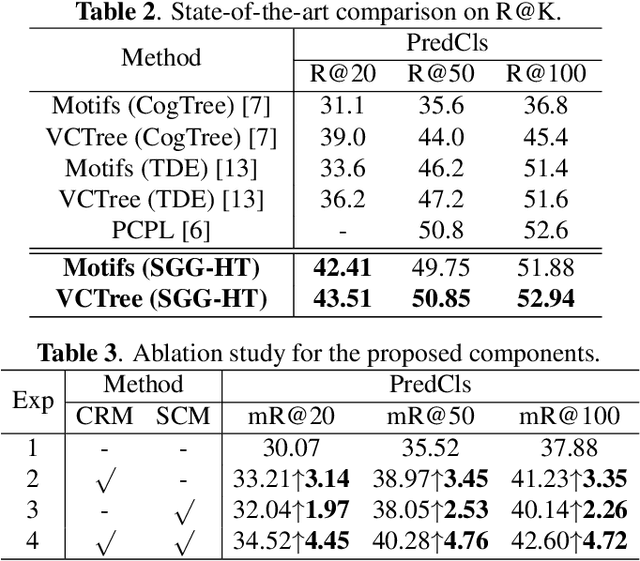
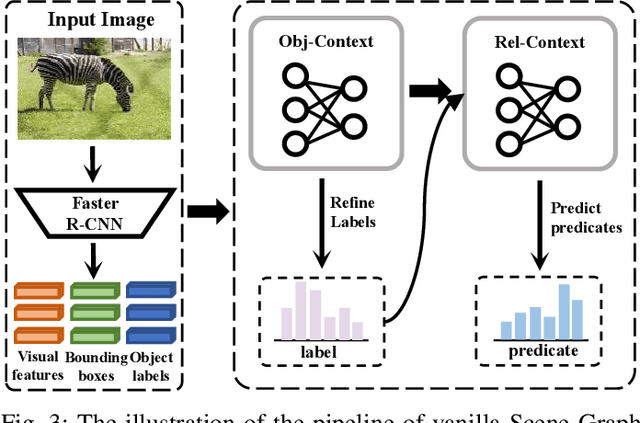
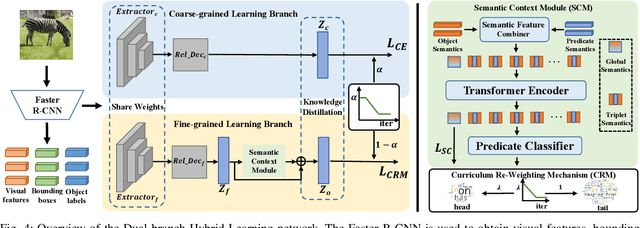
Scene Graph Generation (SGG) represents objects and their interactions with a graph structure. Recently, many works are devoted to solving the imbalanced problem in SGG. However, underestimating the head predicates in the whole training process, they wreck the features of head predicates that provide general features for tail ones. Besides, assigning excessive attention to the tail predicates leads to semantic deviation. Based on this, we propose a novel SGG framework, learning to generate scene graphs from Head to Tail (SGG-HT), containing Curriculum Re-weight Mechanism (CRM) and Semantic Context Module (SCM). CRM learns head/easy samples firstly for robust features of head predicates and then gradually focuses on tail/hard ones. SCM is proposed to relieve semantic deviation by ensuring the semantic consistency between the generated scene graph and the ground truth in global and local representations. Experiments show that SGG-HT significantly alleviates the biased problem and chieves state-of-the-art performances on Visual Genome.