 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Video Retrieval with Global-Local Semantic Consistent Learning
Paper and Code
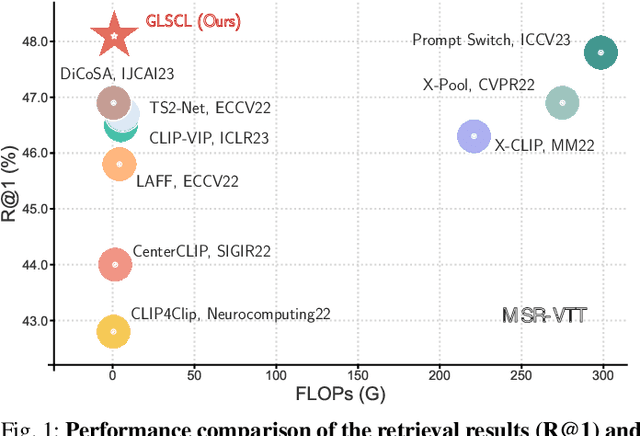
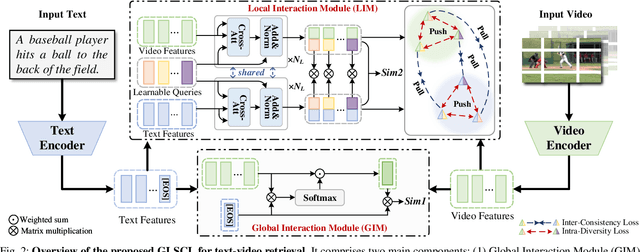
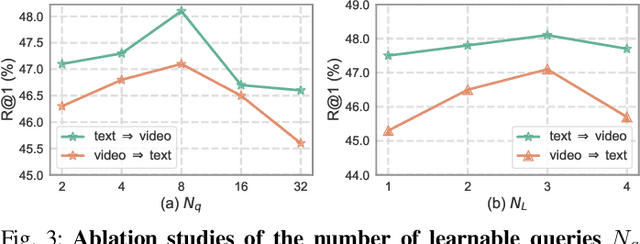
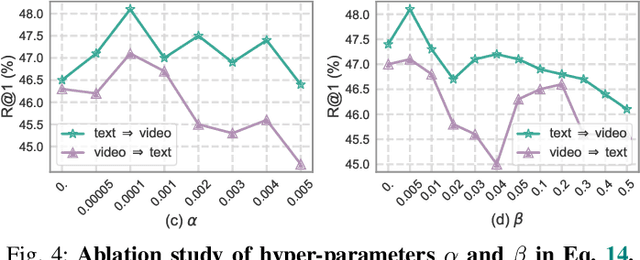
Adapting large-scale image-text pre-training models, e.g., CLIP, to the video domain represents the current state-of-the-art for text-video retrieval. The primary approaches involve transferring text-video pairs to a common embedding space and leveraging cross-modal interactions on specific entities for semantic alignment. Though effective, these paradigms entail prohibitive computational costs, leading to inefficient retrieval. To address this, we propose a simple yet effective method, Global-Local Semantic Consistent Learning (GLSCL), which capitalizes on latent shared semantics across modalities for text-video retrieval. Specifically, we introduce a parameter-free global interaction module to explore coarse-grained alignment. Then, we devise a shared local interaction module that employs several learnable queries to capture latent semantic concepts for learning fine-grained alignment. Furthermore, an Inter-Consistency Loss (ICL) is devised to accomplish the concept alignment between the visual query and corresponding textual query, and an Intra-Diversity Loss (IDL) is developed to repulse the distribution within visual (textual) queries to generate more discriminative concepts. Extensive experiments on five widely used benchmarks (i.e., MSR-VTT, MSVD, DiDeMo, LSMDC, and ActivityNet) substantiate the superior effectiveness and efficiency of the proposed method. Remarkably, our method achieves comparable performance with SOTA as well as being nearly 220 times faster in terms of computational cost. Code is available at: https://github.com/zchoi/GLSCL.