 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Learning Improves Implicit Neural Representations for Medical Reconstruction
May 05, 2026Implicit neural representations (INRs) have emerged as a powerful paradigm for medical imaging via physics-informed unsupervised learning. Classical INRs optimize an entire network from scratch for each subject, leading to inefficient training and suboptimal imaging quality. Recent initialization-based approaches attempt to inject population priors into pre-trained networks, yet they rely on high-quality images and often suffer from catastrophic forgetting during fine-tuning. We present DisINR, a novel INR framework that explicitly disentangles shared and subject-specific representations. DisINR introduces a shared encoder-decoder pair and subject-specific encoders, whose features are jointly decoded for image reconstruction. By integrating differentiable forward models, it pre-trains the shared modules directly from limited raw measurements, removing the need for pre-acquired high-quality images. During test-time adaptation, only the subject-specific encoder is optimized, while the shared pair remains frozen, effectively preserving learned priors. Extensive evaluations on three representative medical imaging tasks show that DisINR significantly outperforms state-of-the-art INRs in both reconstruction accuracy and efficiency.
Periodic Steady-State Control of a Handkerchief-Spinning Task Using a Parallel Anti-Parallelogram Tendon-driven Wrist
Apr 20, 2026Spinning flexible objects, exemplified by traditional Chinese handkerchief performances, demands periodic steady-state motions under nonlinear dynamics with frictional contacts and boundary constraints. To address these challenges, we first design an intuitive dexterous wrist based on a parallel anti-parallelogram tendon-driven structure, which achieves 90 degrees omnidirectional rotation with low inertia and decoupled roll-pitch sensing, and implement a high-low level hierarchical control scheme. We then develop a particle-spring model of the handkerchief for control-oriented abstraction and strategy evaluation. Hardware experiments validate this framework, achieving an unfolding ratio of approximately 99% and fingertip tracking error of RMSE = 2.88 mm in high-dynamic spinning. These results demonstrate that integrating control-oriented modeling with a task-tailored dexterous wrist enables robust rest-to-steady-state transitions and precise periodic manipulation of highly flexible objects. More visualizations: https://slowly1113.github.io/icra2026-handkerchief/
Grounded World Model for Semantically Generalizable Planning
Apr 13, 2026In Model Predictive Control (MPC), world models predict the future outcomes of various action proposals, which are then scored to guide the selection of the optimal action. For visuomotor MPC, the score function is a distance metric between a predicted image and a goal image, measured in the latent space of a pretrained vision encoder like DINO and JEPA. However, it is challenging to obtain the goal image in advance of the task execution, particularly in new environments. Additionally, conveying the goal through an image offers limited interactivity compared with natural language. In this work, we propose to learn a Grounded World Model (GWM) in a vision-language-aligned latent space. As a result, each proposed action is scored based on how close its future outcome is to the task instruction, reflected by the similarity of embeddings. This approach transforms the visuomotor MPC to a VLA that surpasses VLM-based VLAs in semantic generalization. On the proposed WISER benchmark, GWM-MPC achieves a 87% success rate on the test set comprising 288 tasks that feature unseen visual signals and referring expressions, yet remain solvable with motions demonstrated during training. In contrast, traditional VLAs achieve an average success rate of 22%, even though they overfit the training set with a 90% success rate.
Zero-shot Low-Field MRI Enhancement via Diffusion-Based Adaptive Contrast Transport
Mar 02, 2026Low-field (LF) magnetic resonance imaging (MRI) democratizes access to diagnostic imaging but is fundamentally limited by low signal-to-noise ratio and significant tissue contrast distortion due to field-dependent relaxation dynamics. Reconstructing high-field (HF) quality images from LF data is a blind inverse problem, severely challenged by the scarcity of paired training data and the unknown, non-linear contrast transformation operator. Existing zero-shot methods, which assume simplified linear degradation, often fail to recover authentic tissue contrast. In this paper, we propose DACT(Diffusion-Based Adaptive Contrast Transport), a novel zero-shot framework that restores HF-quality images without paired supervision. DACT synergizes a pre-trained HF diffusion prior to ensure anatomical fidelity with a physically-informed adaptive forward model. Specifically, we introduce a differentiable Sinkhorn optimal transport module that explicitly models and corrects the intensity distribution shift between LF and HF domains during the reverse diffusion process. This allows the framework to dynamically learn the intractable contrast mapping while preserving topological consistency. Extensive experiments on simulated and real clinical LF datasets demonstrate that DACT achieves state-of-the-art performance, yielding reconstructions with superior structural detail and correct tissue contrast.
Token Reduction via Local and Global Contexts Optimization for Efficient Video Large Language Models
Mar 02, 2026Video Large Language Models (VLLMs) demonstrate strong video understanding but suffer from inefficiency due to redundant visual tokens. Existing pruning primary targets intra-frame spatial redundancy or prunes inside the LLM with shallow-layer overhead, yielding suboptimal spatiotemporal reduction and underutilizing long-context compressibility. All of them often discard subtle yet informative context from merged or pruned tokens. In this paper, we propose a new perspective that elaborates token \textbf{A}nchors within intra-frame and inter-frame to comprehensively aggregate the informative contexts via local-global \textbf{O}ptimal \textbf{T}ransport (\textbf{AOT}). Specifically, we first establish local- and global-aware token anchors within each frame under the attention guidance, which then optimal transport aggregates the informative contexts from pruned tokens, constructing intra-frame token anchors. Then, building on the temporal frame clips, the first frame within each clip will be considered as the keyframe anchors to ensemble similar information from consecutive frames through optimal transport, while keeping distinct tokens to represent temporal dynamics, leading to efficient token reduction in a training-free manner. Extensive evaluations show that our proposed AOT obtains competitive performances across various short- and long-video benchmarks on leading video LLMs, obtaining substantial computational efficiency while preserving temporal and visual fidelity. Project webpage: \href{https://tyroneli.github.io/AOT}{AOT}.
LLM-VA: Resolving the Jailbreak-Overrefusal Trade-off via Vector Alignment
Jan 27, 2026Safety-aligned LLMs suffer from two failure modes: jailbreak (answering harmful inputs) and over-refusal (declining benign queries). Existing vector steering methods adjust the magnitude of answer vectors, but this creates a fundamental trade-off -- reducing jailbreak increases over-refusal and vice versa. We identify the root cause: LLMs encode the decision to answer (answer vector $v_a$) and the judgment of input safety (benign vector $v_b$) as nearly orthogonal directions, treating them as independent processes. We propose LLM-VA, which aligns $v_a$ with $v_b$ through closed-form weight updates, making the model's willingness to answer causally dependent on its safety assessment -- without fine-tuning or architectural changes. Our method identifies vectors at each layer using SVMs, selects safety-relevant layers, and iteratively aligns vectors via minimum-norm weight modifications. Experiments on 12 LLMs demonstrate that LLM-VA achieves 11.45% higher F1 than the best baseline while preserving 95.92% utility, and automatically adapts to each model's safety bias without manual tuning. Code and models are available at https://hotbento.github.io/LLM-VA-Web/.
ArenaRL: Scaling RL for Open-Ended Agents via Tournament-based Relative Ranking
Jan 10, 2026Reinforcement learning has substantially improved the performance of LLM agents on tasks with verifiable outcomes, but it still struggles on open-ended agent tasks with vast solution spaces (e.g., complex travel planning). Due to the absence of objective ground-truth for these tasks, current RL algorithms largely rely on reward models that assign scalar scores to individual responses. We contend that such pointwise scoring suffers from an inherent discrimination collapse: the reward model struggles to distinguish subtle advantages among different trajectories, resulting in scores within a group being compressed into a narrow range. Consequently, the effective reward signal becomes dominated by noise from the reward model, leading to optimization stagnation. To address this, we propose ArenaRL, a reinforcement learning paradigm that shifts from pointwise scalar scoring to intra-group relative ranking. ArenaRL introduces a process-aware pairwise evaluation mechanism, employing multi-level rubrics to assign fine-grained relative scores to trajectories. Additionally, we construct an intra-group adversarial arena and devise a tournament-based ranking scheme to obtain stable advantage signals. Empirical results confirm that the built seeded single-elimination scheme achieves nearly equivalent advantage estimation accuracy to full pairwise comparisons with O(N^2) complexity, while operating with only O(N) complexity, striking an optimal balance between efficiency and precision. Furthermore, to address the lack of full-cycle benchmarks for open-ended agents, we build Open-Travel and Open-DeepResearch, two high-quality benchmarks featuring a comprehensive pipeline covering SFT, RL training, and multi-dimensional evaluation. Extensive experiments show that ArenaRL substantially outperforms standard RL baselines, enabling LLM agents to generate more robust solutions for complex real-world tasks.
LightKG: Efficient Knowledge-Aware Recommendations with Simplified GNN Architecture
Jun 12, 2025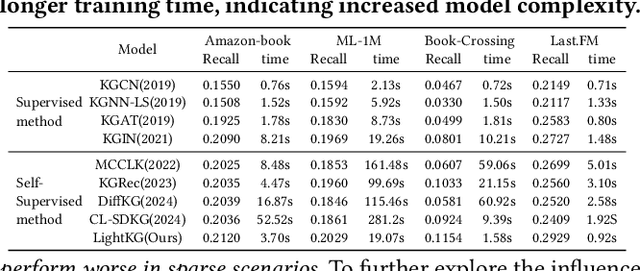

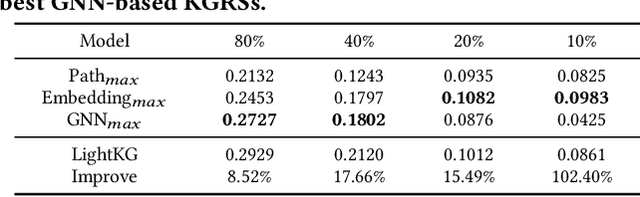
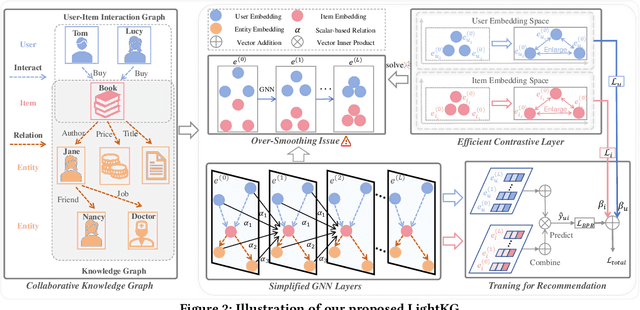
Recently, Graph Neural Networks (GNNs) have become the dominant approach for Knowledge Graph-aware Recommender Systems (KGRSs) due to their proven effectiveness. Building upon GNN-based KGRSs, Self-Supervised Learning (SSL) has been incorporated to address the sparity issue, leading to longer training time. However, through extensive experiments, we reveal that: (1)compared to other KGRSs, the existing GNN-based KGRSs fail to keep their superior performance under sparse interactions even with SSL. (2) More complex models tend to perform worse in sparse interaction scenarios and complex mechanisms, like attention mechanism, can be detrimental as they often increase learning difficulty. Inspired by these findings, we propose LightKG, a simple yet powerful GNN-based KGRS to address sparsity issues. LightKG includes a simplified GNN layer that encodes directed relations as scalar pairs rather than dense embeddings and employs a linear aggregation framework, greatly reducing the complexity of GNNs. Additionally, LightKG incorporates an efficient contrastive layer to implement SSL. It directly minimizes the node similarity in original graph, avoiding the time-consuming subgraph generation and comparison required in previous SSL methods. Experiments on four benchmark datasets show that LightKG outperforms 12 competitive KGRSs in both sparse and dense scenarios while significantly reducing training time. Specifically, it surpasses the best baselines by an average of 5.8\% in recommendation accuracy and saves 84.3\% of training time compared to KGRSs with SSL. Our code is available at https://github.com/1371149/LightKG.
Low-Rank Augmented Implicit Neural Representation for Unsupervised High-Dimensional Quantitative MRI Reconstruction
Jun 10, 2025Quantitative magnetic resonance imaging (qMRI) provides tissue-specific parameters vital for clinical diagnosis. Although simultaneous multi-parametric qMRI (MP-qMRI) technologies enhance imaging efficiency, robustly reconstructing qMRI from highly undersampled, high-dimensional measurements remains a significant challenge. This difficulty arises primarily because current reconstruction methods that rely solely on a single prior or physics-informed model to solve the highly ill-posed inverse problem, which often leads to suboptimal results. To overcome this limitation, we propose LoREIN, a novel unsupervised and dual-prior-integrated framework for accelerated 3D MP-qMRI reconstruction. Technically, LoREIN incorporates both low-rank prior and continuity prior via low-rank representation (LRR) and implicit neural representation (INR), respectively, to enhance reconstruction fidelity. The powerful continuous representation of INR enables the estimation of optimal spatial bases within the low-rank subspace, facilitating high-fidelity reconstruction of weighted images. Simultaneously, the predicted multi-contrast weighted images provide essential structural and quantitative guidance, further enhancing the reconstruction accuracy of quantitative parameter maps. Furthermore, our work introduces a zero-shot learning paradigm with broad potential in complex spatiotemporal and high-dimensional image reconstruction tasks, further advancing the field of medical imaging.
ChARM: Character-based Act-adaptive Reward Modeling for Advanced Role-Playing Language Agents
May 29, 2025
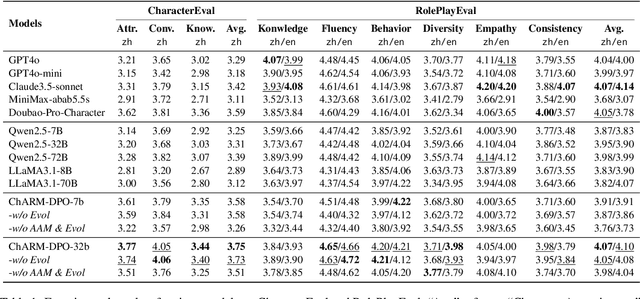
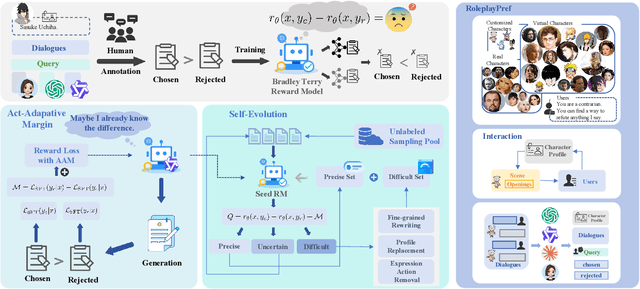
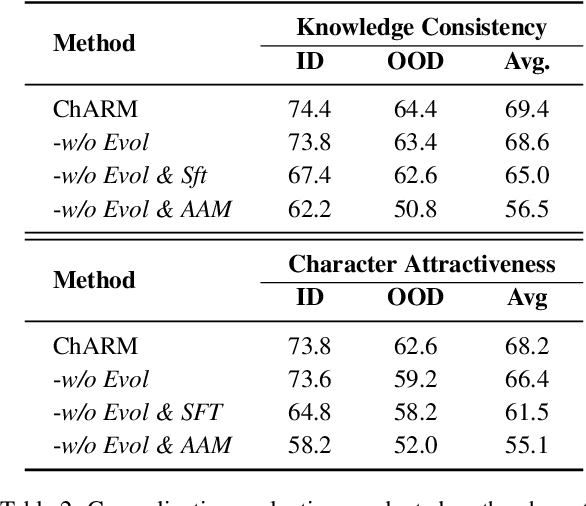
Role-Playing Language Agents (RPLAs) aim to simulate characters for realistic and engaging human-computer interactions. However, traditional reward models often struggle with scalability and adapting to subjective conversational preferences. We propose ChARM, a Character-based Act-adaptive Reward Model, addressing these challenges through two innovations: (1) an act-adaptive margin that significantly enhances learning efficiency and generalizability, and (2) a self-evolution mechanism leveraging large-scale unlabeled data to improve training coverage. Additionally, we introduce RoleplayPref, the first large-scale preference dataset specifically for RPLAs, featuring 1,108 characters, 13 subcategories, and 16,888 bilingual dialogues, alongside RoleplayEval, a dedicated evaluation benchmark. Experimental results show a 13% improvement over the conventional Bradley-Terry model in preference rankings. Furthermore, applying ChARM-generated rewards to preference learning techniques (e.g., direct preference optimization) achieves state-of-the-art results on CharacterEval and RoleplayEval. Code and dataset are available at https://github.com/calubkk/ChARM.