 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding RELIEF: Shaping Reasoning Behavior without Reasoning Supervision via Belief Engineering
Jan 20, 2026Large reasoning models (LRMs) have achieved remarkable success in complex problem-solving, yet they often suffer from computational redundancy or reasoning unfaithfulness. Current methods for shaping LRM behavior typically rely on reinforcement learning or fine-tuning with gold-standard reasoning traces, a paradigm that is both computationally expensive and difficult to scale. In this paper, we reveal that LRMs possess latent \textit{reasoning beliefs} that internally track their own reasoning traits, which can be captured through simple logit probing. Building upon this insight, we propose Reasoning Belief Engineering (RELIEF), a simple yet effective framework that shapes LRM behavior by aligning the model's self-concept with a target belief blueprint. Crucially, RELIEF completely bypasses the need for reasoning-trace supervision. It internalizes desired traits by fine-tuning on synthesized, self-reflective question-answering pairs that affirm the target belief. Extensive experiments on efficiency and faithfulness tasks demonstrate that RELIEF matches or outperforms behavior-supervised and preference-based baselines while requiring lower training costs. Further analysis validates that shifting a model's reasoning belief effectively shapes its actual behavior.
AT$^2$PO: Agentic Turn-based Policy Optimization via Tree Search
Jan 08, 2026LLM agents have emerged as powerful systems for tackling multi-turn tasks by interleaving internal reasoning and external tool interactions. Agentic Reinforcement Learning has recently drawn significant research attention as a critical post-training paradigm to further refine these capabilities. In this paper, we present AT$^2$PO (Agentic Turn-based Policy Optimization via Tree Search), a unified framework for multi-turn agentic RL that addresses three core challenges: limited exploration diversity, sparse credit assignment, and misaligned policy optimization. AT$^2$PO introduces a turn-level tree structure that jointly enables Entropy-Guided Tree Expansion for strategic exploration and Turn-wise Credit Assignment for fine-grained reward propagation from sparse outcomes. Complementing this, we propose Agentic Turn-based Policy Optimization, a turn-level learning objective that aligns policy updates with the natural decision granularity of agentic interactions. ATPO is orthogonal to tree search and can be readily integrated into any multi-turn RL pipeline. Experiments across seven benchmarks demonstrate consistent improvements over the state-of-the-art baseline by up to 1.84 percentage points in average, with ablation studies validating the effectiveness of each component. Our code is available at https://github.com/zzfoutofspace/ATPO.
ChARM: Character-based Act-adaptive Reward Modeling for Advanced Role-Playing Language Agents
May 29, 2025
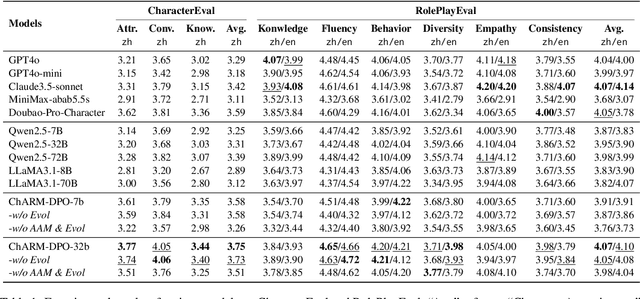
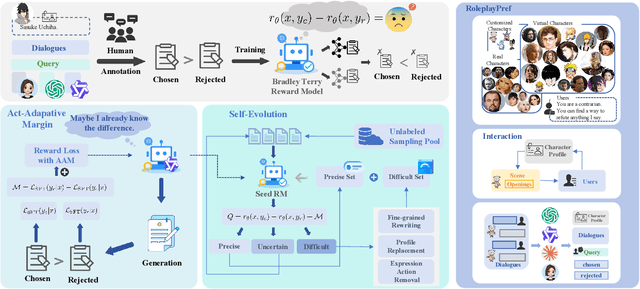
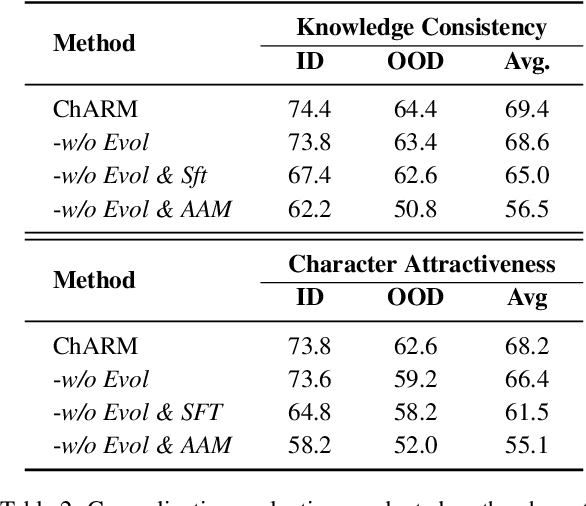
Role-Playing Language Agents (RPLAs) aim to simulate characters for realistic and engaging human-computer interactions. However, traditional reward models often struggle with scalability and adapting to subjective conversational preferences. We propose ChARM, a Character-based Act-adaptive Reward Model, addressing these challenges through two innovations: (1) an act-adaptive margin that significantly enhances learning efficiency and generalizability, and (2) a self-evolution mechanism leveraging large-scale unlabeled data to improve training coverage. Additionally, we introduce RoleplayPref, the first large-scale preference dataset specifically for RPLAs, featuring 1,108 characters, 13 subcategories, and 16,888 bilingual dialogues, alongside RoleplayEval, a dedicated evaluation benchmark. Experimental results show a 13% improvement over the conventional Bradley-Terry model in preference rankings. Furthermore, applying ChARM-generated rewards to preference learning techniques (e.g., direct preference optimization) achieves state-of-the-art results on CharacterEval and RoleplayEval. Code and dataset are available at https://github.com/calubkk/ChARM.
Lower Layer Matters: Alleviating Hallucination via Multi-Layer Fusion Contrastive Decoding with Truthfulness Refocused
Aug 16, 2024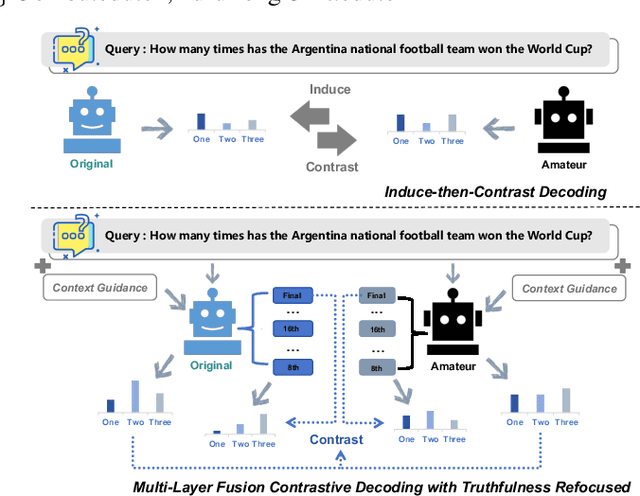

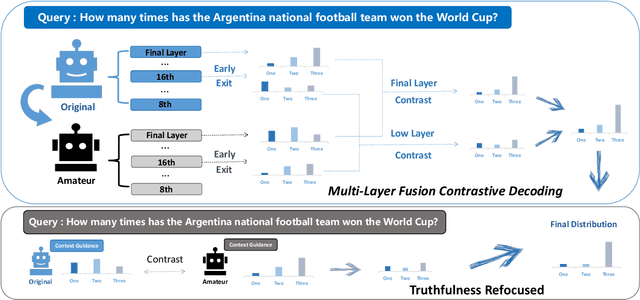
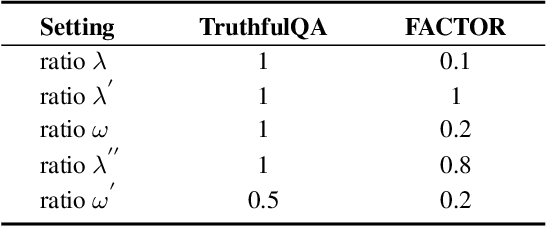
Large Language Models (LLMs) have demonstrated exceptional performance across various natural language processing tasks, yet they occasionally tend to yield content that factually inaccurate or discordant with the expected output, a phenomenon empirically referred to as "hallucination". To tackle this issue, recent works have investigated contrastive decoding between the original model and an amateur model with induced hallucination, which has shown promising results. Nonetheless, this method may undermine the output distribution of the original LLM caused by its coarse contrast and simplistic subtraction operation, potentially leading to errors in certain cases. In this paper, we introduce a novel contrastive decoding framework termed LOL (LOwer Layer Matters). Our approach involves concatenating the contrastive decoding of both the final and lower layers between the original model and the amateur model, thereby achieving multi-layer fusion to aid in the mitigation of hallucination. Additionally, we incorporate a truthfulness refocused module that leverages contextual guidance to enhance factual encoding, further capturing truthfulness during contrastive decoding. Extensive experiments conducted on two publicly available datasets illustrate that our proposed LOL framework can substantially alleviate hallucination while surpassing existing baselines in most cases. Compared with the best baseline, we improve by average 4.5 points on all metrics of TruthfulQA. The source code is coming soon.
Forgetting before Learning: Utilizing Parametric Arithmetic for Knowledge Updating in Large Language Models
Nov 14, 2023Recently Large Language Models (LLMs) have demonstrated their amazing text understanding and generation capabilities. However, even stronger LLMs may still learn incorrect knowledge from the training corpus, as well as some knowledge that is outdated over time. Direct secondary fine-tuning with data containing new knowledge may be ineffective in updating knowledge due to the conflict between old and new knowledge. In this paper, we propose a new paradigm for fine-tuning called F-Learning (Forgetting before Learning), which is based on parametric arithmetic to achieve forgetting of old knowledge and learning of new knowledge. Experimental results on two publicly available datasets demonstrate that our proposed F-Learning can obviously improve the knowledge updating performance of both full fine-tuning and LoRA fine-tuning. Moreover, we have also discovered that forgetting old knowledge by subtracting the parameters of LoRA can achieve a similar effect to subtracting the parameters of full fine-tuning, and sometimes even surpass it significantly.