 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding RELIEF: Shaping Reasoning Behavior without Reasoning Supervision via Belief Engineering
Jan 20, 2026Large reasoning models (LRMs) have achieved remarkable success in complex problem-solving, yet they often suffer from computational redundancy or reasoning unfaithfulness. Current methods for shaping LRM behavior typically rely on reinforcement learning or fine-tuning with gold-standard reasoning traces, a paradigm that is both computationally expensive and difficult to scale. In this paper, we reveal that LRMs possess latent \textit{reasoning beliefs} that internally track their own reasoning traits, which can be captured through simple logit probing. Building upon this insight, we propose Reasoning Belief Engineering (RELIEF), a simple yet effective framework that shapes LRM behavior by aligning the model's self-concept with a target belief blueprint. Crucially, RELIEF completely bypasses the need for reasoning-trace supervision. It internalizes desired traits by fine-tuning on synthesized, self-reflective question-answering pairs that affirm the target belief. Extensive experiments on efficiency and faithfulness tasks demonstrate that RELIEF matches or outperforms behavior-supervised and preference-based baselines while requiring lower training costs. Further analysis validates that shifting a model's reasoning belief effectively shapes its actual behavior.
M-MRE: Extending the Mutual Reinforcement Effect to Multimodal Information Extraction
Apr 24, 2025Mutual Reinforcement Effect (MRE) is an emerging subfield at the intersection of information extraction and model interpretability. MRE aims to leverage the mutual understanding between tasks of different granularities, enhancing the performance of both coarse-grained and fine-grained tasks through joint modeling. While MRE has been explored and validated in the textual domain, its applicability to visual and multimodal domains remains unexplored. In this work, we extend MRE to the multimodal information extraction domain for the first time. Specifically, we introduce a new task: Multimodal Mutual Reinforcement Effect (M-MRE), and construct a corresponding dataset to support this task. To address the challenges posed by M-MRE, we further propose a Prompt Format Adapter (PFA) that is fully compatible with various Large Vision-Language Models (LVLMs). Experimental results demonstrate that MRE can also be observed in the M-MRE task, a multimodal text-image understanding scenario. This provides strong evidence that MRE facilitates mutual gains across three interrelated tasks, confirming its generalizability beyond the textual domain.
Counterfactual experience augmented off-policy reinforcement learning
Mar 18, 2025



Reinforcement learning control algorithms face significant challenges due to out-of-distribution and inefficient exploration problems. While model-based reinforcement learning enhances the agent's reasoning and planning capabilities by constructing virtual environments, training such virtual environments can be very complex. In order to build an efficient inference model and enhance the representativeness of learning data, we propose the Counterfactual Experience Augmentation (CEA) algorithm. CEA leverages variational autoencoders to model the dynamic patterns of state transitions and introduces randomness to model non-stationarity. This approach focuses on expanding the learning data in the experience pool through counterfactual inference and performs exceptionally well in environments that follow the bisimulation assumption. Environments with bisimulation properties are usually represented by discrete observation and action spaces, we propose a sampling method based on maximum kernel density estimation entropy to extend CEA to various environments. By providing reward signals for counterfactual state transitions based on real information, CEA constructs a complete counterfactual experience to alleviate the out-of-distribution problem of the learning data, and outperforms general SOTA algorithms in environments with difference properties. Finally, we discuss the similarities, differences and properties of generated counterfactual experiences and real experiences. The code is available at https://github.com/Aegis1863/CEA.
xJailbreak: Representation Space Guided Reinforcement Learning for Interpretable LLM Jailbreaking
Jan 30, 2025



Safety alignment mechanism are essential for preventing large language models (LLMs) from generating harmful information or unethical content. However, cleverly crafted prompts can bypass these safety measures without accessing the model's internal parameters, a phenomenon known as black-box jailbreak. Existing heuristic black-box attack methods, such as genetic algorithms, suffer from limited effectiveness due to their inherent randomness, while recent reinforcement learning (RL) based methods often lack robust and informative reward signals. To address these challenges, we propose a novel black-box jailbreak method leveraging RL, which optimizes prompt generation by analyzing the embedding proximity between benign and malicious prompts. This approach ensures that the rewritten prompts closely align with the intent of the original prompts while enhancing the attack's effectiveness. Furthermore, we introduce a comprehensive jailbreak evaluation framework incorporating keywords, intent matching, and answer validation to provide a more rigorous and holistic assessment of jailbreak success. Experimental results show the superiority of our approach, achieving state-of-the-art (SOTA) performance on several prominent open and closed-source LLMs, including Qwen2.5-7B-Instruct, Llama3.1-8B-Instruct, and GPT-4o-0806. Our method sets a new benchmark in jailbreak attack effectiveness, highlighting potential vulnerabilities in LLMs. The codebase for this work is available at https://github.com/Aegis1863/xJailbreak.
MacLight: Multi-scene Aggregation Convolutional Learning for Traffic Signal Control
Dec 24, 2024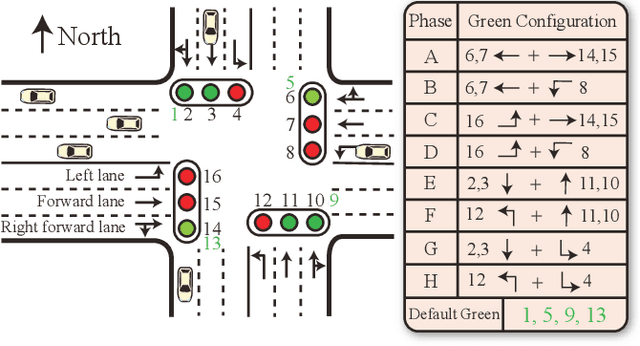
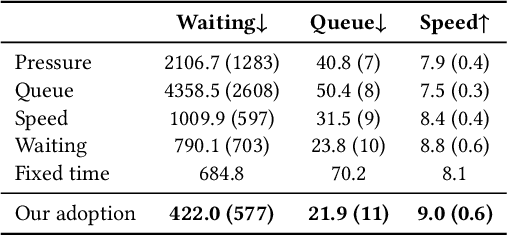
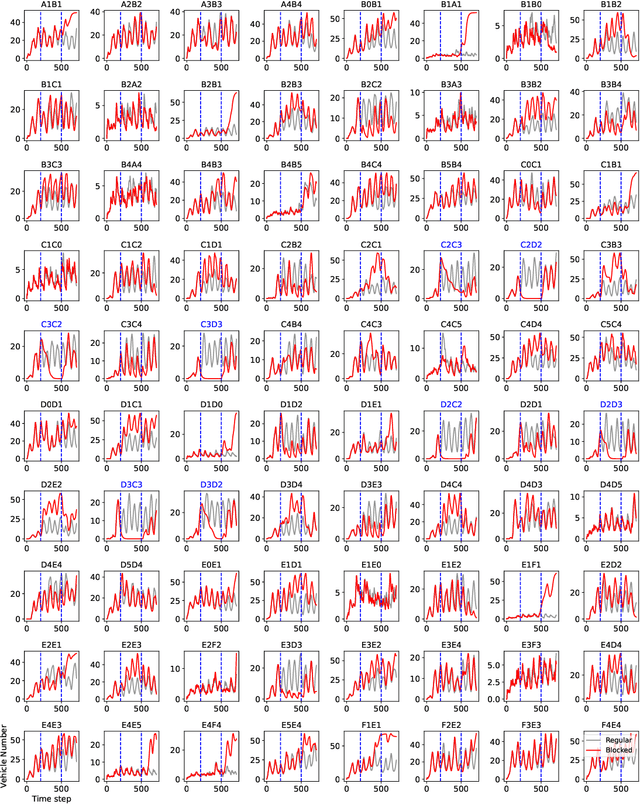
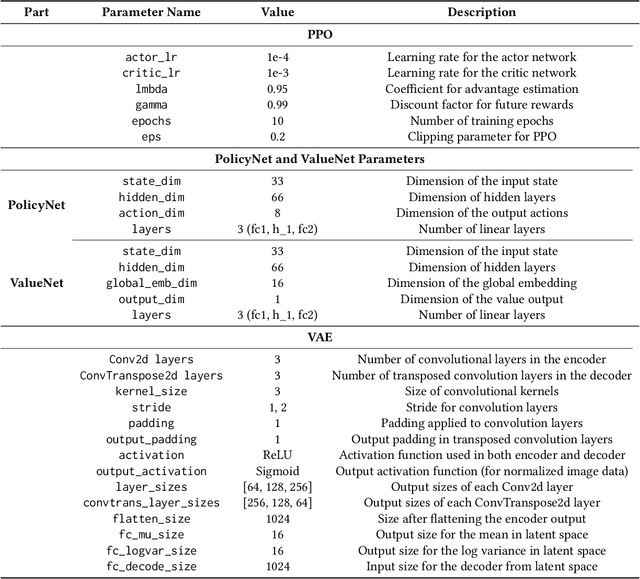
Reinforcement learning methods have proposed promising traffic signal control policy that can be trained on large road networks. Current SOTA methods model road networks as topological graph structures, incorporate graph attention into deep Q-learning, and merge local and global embeddings to improve policy. However, graph-based methods are difficult to parallelize, resulting in huge time overhead. Moreover, none of the current peer studies have deployed dynamic traffic systems for experiments, which is far from the actual situation. In this context, we propose Multi-Scene Aggregation Convolutional Learning for traffic signal control (MacLight), which offers faster training speeds and more stable performance. Our approach consists of two main components. The first is the global representation, where we utilize variational autoencoders to compactly compress and extract the global representation. The second component employs the proximal policy optimization algorithm as the backbone, allowing value evaluation to consider both local features and global embedding representations. This backbone model significantly reduces time overhead and ensures stability in policy updates. We validated our method across multiple traffic scenarios under both static and dynamic traffic systems. Experimental results demonstrate that, compared to general and domian SOTA methods, our approach achieves superior stability, optimized convergence levels and the highest time efficiency. The code is under https://github.com/Aegis1863/MacLight.