 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD-VLA: A High-Concurrency Distributed Asynchronous Reinforcement Learning Framework for Vision-Language-Action Models
May 14, 2026The rapid evolution of Embodied AI has enabled Vision-Language-Action (VLA) models to excel in multimodal perception and task execution. However, applying Reinforcement Learning (RL) to these massive models in large-scale distributed environments faces severe systemic bottlenecks, primarily due to the resource conflict between high-fidelity physical simulation and the intensive VRAM/bandwidth demands of deep learning. This conflict often leaves overall throughput constrained by execution-phase inefficiencies. To address these challenges, we propose D-VLA, a high-concurrency, low-latency distributed RL framework for large-scale embodied foundation models. D-VLA introduces "Plane Decoupling," physically isolating high-frequency training data from low-frequency weight control to eliminate interference between simulation and optimization. We further design a four-thread asynchronous "Swimlane" pipeline, enabling full parallel overlap of sampling, inference, gradient computation, and parameter distribution. Additionally, a dual-pool VRAM management model and topology-aware replication resolve memory fragmentation and optimize communication efficiency. Experiments on benchmarks like LIBERO show that D-VLA significantly outperforms mainstream RL frameworks in throughput and sampling efficiency for billion-parameter VLA models. In trillion-parameter scalability tests, our framework maintains exceptional stability and linear speedup, providing a robust system for high-performance general-purpose embodied agents.
EgoLive: A Large-Scale Egocentric Dataset from Real-World Human Tasks
Apr 26, 2026The advancement of robot learning is currently hindered by the scarcity of large-scale, high-quality datasets. While established data collection methods such as teleoperation and universal manipulation interfaces dominate current datasets, they suffer from inherent limitations in scalability and real-world deployability. Human egocentric video collection, by contrast, has emerged as a promising approach to enable scalable, natural and in-the-wild data collection. As such, we present EgoLive, a large-scale, high-quality egocentric dataset designed explicitly for robot manipulation learning. EgoLive establishes three distinctive technical advantages over existing egocentric datasets: first, it represents the largest open-source annotated egocentric dataset focused on real-world task-oriented human routines to date; second, it delivers leading data quality via a customized head-mounted capture device and comprehensive high-precision multi-modal annotations; third, all data is collected exclusively in unconstrained real-world scenarios and encompasses vertical field human working data, including home service, retail, and other practical work scenarios, providing superior diversity and ecological validity. With the introduction of EgoLive, we aim to provide the research community with a scalable, high-quality dataset that accelerates breakthroughs in generalizable robotic models and facilitates the real-world deployment of robot systems.
JoyAI-RA 0.1: A Foundation Model for Robotic Autonomy
Apr 22, 2026Robotic autonomy in open-world environments is fundamentally limited by insufficient data diversity and poor cross-embodiment generalization. Existing robotic datasets are often limited in scale and task coverage, while relatively large differences across robot embodiments impede effective behavior knowledge transfer. To address these challenges, we propose JoyAI-RA, a vision-language-action (VLA) embodied foundation model tailored for generalizable robotic manipulation. JoyAI-RA presents a multi-source multi-level pretraining framework that integrates web data, large-scale egocentric human manipulation videos, simulation-generated trajectories, and real-robot data. Through training on heterogeneous multi-source data with explicit action-space unification, JoyAI-RA effectively bridges embodiment gaps, particularly between human manipulation and robotic control, thereby enhancing cross-embodiment behavior learning. JoyAI-RA outperforms state-of-the-art methods in both simulation and real-world benchmarks, especially on diverse tasks with generalization demands.
Giving Faces Their Feelings Back: Explicit Emotion Control for Feedforward Single-Image 3D Head Avatars
Apr 16, 2026We present a framework for explicit emotion control in feed-forward, single-image 3D head avatar reconstruction. Unlike existing pipelines where emotion is implicitly entangled with geometry or appearance, we treat emotion as a first-class control signal that can be manipulated independently and consistently across identities. Our method injects emotion into existing feed-forward architectures via a dual-path modulation mechanism without modifying their core design. Geometry modulation performs emotion-conditioned normalization in the original parametric space, disentangling emotional state from speech-driven articulation, while appearance modulation captures identity-aware, emotion-dependent visual cues beyond geometry. To enable learning under this setting, we construct a time-synchronized, emotion-consistent multi-identity dataset by transferring aligned emotional dynamics across identities. Integrated into multiple state-of-the-art backbones, our framework preserves reconstruction and reenactment fidelity while enabling controllable emotion transfer, disentangled manipulation, and smooth emotion interpolation, advancing expressive and scalable 3D head avatars.
JoyAI-LLM Flash: Advancing Mid-Scale LLMs with Token Efficiency
Apr 03, 2026We introduce JoyAI-LLM Flash, an efficient Mixture-of-Experts (MoE) language model designed to redefine the trade-off between strong performance and token efficiency in the sub-50B parameter regime. JoyAI-LLM Flash is pretrained on a massive corpus of 20 trillion tokens and further optimized through a rigorous post-training pipeline, including supervised fine-tuning (SFT), Direct Preference Optimization (DPO), and large-scale reinforcement learning (RL) across diverse environments. To improve token efficiency, JoyAI-LLM Flash strategically balances \emph{thinking} and \emph{non-thinking} cognitive modes and introduces FiberPO, a novel RL algorithm inspired by fibration theory that decomposes trust-region maintenance into global and local components, providing unified multi-scale stability control for LLM policy optimization. To enhance architectural sparsity, the model comprises 48B total parameters while activating only 2.7B parameters per forward pass, achieving a substantially higher sparsity ratio than contemporary industry leading models of comparable scale. To further improve inference throughput, we adopt a joint training-inference co-design that incorporates dense Multi-Token Prediction (MTP) and Quantization-Aware Training (QAT). We release the checkpoints for both JoyAI-LLM-48B-A3B Base and its post-trained variants on Hugging Face to support the open-source community.
Thousand-GPU Large-Scale Training and Optimization Recipe for AI-Native Cloud Embodied Intelligence Infrastructure
Mar 11, 2026Embodied intelligence is a key step towards Artificial General Intelligence (AGI), yet its development faces multiple challenges including data, frameworks, infrastructure, and evaluation systems. To address these issues, we have, for the first time in the industry, launched a cloud-based, thousand-GPU distributed training platform for embodied intelligence, built upon the widely adopted LeRobot framework, and have systematically overcome bottlenecks across the entire pipeline. At the data layer, we have restructured the data pipeline to optimize the flow of embodied training data. In terms of training, for the GR00T-N1.5 model, utilizing thousand-GPU clusters and data at the scale of hundreds of millions, the single-round training time has been reduced from 15 hours to just 22 minutes, achieving a 40-fold speedup. At the model layer, by combining variable-length FlashAttention and Data Packing, we have moved from sample redundancy to sequence integration, resulting in a 188% speed increase; π-0.5 attention optimization has accelerated training by 165%; and FP8 quantization has delivered a 140% speedup. On the infrastructure side, relying on high-performance storage, a 3.2T RDMA network, and a Ray-driven elastic AI data lake, we have achieved deep synergy among data, storage, communication, and computation. We have also built an end-to-end evaluation system, creating a closed loop from training to simulation to assessment. This framework has already been fully validated on thousand-GPU clusters, laying a crucial technical foundation for the development and application of next-generation autonomous intelligent robots, and is expected to accelerate the arrival of the era of human-machine integration.
RL-VLA$^3$: Reinforcement Learning VLA Accelerating via Full Asynchronism
Feb 05, 2026In recent years, Vision-Language-Action (VLA) models have emerged as a crucial pathway towards general embodied intelligence, yet their training efficiency has become a key bottleneck. Although existing reinforcement learning (RL)-based training frameworks like RLinf can enhance model generalization, they still rely on synchronous execution, leading to severe resource underutilization and throughput limitations during environment interaction, policy generation (rollout), and model update phases (actor). To overcome this challenge, this paper, for the first time, proposes and implements a fully-asynchronous policy training framework encompassing the entire pipeline from environment interaction, rollout generation, to actor policy updates. Systematically drawing inspiration from asynchronous optimization ideas in large model RL, our framework designs a multi-level decoupled architecture. This includes asynchronous parallelization of environment interaction and trajectory collection, streaming execution for policy generation, and decoupled scheduling for training updates. We validated the effectiveness of our method across diverse VLA models and environments. On the LIBERO benchmark, the framework achieves throughput improvements of up to 59.25\% compared to existing synchronous strategies. When deeply optimizing separation strategies, throughput can be increased by as much as 126.67\%. We verified the effectiveness of each asynchronous component via ablation studies. Scaling law validation across 8 to 256 GPUs demonstrates our method's excellent scalability under most conditions.
Counterfactual experience augmented off-policy reinforcement learning
Mar 18, 2025



Reinforcement learning control algorithms face significant challenges due to out-of-distribution and inefficient exploration problems. While model-based reinforcement learning enhances the agent's reasoning and planning capabilities by constructing virtual environments, training such virtual environments can be very complex. In order to build an efficient inference model and enhance the representativeness of learning data, we propose the Counterfactual Experience Augmentation (CEA) algorithm. CEA leverages variational autoencoders to model the dynamic patterns of state transitions and introduces randomness to model non-stationarity. This approach focuses on expanding the learning data in the experience pool through counterfactual inference and performs exceptionally well in environments that follow the bisimulation assumption. Environments with bisimulation properties are usually represented by discrete observation and action spaces, we propose a sampling method based on maximum kernel density estimation entropy to extend CEA to various environments. By providing reward signals for counterfactual state transitions based on real information, CEA constructs a complete counterfactual experience to alleviate the out-of-distribution problem of the learning data, and outperforms general SOTA algorithms in environments with difference properties. Finally, we discuss the similarities, differences and properties of generated counterfactual experiences and real experiences. The code is available at https://github.com/Aegis1863/CEA.
xJailbreak: Representation Space Guided Reinforcement Learning for Interpretable LLM Jailbreaking
Jan 30, 2025



Safety alignment mechanism are essential for preventing large language models (LLMs) from generating harmful information or unethical content. However, cleverly crafted prompts can bypass these safety measures without accessing the model's internal parameters, a phenomenon known as black-box jailbreak. Existing heuristic black-box attack methods, such as genetic algorithms, suffer from limited effectiveness due to their inherent randomness, while recent reinforcement learning (RL) based methods often lack robust and informative reward signals. To address these challenges, we propose a novel black-box jailbreak method leveraging RL, which optimizes prompt generation by analyzing the embedding proximity between benign and malicious prompts. This approach ensures that the rewritten prompts closely align with the intent of the original prompts while enhancing the attack's effectiveness. Furthermore, we introduce a comprehensive jailbreak evaluation framework incorporating keywords, intent matching, and answer validation to provide a more rigorous and holistic assessment of jailbreak success. Experimental results show the superiority of our approach, achieving state-of-the-art (SOTA) performance on several prominent open and closed-source LLMs, including Qwen2.5-7B-Instruct, Llama3.1-8B-Instruct, and GPT-4o-0806. Our method sets a new benchmark in jailbreak attack effectiveness, highlighting potential vulnerabilities in LLMs. The codebase for this work is available at https://github.com/Aegis1863/xJailbreak.
MacLight: Multi-scene Aggregation Convolutional Learning for Traffic Signal Control
Dec 24, 2024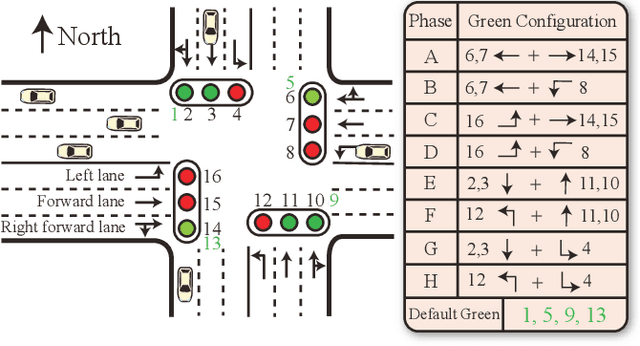
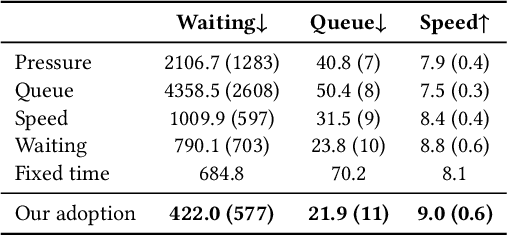
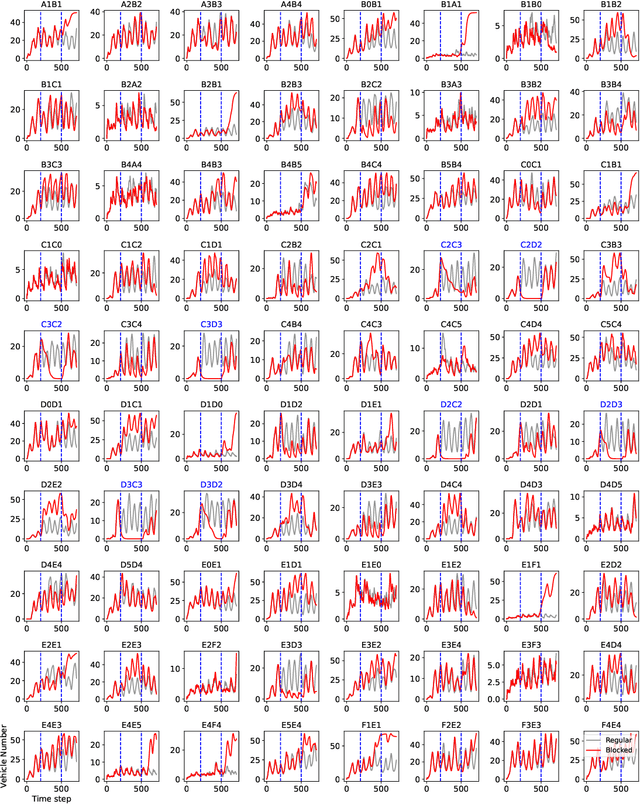
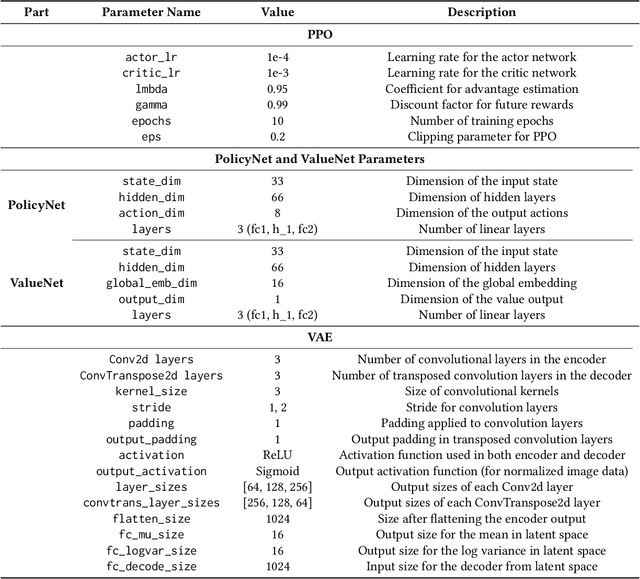
Reinforcement learning methods have proposed promising traffic signal control policy that can be trained on large road networks. Current SOTA methods model road networks as topological graph structures, incorporate graph attention into deep Q-learning, and merge local and global embeddings to improve policy. However, graph-based methods are difficult to parallelize, resulting in huge time overhead. Moreover, none of the current peer studies have deployed dynamic traffic systems for experiments, which is far from the actual situation. In this context, we propose Multi-Scene Aggregation Convolutional Learning for traffic signal control (MacLight), which offers faster training speeds and more stable performance. Our approach consists of two main components. The first is the global representation, where we utilize variational autoencoders to compactly compress and extract the global representation. The second component employs the proximal policy optimization algorithm as the backbone, allowing value evaluation to consider both local features and global embedding representations. This backbone model significantly reduces time overhead and ensures stability in policy updates. We validated our method across multiple traffic scenarios under both static and dynamic traffic systems. Experimental results demonstrate that, compared to general and domian SOTA methods, our approach achieves superior stability, optimized convergence levels and the highest time efficiency. The code is under https://github.com/Aegis1863/MacLight.