 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAT$^2$PO: Agentic Turn-based Policy Optimization via Tree Search
Jan 08, 2026LLM agents have emerged as powerful systems for tackling multi-turn tasks by interleaving internal reasoning and external tool interactions. Agentic Reinforcement Learning has recently drawn significant research attention as a critical post-training paradigm to further refine these capabilities. In this paper, we present AT$^2$PO (Agentic Turn-based Policy Optimization via Tree Search), a unified framework for multi-turn agentic RL that addresses three core challenges: limited exploration diversity, sparse credit assignment, and misaligned policy optimization. AT$^2$PO introduces a turn-level tree structure that jointly enables Entropy-Guided Tree Expansion for strategic exploration and Turn-wise Credit Assignment for fine-grained reward propagation from sparse outcomes. Complementing this, we propose Agentic Turn-based Policy Optimization, a turn-level learning objective that aligns policy updates with the natural decision granularity of agentic interactions. ATPO is orthogonal to tree search and can be readily integrated into any multi-turn RL pipeline. Experiments across seven benchmarks demonstrate consistent improvements over the state-of-the-art baseline by up to 1.84 percentage points in average, with ablation studies validating the effectiveness of each component. Our code is available at https://github.com/zzfoutofspace/ATPO.
UniCO: Towards a Unified Model for Combinatorial Optimization Problems
May 07, 2025Combinatorial Optimization (CO) encompasses a wide range of problems that arise in many real-world scenarios. While significant progress has been made in developing learning-based methods for specialized CO problems, a unified model with a single architecture and parameter set for diverse CO problems remains elusive. Such a model would offer substantial advantages in terms of efficiency and convenience. In this paper, we introduce UniCO, a unified model for solving various CO problems. Inspired by the success of next-token prediction, we frame each problem-solving process as a Markov Decision Process (MDP), tokenize the corresponding sequential trajectory data, and train the model using a transformer backbone. To reduce token length in the trajectory data, we propose a CO-prefix design that aggregates static problem features. To address the heterogeneity of state and action tokens within the MDP, we employ a two-stage self-supervised learning approach. In this approach, a dynamic prediction model is first trained and then serves as a pre-trained model for subsequent policy generation. Experiments across 10 CO problems showcase the versatility of UniCO, emphasizing its ability to generalize to new, unseen problems with minimal fine-tuning, achieving even few-shot or zero-shot performance. Our framework offers a valuable complement to existing neural CO methods that focus on optimizing performance for individual problems.
Towards Large Reasoning Models: A Survey on Scaling LLM Reasoning Capabilities
Jan 17, 2025



Language has long been conceived as an essential tool for human reasoning. The breakthrough of Large Language Models (LLMs) has sparked significant research interest in leveraging these models to tackle complex reasoning tasks. Researchers have moved beyond simple autoregressive token generation by introducing the concept of "thought" -- a sequence of tokens representing intermediate steps in the reasoning process. This innovative paradigm enables LLMs' to mimic complex human reasoning processes, such as tree search and reflective thinking. Recently, an emerging trend of learning to reason has applied reinforcement learning (RL) to train LLMs to master reasoning processes. This approach enables the automatic generation of high-quality reasoning trajectories through trial-and-error search algorithms, significantly expanding LLMs' reasoning capacity by providing substantially more training data. Furthermore, recent studies demonstrate that encouraging LLMs to "think" with more tokens during test-time inference can further significantly boost reasoning accuracy. Therefore, the train-time and test-time scaling combined to show a new research frontier -- a path toward Large Reasoning Model. The introduction of OpenAI's o1 series marks a significant milestone in this research direction. In this survey, we present a comprehensive review of recent progress in LLM reasoning. We begin by introducing the foundational background of LLMs and then explore the key technical components driving the development of large reasoning models, with a focus on automated data construction, learning-to-reason techniques, and test-time scaling. We also analyze popular open-source projects at building large reasoning models, and conclude with open challenges and future research directions.
Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models
Jan 16, 2025Language has long been conceived as an essential tool for human reasoning. The breakthrough of Large Language Models (LLMs) has sparked significant research interest in leveraging these models to tackle complex reasoning tasks. Researchers have moved beyond simple autoregressive token generation by introducing the concept of "thought" -- a sequence of tokens representing intermediate steps in the reasoning process. This innovative paradigm enables LLMs' to mimic complex human reasoning processes, such as tree search and reflective thinking. Recently, an emerging trend of learning to reason has applied reinforcement learning (RL) to train LLMs to master reasoning processes. This approach enables the automatic generation of high-quality reasoning trajectories through trial-and-error search algorithms, significantly expanding LLMs' reasoning capacity by providing substantially more training data. Furthermore, recent studies demonstrate that encouraging LLMs to "think" with more tokens during test-time inference can further significantly boost reasoning accuracy. Therefore, the train-time and test-time scaling combined to show a new research frontier -- a path toward Large Reasoning Model. The introduction of OpenAI's o1 series marks a significant milestone in this research direction. In this survey, we present a comprehensive review of recent progress in LLM reasoning. We begin by introducing the foundational background of LLMs and then explore the key technical components driving the development of large reasoning models, with a focus on automated data construction, learning-to-reason techniques, and test-time scaling. We also analyze popular open-source projects at building large reasoning models, and conclude with open challenges and future research directions.
Understanding World or Predicting Future? A Comprehensive Survey of World Models
Nov 21, 2024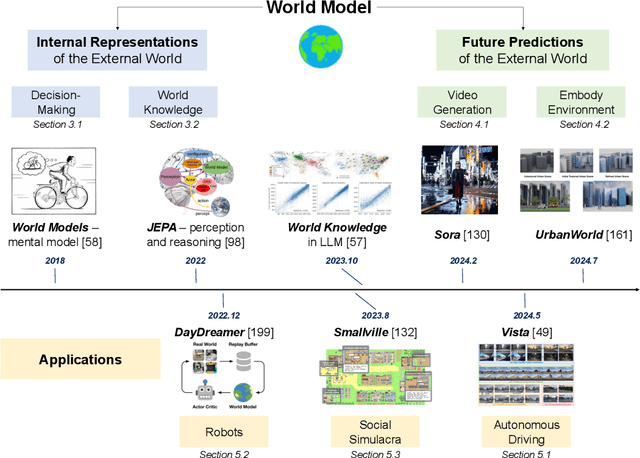

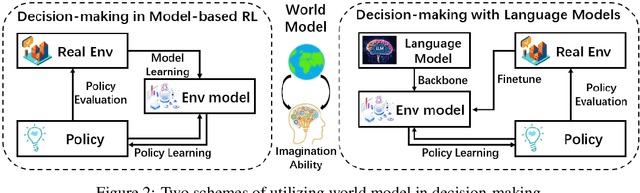
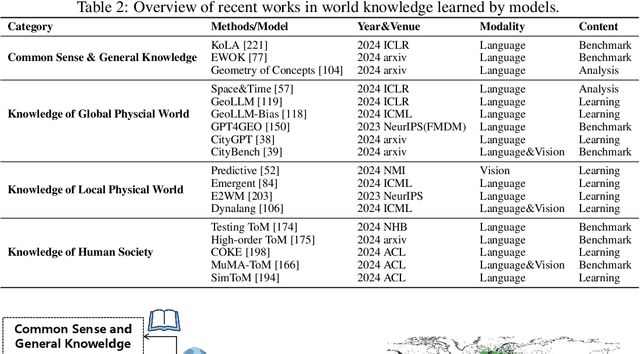
The concept of world models has garnered significant attention due to advancements in multimodal large language models such as GPT-4 and video generation models such as Sora, which are central to the pursuit of artificial general intelligence. This survey offers a comprehensive review of the literature on world models. Generally, world models are regarded as tools for either understanding the present state of the world or predicting its future dynamics. This review presents a systematic categorization of world models, emphasizing two primary functions: (1) constructing internal representations to understand the mechanisms of the world, and (2) predicting future states to simulate and guide decision-making. Initially, we examine the current progress in these two categories. We then explore the application of world models in key domains, including autonomous driving, robotics, and social simulacra, with a focus on how each domain utilizes these aspects. Finally, we outline key challenges and provide insights into potential future research directions.
Deep Reinforcement Learning for Demand Driven Services in Logistics and Transportation Systems: A Survey
Aug 10, 2021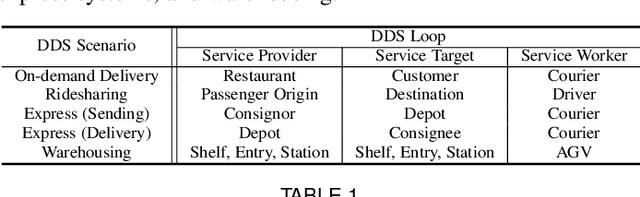


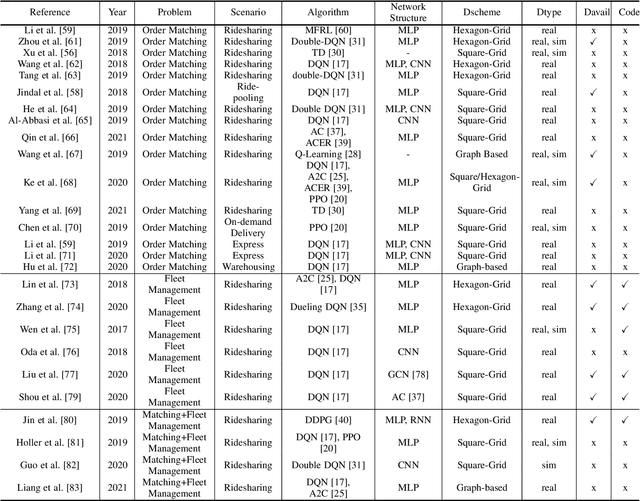
Recent technology development brings the booming of numerous new Demand-Driven Services (DDS) into urban lives, including ridesharing, on-demand delivery, express systems and warehousing. In DDS, a service loop is an elemental structure, including its service worker, the service providers and corresponding service targets. The service workers should transport either humans or parcels from the providers to the target locations. Various planning tasks within DDS can thus be classified into two individual stages: 1) Dispatching, which is to form service loops from demand/supply distributions, and 2)Routing, which is to decide specific serving orders within the constructed loops. Generating high-quality strategies in both stages is important to develop DDS but faces several challenging. Meanwhile, deep reinforcement learning (DRL) has been developed rapidly in recent years. It is a powerful tool to solve these problems since DRL can learn a parametric model without relying on too many problem-based assumptions and optimize long-term effect by learning sequential decisions. In this survey, we first define DDS, then highlight common applications and important decision/control problems within. For each problem, we comprehensively introduce the existing DRL solutions, and further summarize them in \textit{https://github.com/tsinghua-fib-lab/DDS\_Survey}. We also introduce open simulation environments for development and evaluation of DDS applications. Finally, we analyze remaining challenges and discuss further research opportunities in DRL solutions for DDS.
Reinforced Epidemic Control: Saving Both Lives and Economy
Aug 04, 2020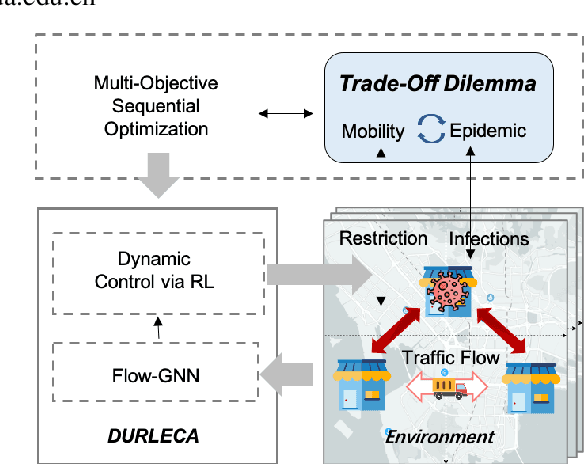
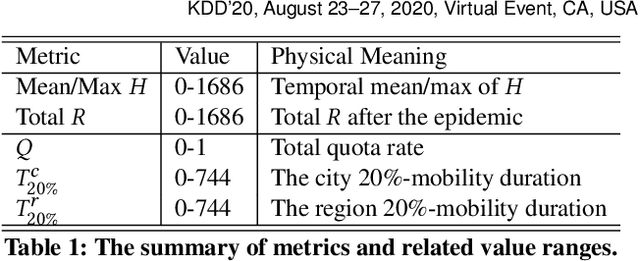
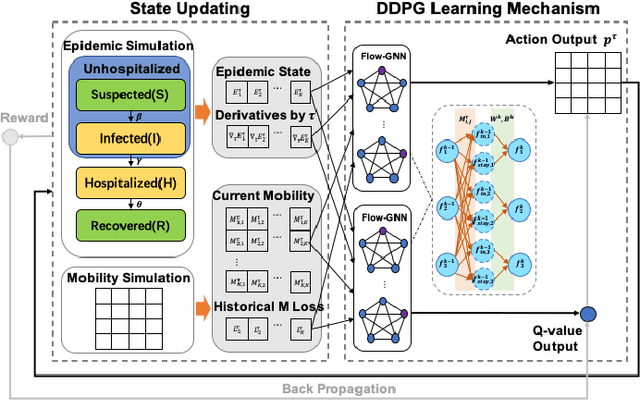
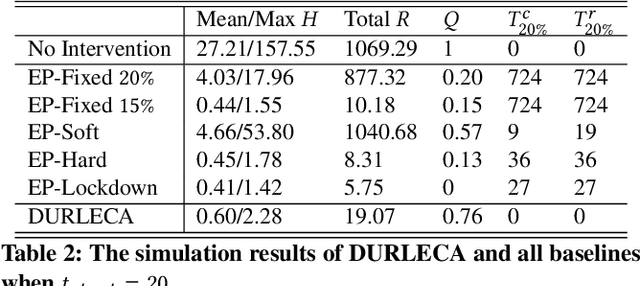
Saving lives or economy is a dilemma for epidemic control in most cities while smart-tracing technology raises people's privacy concerns. In this paper, we propose a solution for the life-or-economy dilemma that does not require private data. We bypass the private-data requirement by suppressing epidemic transmission through a dynamic control on inter-regional mobility that only relies on Origin-Designation (OD) data. We develop DUal-objective Reinforcement-Learning Epidemic Control Agent (DURLECA) to search mobility-control policies that can simultaneously minimize infection spread and maximally retain mobility. DURLECA hires a novel graph neural network, namely Flow-GNN, to estimate the virus-transmission risk induced by urban mobility. The estimated risk is used to support a reinforcement learning agent to generate mobility-control actions. The training of DURLECA is guided with a well-constructed reward function, which captures the natural trade-off relation between epidemic control and mobility retaining. Besides, we design two exploration strategies to improve the agent's searching efficiency and help it get rid of local optimums. Extensive experimental results on a real-world OD dataset show that DURLECA is able to suppress infections at an extremely low level while retaining 76\% of the mobility in the city. Our implementation is available at https://github.com/anyleopeace/DURLECA/.