 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoQual: An LLM Agent for Automated Discovery of Interpretable Features for Review Quality Assessment
Oct 09, 2025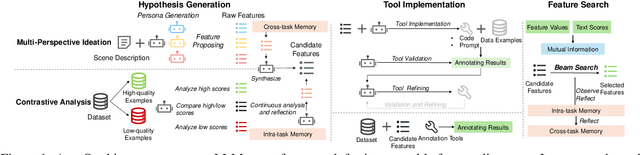
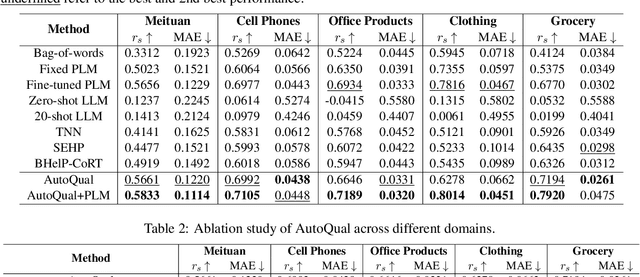
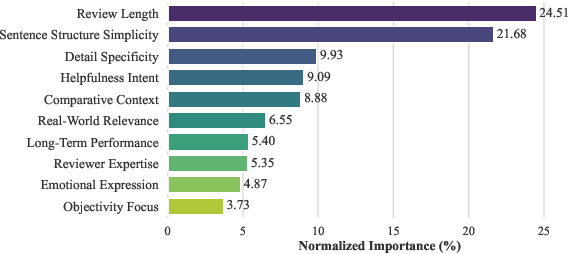
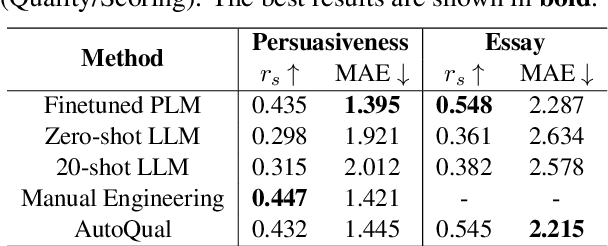
Ranking online reviews by their intrinsic quality is a critical task for e-commerce platforms and information services, impacting user experience and business outcomes. However, quality is a domain-dependent and dynamic concept, making its assessment a formidable challenge. Traditional methods relying on hand-crafted features are unscalable across domains and fail to adapt to evolving content patterns, while modern deep learning approaches often produce black-box models that lack interpretability and may prioritize semantics over quality. To address these challenges, we propose AutoQual, an LLM-based agent framework that automates the discovery of interpretable features. While demonstrated on review quality assessment, AutoQual is designed as a general framework for transforming tacit knowledge embedded in data into explicit, computable features. It mimics a human research process, iteratively generating feature hypotheses through reflection, operationalizing them via autonomous tool implementation, and accumulating experience in a persistent memory. We deploy our method on a large-scale online platform with a billion-level user base. Large-scale A/B testing confirms its effectiveness, increasing average reviews viewed per user by 0.79% and the conversion rate of review readers by 0.27%.
The Thinking Spectrum: An Emperical Study of Tunable Reasoning in LLMs through Model Merging
Sep 26, 2025The growing demand for large language models (LLMs) with tunable reasoning capabilities in many real-world applications highlights a critical need for methods that can efficiently produce a spectrum of models balancing reasoning depth and computational cost. Model merging has emerged as a promising, training-free technique to address this challenge by arithmetically combining the weights of a general-purpose model with a specialized reasoning model. While various merging techniques exist, their potential to create a spectrum of models with fine-grained control over reasoning abilities remains largely unexplored. This work presents a large-scale empirical study evaluating a range of model merging techniques across multiple reasoning benchmarks. We systematically vary merging strengths to construct accuracy-efficiency curves, providing the first comprehensive view of the tunable performance landscape. Our findings reveal that model merging offers an effective and controllable method for calibrating the trade-off between reasoning accuracy and token efficiency, even when parent models have highly divergent weight spaces. Crucially, we identify instances of Pareto Improvement, where a merged model achieves both higher accuracy and lower token consumption than one of its parents. Our study provides the first comprehensive analysis of this tunable space, offering practical guidelines for creating LLMs with specific reasoning profiles to meet diverse application demands.
Simulating Generative Social Agents via Theory-Informed Workflow Design
Aug 12, 2025Recent advances in large language models have demonstrated strong reasoning and role-playing capabilities, opening new opportunities for agent-based social simulations. However, most existing agents' implementations are scenario-tailored, without a unified framework to guide the design. This lack of a general social agent limits their ability to generalize across different social contexts and to produce consistent, realistic behaviors. To address this challenge, we propose a theory-informed framework that provides a systematic design process for LLM-based social agents. Our framework is grounded in principles from Social Cognition Theory and introduces three key modules: motivation, action planning, and learning. These modules jointly enable agents to reason about their goals, plan coherent actions, and adapt their behavior over time, leading to more flexible and contextually appropriate responses. Comprehensive experiments demonstrate that our theory-driven agents reproduce realistic human behavior patterns under complex conditions, achieving up to 75% lower deviation from real-world behavioral data across multiple fidelity metrics compared to classical generative baselines. Ablation studies further show that removing motivation, planning, or learning modules increases errors by 1.5 to 3.2 times, confirming their distinct and essential contributions to generating realistic and coherent social behaviors.
AgentSociety: Large-Scale Simulation of LLM-Driven Generative Agents Advances Understanding of Human Behaviors and Society
Feb 12, 2025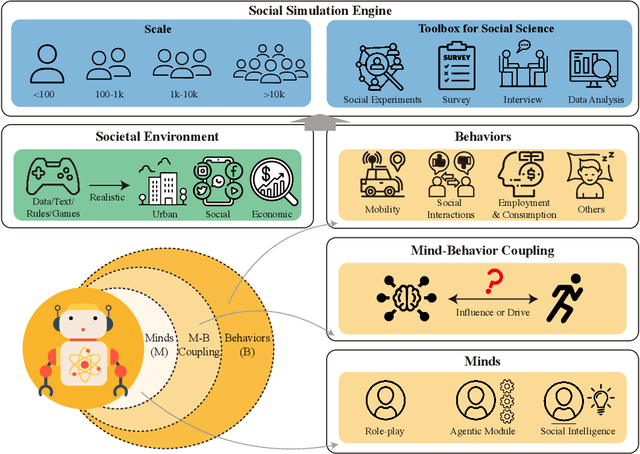
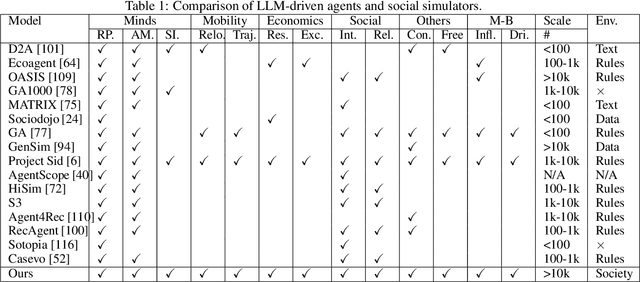
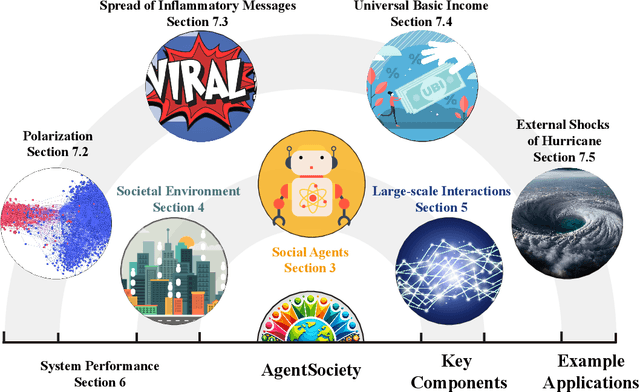

Understanding human behavior and society is a central focus in social sciences, with the rise of generative social science marking a significant paradigmatic shift. By leveraging bottom-up simulations, it replaces costly and logistically challenging traditional experiments with scalable, replicable, and systematic computational approaches for studying complex social dynamics. Recent advances in large language models (LLMs) have further transformed this research paradigm, enabling the creation of human-like generative social agents and realistic simulacra of society. In this paper, we propose AgentSociety, a large-scale social simulator that integrates LLM-driven agents, a realistic societal environment, and a powerful large-scale simulation engine. Based on the proposed simulator, we generate social lives for over 10k agents, simulating their 5 million interactions both among agents and between agents and their environment. Furthermore, we explore the potential of AgentSociety as a testbed for computational social experiments, focusing on four key social issues: polarization, the spread of inflammatory messages, the effects of universal basic income policies, and the impact of external shocks such as hurricanes. These four issues serve as valuable cases for assessing AgentSociety's support for typical research methods -- such as surveys, interviews, and interventions -- as well as for investigating the patterns, causes, and underlying mechanisms of social issues. The alignment between AgentSociety's outcomes and real-world experimental results not only demonstrates its ability to capture human behaviors and their underlying mechanisms, but also underscores its potential as an important platform for social scientists and policymakers.
Towards Large Reasoning Models: A Survey on Scaling LLM Reasoning Capabilities
Jan 17, 2025



Language has long been conceived as an essential tool for human reasoning. The breakthrough of Large Language Models (LLMs) has sparked significant research interest in leveraging these models to tackle complex reasoning tasks. Researchers have moved beyond simple autoregressive token generation by introducing the concept of "thought" -- a sequence of tokens representing intermediate steps in the reasoning process. This innovative paradigm enables LLMs' to mimic complex human reasoning processes, such as tree search and reflective thinking. Recently, an emerging trend of learning to reason has applied reinforcement learning (RL) to train LLMs to master reasoning processes. This approach enables the automatic generation of high-quality reasoning trajectories through trial-and-error search algorithms, significantly expanding LLMs' reasoning capacity by providing substantially more training data. Furthermore, recent studies demonstrate that encouraging LLMs to "think" with more tokens during test-time inference can further significantly boost reasoning accuracy. Therefore, the train-time and test-time scaling combined to show a new research frontier -- a path toward Large Reasoning Model. The introduction of OpenAI's o1 series marks a significant milestone in this research direction. In this survey, we present a comprehensive review of recent progress in LLM reasoning. We begin by introducing the foundational background of LLMs and then explore the key technical components driving the development of large reasoning models, with a focus on automated data construction, learning-to-reason techniques, and test-time scaling. We also analyze popular open-source projects at building large reasoning models, and conclude with open challenges and future research directions.
Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models
Jan 16, 2025Language has long been conceived as an essential tool for human reasoning. The breakthrough of Large Language Models (LLMs) has sparked significant research interest in leveraging these models to tackle complex reasoning tasks. Researchers have moved beyond simple autoregressive token generation by introducing the concept of "thought" -- a sequence of tokens representing intermediate steps in the reasoning process. This innovative paradigm enables LLMs' to mimic complex human reasoning processes, such as tree search and reflective thinking. Recently, an emerging trend of learning to reason has applied reinforcement learning (RL) to train LLMs to master reasoning processes. This approach enables the automatic generation of high-quality reasoning trajectories through trial-and-error search algorithms, significantly expanding LLMs' reasoning capacity by providing substantially more training data. Furthermore, recent studies demonstrate that encouraging LLMs to "think" with more tokens during test-time inference can further significantly boost reasoning accuracy. Therefore, the train-time and test-time scaling combined to show a new research frontier -- a path toward Large Reasoning Model. The introduction of OpenAI's o1 series marks a significant milestone in this research direction. In this survey, we present a comprehensive review of recent progress in LLM reasoning. We begin by introducing the foundational background of LLMs and then explore the key technical components driving the development of large reasoning models, with a focus on automated data construction, learning-to-reason techniques, and test-time scaling. We also analyze popular open-source projects at building large reasoning models, and conclude with open challenges and future research directions.
Depression Detection on Social Media with Large Language Models
Mar 16, 2024



Depression harms. However, due to a lack of mental health awareness and fear of stigma, many patients do not actively seek diagnosis and treatment, leading to detrimental outcomes. Depression detection aims to determine whether an individual suffers from depression by analyzing their history of posts on social media, which can significantly aid in early detection and intervention. It mainly faces two key challenges: 1) it requires professional medical knowledge, and 2) it necessitates both high accuracy and explainability. To address it, we propose a novel depression detection system called DORIS, combining medical knowledge and the recent advances in large language models (LLMs). Specifically, to tackle the first challenge, we proposed an LLM-based solution to first annotate whether high-risk texts meet medical diagnostic criteria. Further, we retrieve texts with high emotional intensity and summarize critical information from the historical mood records of users, so-called mood courses. To tackle the second challenge, we combine LLM and traditional classifiers to integrate medical knowledge-guided features, for which the model can also explain its prediction results, achieving both high accuracy and explainability. Extensive experimental results on benchmarking datasets show that, compared to the current best baseline, our approach improves by 0.036 in AUPRC, which can be considered significant, demonstrating the effectiveness of our approach and its high value as an NLP application.
Large Language Models Empowered Agent-based Modeling and Simulation: A Survey and Perspectives
Dec 19, 2023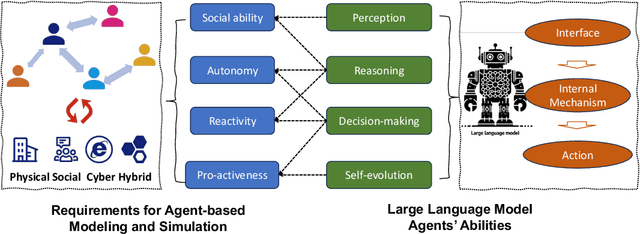
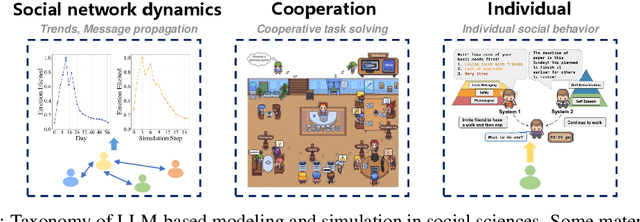
Agent-based modeling and simulation has evolved as a powerful tool for modeling complex systems, offering insights into emergent behaviors and interactions among diverse agents. Integrating large language models into agent-based modeling and simulation presents a promising avenue for enhancing simulation capabilities. This paper surveys the landscape of utilizing large language models in agent-based modeling and simulation, examining their challenges and promising future directions. In this survey, since this is an interdisciplinary field, we first introduce the background of agent-based modeling and simulation and large language model-empowered agents. We then discuss the motivation for applying large language models to agent-based simulation and systematically analyze the challenges in environment perception, human alignment, action generation, and evaluation. Most importantly, we provide a comprehensive overview of the recent works of large language model-empowered agent-based modeling and simulation in multiple scenarios, which can be divided into four domains: cyber, physical, social, and hybrid, covering simulation of both real-world and virtual environments. Finally, since this area is new and quickly evolving, we discuss the open problems and promising future directions.
Stance Detection with Collaborative Role-Infused LLM-Based Agents
Oct 16, 2023
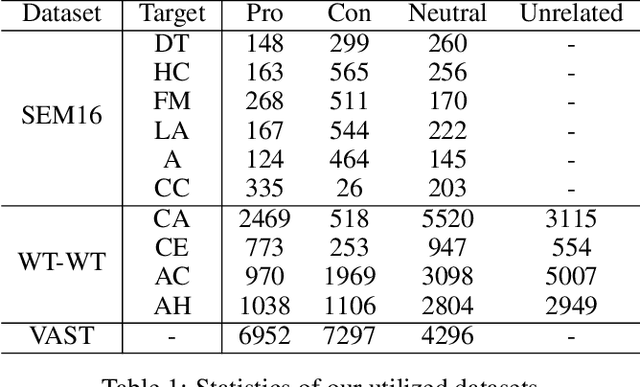
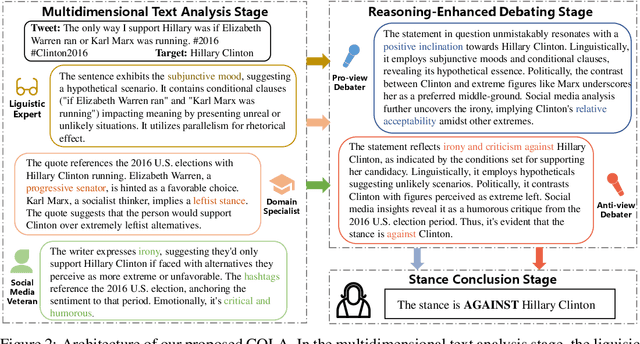

Stance detection automatically detects the stance in a text towards a target, vital for content analysis in web and social media research. Despite their promising capabilities, LLMs encounter challenges when directly applied to stance detection. First, stance detection demands multi-aspect knowledge, from deciphering event-related terminologies to understanding the expression styles in social media platforms. Second, stance detection requires advanced reasoning to infer authors' implicit viewpoints, as stance are often subtly embedded rather than overtly stated in the text. To address these challenges, we design a three-stage framework COLA (short for Collaborative rOle-infused LLM-based Agents) in which LLMs are designated distinct roles, creating a collaborative system where each role contributes uniquely. Initially, in the multidimensional text analysis stage, we configure the LLMs to act as a linguistic expert, a domain specialist, and a social media veteran to get a multifaceted analysis of texts, thus overcoming the first challenge. Next, in the reasoning-enhanced debating stage, for each potential stance, we designate a specific LLM-based agent to advocate for it, guiding the LLM to detect logical connections between text features and stance, tackling the second challenge. Finally, in the stance conclusion stage, a final decision maker agent consolidates prior insights to determine the stance. Our approach avoids extra annotated data and model training and is highly usable. We achieve state-of-the-art performance across multiple datasets. Ablation studies validate the effectiveness of each design role in handling stance detection. Further experiments have demonstrated the explainability and the versatility of our approach. Our approach excels in usability, accuracy, effectiveness, explainability and versatility, highlighting its value.
NEON: Living Needs Prediction System in Meituan
Jul 31, 2023



Living needs refer to the various needs in human's daily lives for survival and well-being, including food, housing, entertainment, etc. On life service platforms that connect users to service providers, such as Meituan, the problem of living needs prediction is fundamental as it helps understand users and boost various downstream applications such as personalized recommendation. However, the problem has not been well explored and is faced with two critical challenges. First, the needs are naturally connected to specific locations and times, suffering from complex impacts from the spatiotemporal context. Second, there is a significant gap between users' actual living needs and their historical records on the platform. To address these two challenges, we design a system of living NEeds predictiON named NEON, consisting of three phases: feature mining, feature fusion, and multi-task prediction. In the feature mining phase, we carefully extract individual-level user features for spatiotemporal modeling, and aggregated-level behavioral features for enriching data, which serve as the basis for addressing two challenges, respectively. Further, in the feature fusion phase, we propose a neural network that effectively fuses two parts of features into the user representation. Moreover, we design a multi-task prediction phase, where the auxiliary task of needs-meeting way prediction can enhance the modeling of spatiotemporal context. Extensive offline evaluations verify that our NEON system can effectively predict users' living needs. Furthermore, we deploy NEON into Meituan's algorithm engine and evaluate how it enhances the three downstream prediction applications, via large-scale online A/B testing.