 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen3DVQA: A Benchmark for Comprehensive Spatial Reasoning with Multimodal Large Language Model in Open Space
Mar 14, 2025Spatial reasoning is a fundamental capability of embodied agents and has garnered widespread attention in the field of multimodal large language models (MLLMs). In this work, we propose a novel benchmark, Open3DVQA, to comprehensively evaluate the spatial reasoning capacities of current state-of-the-art (SOTA) foundation models in open 3D space. Open3DVQA consists of 9k VQA samples, collected using an efficient semi-automated tool in a high-fidelity urban simulator. We evaluate several SOTA MLLMs across various aspects of spatial reasoning, such as relative and absolute spatial relationships, situational reasoning, and object-centric spatial attributes. Our results reveal that: 1) MLLMs perform better at answering questions regarding relative spatial relationships than absolute spatial relationships, 2) MLLMs demonstrate similar spatial reasoning abilities for both egocentric and allocentric perspectives, and 3) Fine-tuning large models significantly improves their performance across different spatial reasoning tasks. We believe that our open-source data collection tools and in-depth analyses will inspire further research on MLLM spatial reasoning capabilities. The benchmark is available at https://github.com/WeichenZh/Open3DVQA.
AgentSociety Challenge: Designing LLM Agents for User Modeling and Recommendation on Web Platforms
Feb 26, 2025The AgentSociety Challenge is the first competition in the Web Conference that aims to explore the potential of Large Language Model (LLM) agents in modeling user behavior and enhancing recommender systems on web platforms. The Challenge consists of two tracks: the User Modeling Track and the Recommendation Track. Participants are tasked to utilize a combined dataset from Yelp, Amazon, and Goodreads, along with an interactive environment simulator, to develop innovative LLM agents. The Challenge has attracted 295 teams across the globe and received over 1,400 submissions in total over the course of 37 official competition days. The participants have achieved 21.9% and 20.3% performance improvement for Track 1 and Track 2 in the Development Phase, and 9.1% and 15.9% in the Final Phase, representing a significant accomplishment. This paper discusses the detailed designs of the Challenge, analyzes the outcomes, and highlights the most successful LLM agent designs. To support further research and development, we have open-sourced the benchmark environment at https://tsinghua-fib-lab.github.io/AgentSocietyChallenge.
CityEQA: A Hierarchical LLM Agent on Embodied Question Answering Benchmark in City Space
Feb 20, 2025Embodied Question Answering (EQA) has primarily focused on indoor environments, leaving the complexities of urban settings - spanning environment, action, and perception - largely unexplored. To bridge this gap, we introduce CityEQA, a new task where an embodied agent answers open-vocabulary questions through active exploration in dynamic city spaces. To support this task, we present CityEQA-EC, the first benchmark dataset featuring 1,412 human-annotated tasks across six categories, grounded in a realistic 3D urban simulator. Moreover, we propose Planner-Manager-Actor (PMA), a novel agent tailored for CityEQA. PMA enables long-horizon planning and hierarchical task execution: the Planner breaks down the question answering into sub-tasks, the Manager maintains an object-centric cognitive map for spatial reasoning during the process control, and the specialized Actors handle navigation, exploration, and collection sub-tasks. Experiments demonstrate that PMA achieves 60.7% of human-level answering accuracy, significantly outperforming frontier-based baselines. While promising, the performance gap compared to humans highlights the need for enhanced visual reasoning in CityEQA. This work paves the way for future advancements in urban spatial intelligence. Dataset and code are available at https://github.com/BiluYong/CityEQA.git.
AgentSociety: Large-Scale Simulation of LLM-Driven Generative Agents Advances Understanding of Human Behaviors and Society
Feb 12, 2025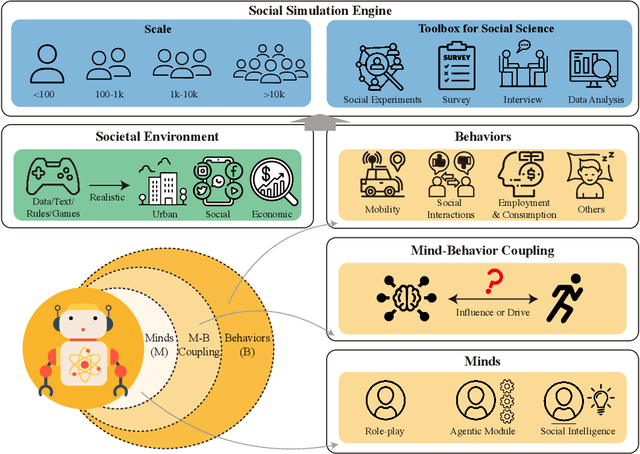
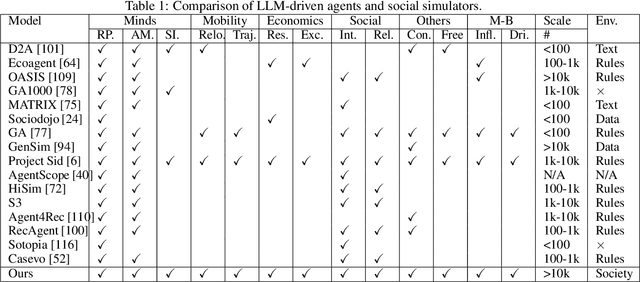
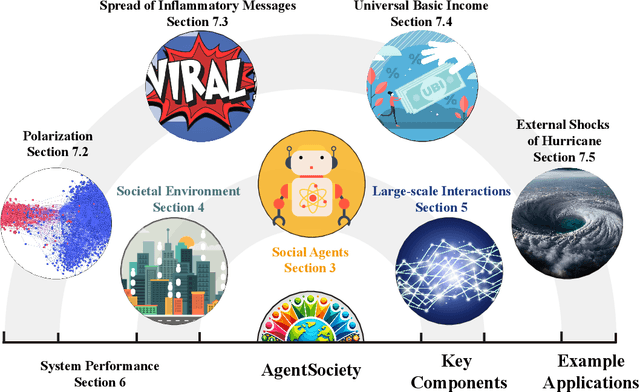

Understanding human behavior and society is a central focus in social sciences, with the rise of generative social science marking a significant paradigmatic shift. By leveraging bottom-up simulations, it replaces costly and logistically challenging traditional experiments with scalable, replicable, and systematic computational approaches for studying complex social dynamics. Recent advances in large language models (LLMs) have further transformed this research paradigm, enabling the creation of human-like generative social agents and realistic simulacra of society. In this paper, we propose AgentSociety, a large-scale social simulator that integrates LLM-driven agents, a realistic societal environment, and a powerful large-scale simulation engine. Based on the proposed simulator, we generate social lives for over 10k agents, simulating their 5 million interactions both among agents and between agents and their environment. Furthermore, we explore the potential of AgentSociety as a testbed for computational social experiments, focusing on four key social issues: polarization, the spread of inflammatory messages, the effects of universal basic income policies, and the impact of external shocks such as hurricanes. These four issues serve as valuable cases for assessing AgentSociety's support for typical research methods -- such as surveys, interviews, and interventions -- as well as for investigating the patterns, causes, and underlying mechanisms of social issues. The alignment between AgentSociety's outcomes and real-world experimental results not only demonstrates its ability to capture human behaviors and their underlying mechanisms, but also underscores its potential as an important platform for social scientists and policymakers.
EmbodiedCity: A Benchmark Platform for Embodied Agent in Real-world City Environment
Oct 12, 2024Embodied artificial intelligence emphasizes the role of an agent's body in generating human-like behaviors. The recent efforts on EmbodiedAI pay a lot of attention to building up machine learning models to possess perceiving, planning, and acting abilities, thereby enabling real-time interaction with the world. However, most works focus on bounded indoor environments, such as navigation in a room or manipulating a device, with limited exploration of embodying the agents in open-world scenarios. That is, embodied intelligence in the open and outdoor environment is less explored, for which one potential reason is the lack of high-quality simulators, benchmarks, and datasets. To address it, in this paper, we construct a benchmark platform for embodied intelligence evaluation in real-world city environments. Specifically, we first construct a highly realistic 3D simulation environment based on the real buildings, roads, and other elements in a real city. In this environment, we combine historically collected data and simulation algorithms to conduct simulations of pedestrian and vehicle flows with high fidelity. Further, we designed a set of evaluation tasks covering different EmbodiedAI abilities. Moreover, we provide a complete set of input and output interfaces for access, enabling embodied agents to easily take task requirements and current environmental observations as input and then make decisions and obtain performance evaluations. On the one hand, it expands the capability of existing embodied intelligence to higher levels. On the other hand, it has a higher practical value in the real world and can support more potential applications for artificial general intelligence. Based on this platform, we evaluate some popular large language models for embodied intelligence capabilities of different dimensions and difficulties.