 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Are Large Multimodal Models from Human-Level Spatial Action? A Benchmark for Goal-Oriented Embodied Navigation in Urban Airspace
Apr 09, 2026Large multimodal models (LMMs) show strong visual-linguistic reasoning but their capacity for spatial decision-making and action remains unclear. In this work, we investigate whether LMMs can achieve embodied spatial action like human through a challenging scenario: goal-oriented navigation in urban 3D spaces. We first spend over 500 hours constructing a dataset comprising 5,037 high-quality goal-oriented navigation samples, with an emphasis on 3D vertical actions and rich urban semantic information. Then, we comprehensively assess 17 representative models, including non-reasoning LMMs, reasoning LMMs, agent-based methods, and vision-language-action models. Experiments show that current LMMs exhibit emerging action capabilities, yet remain far from human-level performance. Furthermore, we reveal an intriguing phenomenon: navigation errors do not accumulate linearly but instead diverge rapidly from the destination after a critical decision bifurcation. The limitations of LMMs are investigated by analyzing their behavior at these critical decision bifurcations. Finally, we experimentally explore four promising directions for improvement: geometric perception, cross-view understanding, spatial imagination, and long-term memory. The project is available at: https://github.com/serenditipy-AC/Embodied-Navigation-Bench.
RecGPT-V2 Technical Report
Dec 16, 2025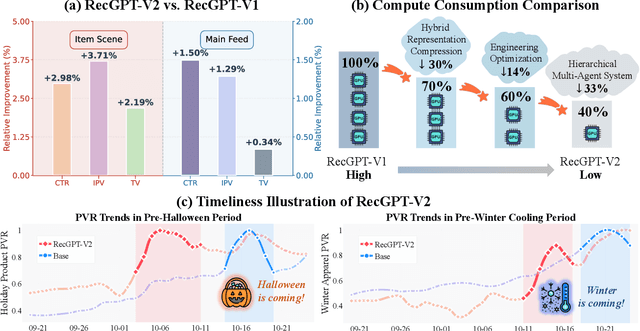
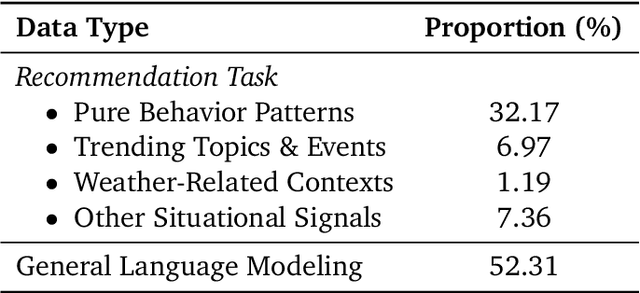
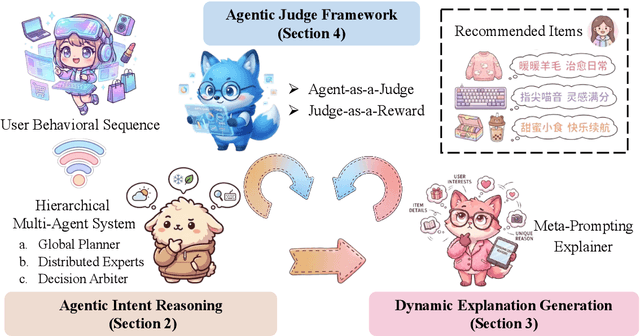

Large language models (LLMs) have demonstrated remarkable potential in transforming recommender systems from implicit behavioral pattern matching to explicit intent reasoning. While RecGPT-V1 successfully pioneered this paradigm by integrating LLM-based reasoning into user interest mining and item tag prediction, it suffers from four fundamental limitations: (1) computational inefficiency and cognitive redundancy across multiple reasoning routes; (2) insufficient explanation diversity in fixed-template generation; (3) limited generalization under supervised learning paradigms; and (4) simplistic outcome-focused evaluation that fails to match human standards. To address these challenges, we present RecGPT-V2 with four key innovations. First, a Hierarchical Multi-Agent System restructures intent reasoning through coordinated collaboration, eliminating cognitive duplication while enabling diverse intent coverage. Combined with Hybrid Representation Inference that compresses user-behavior contexts, our framework reduces GPU consumption by 60% and improves exclusive recall from 9.39% to 10.99%. Second, a Meta-Prompting framework dynamically generates contextually adaptive prompts, improving explanation diversity by +7.3%. Third, constrained reinforcement learning mitigates multi-reward conflicts, achieving +24.1% improvement in tag prediction and +13.0% in explanation acceptance. Fourth, an Agent-as-a-Judge framework decomposes assessment into multi-step reasoning, improving human preference alignment. Online A/B tests on Taobao demonstrate significant improvements: +2.98% CTR, +3.71% IPV, +2.19% TV, and +11.46% NER. RecGPT-V2 establishes both the technical feasibility and commercial viability of deploying LLM-powered intent reasoning at scale, bridging the gap between cognitive exploration and industrial utility.
RecGPT Technical Report
Jul 30, 2025



Recommender systems are among the most impactful applications of artificial intelligence, serving as critical infrastructure connecting users, merchants, and platforms. However, most current industrial systems remain heavily reliant on historical co-occurrence patterns and log-fitting objectives, i.e., optimizing for past user interactions without explicitly modeling user intent. This log-fitting approach often leads to overfitting to narrow historical preferences, failing to capture users' evolving and latent interests. As a result, it reinforces filter bubbles and long-tail phenomena, ultimately harming user experience and threatening the sustainability of the whole recommendation ecosystem. To address these challenges, we rethink the overall design paradigm of recommender systems and propose RecGPT, a next-generation framework that places user intent at the center of the recommendation pipeline. By integrating large language models (LLMs) into key stages of user interest mining, item retrieval, and explanation generation, RecGPT transforms log-fitting recommendation into an intent-centric process. To effectively align general-purpose LLMs to the above domain-specific recommendation tasks at scale, RecGPT incorporates a multi-stage training paradigm, which integrates reasoning-enhanced pre-alignment and self-training evolution, guided by a Human-LLM cooperative judge system. Currently, RecGPT has been fully deployed on the Taobao App. Online experiments demonstrate that RecGPT achieves consistent performance gains across stakeholders: users benefit from increased content diversity and satisfaction, merchants and the platform gain greater exposure and conversions. These comprehensive improvement results across all stakeholders validates that LLM-driven, intent-centric design can foster a more sustainable and mutually beneficial recommendation ecosystem.
Open3DVQA: A Benchmark for Comprehensive Spatial Reasoning with Multimodal Large Language Model in Open Space
Mar 14, 2025Spatial reasoning is a fundamental capability of embodied agents and has garnered widespread attention in the field of multimodal large language models (MLLMs). In this work, we propose a novel benchmark, Open3DVQA, to comprehensively evaluate the spatial reasoning capacities of current state-of-the-art (SOTA) foundation models in open 3D space. Open3DVQA consists of 9k VQA samples, collected using an efficient semi-automated tool in a high-fidelity urban simulator. We evaluate several SOTA MLLMs across various aspects of spatial reasoning, such as relative and absolute spatial relationships, situational reasoning, and object-centric spatial attributes. Our results reveal that: 1) MLLMs perform better at answering questions regarding relative spatial relationships than absolute spatial relationships, 2) MLLMs demonstrate similar spatial reasoning abilities for both egocentric and allocentric perspectives, and 3) Fine-tuning large models significantly improves their performance across different spatial reasoning tasks. We believe that our open-source data collection tools and in-depth analyses will inspire further research on MLLM spatial reasoning capabilities. The benchmark is available at https://github.com/WeichenZh/Open3DVQA.
EmbodiedCity: A Benchmark Platform for Embodied Agent in Real-world City Environment
Oct 12, 2024Embodied artificial intelligence emphasizes the role of an agent's body in generating human-like behaviors. The recent efforts on EmbodiedAI pay a lot of attention to building up machine learning models to possess perceiving, planning, and acting abilities, thereby enabling real-time interaction with the world. However, most works focus on bounded indoor environments, such as navigation in a room or manipulating a device, with limited exploration of embodying the agents in open-world scenarios. That is, embodied intelligence in the open and outdoor environment is less explored, for which one potential reason is the lack of high-quality simulators, benchmarks, and datasets. To address it, in this paper, we construct a benchmark platform for embodied intelligence evaluation in real-world city environments. Specifically, we first construct a highly realistic 3D simulation environment based on the real buildings, roads, and other elements in a real city. In this environment, we combine historically collected data and simulation algorithms to conduct simulations of pedestrian and vehicle flows with high fidelity. Further, we designed a set of evaluation tasks covering different EmbodiedAI abilities. Moreover, we provide a complete set of input and output interfaces for access, enabling embodied agents to easily take task requirements and current environmental observations as input and then make decisions and obtain performance evaluations. On the one hand, it expands the capability of existing embodied intelligence to higher levels. On the other hand, it has a higher practical value in the real world and can support more potential applications for artificial general intelligence. Based on this platform, we evaluate some popular large language models for embodied intelligence capabilities of different dimensions and difficulties.
CUGE: A Chinese Language Understanding and Generation Evaluation Benchmark
Dec 27, 2021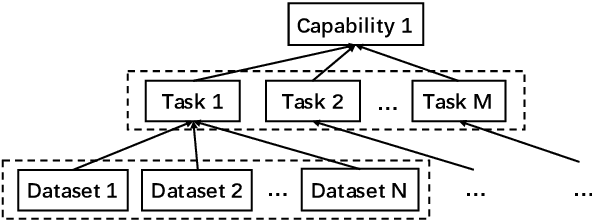
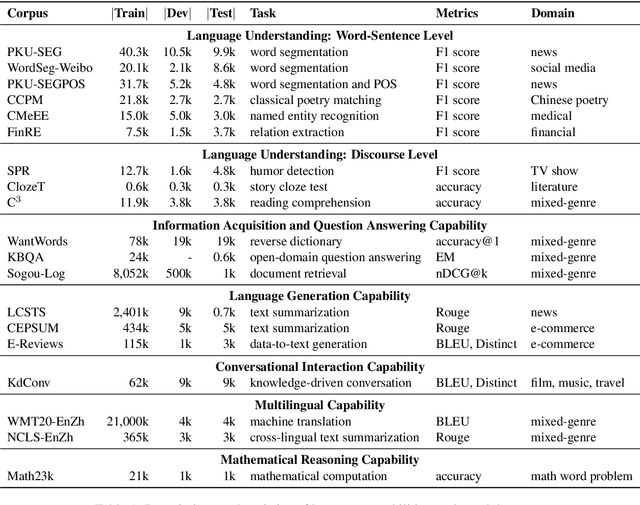


Realizing general-purpose language intelligence has been a longstanding goal for natural language processing, where standard evaluation benchmarks play a fundamental and guiding role. We argue that for general-purpose language intelligence evaluation, the benchmark itself needs to be comprehensive and systematic. To this end, we propose CUGE, a Chinese Language Understanding and Generation Evaluation benchmark with the following features: (1) Hierarchical benchmark framework, where datasets are principally selected and organized with a language capability-task-dataset hierarchy. (2) Multi-level scoring strategy, where different levels of model performance are provided based on the hierarchical framework. To facilitate CUGE, we provide a public leaderboard that can be customized to support flexible model judging criteria. Evaluation results on representative pre-trained language models indicate ample room for improvement towards general-purpose language intelligence. CUGE is publicly available at cuge.baai.ac.cn.