 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll Languages Matter: Understanding and Mitigating Language Bias in Multilingual RAG
Apr 22, 2026Multilingual Retrieval-Augmented Generation (mRAG) leverages cross-lingual evidence to ground Large Language Models (LLMs) in global knowledge. However, we show that current mRAG systems suffer from a language bias during reranking, systematically favoring English and the query's native language. By introducing an estimated oracle evidence analysis, we quantify a substantial performance gap between existing rerankers and the achievable upper bound. Further analysis reveals a critical distributional mismatch: while optimal predictions require evidence scattered across multiple languages, current systems systematically suppress such ``answer-critical'' documents, thereby limiting downstream generation performance. To bridge this gap, we propose \textit{\textbf{L}anguage-\textbf{A}gnostic \textbf{U}tility-driven \textbf{R}eranker \textbf{A}lignment (LAURA)}, which aligns multilingual evidence ranking with downstream generative utility. Experiments across diverse languages and generation models show that LAURA effectively mitigates language bias and consistently improves mRAG performance.
Towards Real-world Human Behavior Simulation: Benchmarking Large Language Models on Long-horizon, Cross-scenario, Heterogeneous Behavior Traces
Apr 09, 2026The emergence of Large Language Models (LLMs) has illuminated the potential for a general-purpose user simulator. However, existing benchmarks remain constrained to isolated scenarios, narrow action spaces, or synthetic data, failing to capture the holistic nature of authentic human behavior. To bridge this gap, we introduce OmniBehavior, the first user simulation benchmark constructed entirely from real-world data, integrating long-horizon, cross-scenario, and heterogeneous behavioral patterns into a unified framework. Based on this benchmark, we first provide empirical evidence that previous datasets with isolated scenarios suffer from tunnel vision, whereas real-world decision-making relies on long-term, cross-scenario causal chains. Extensive evaluations of state-of-the-art LLMs reveal that current models struggle to accurately simulate these complex behaviors, with performance plateauing even as context windows expand. Crucially, a systematic comparison between simulated and authentic behaviors uncovers a fundamental structural bias: LLMs tend to converge toward a positive average person, exhibiting hyper-activity, persona homogenization, and a Utopian bias. This results in the loss of individual differences and long-tail behaviors, highlighting critical directions for future high-fidelity simulation research.
P^2O: Joint Policy and Prompt Optimization
Mar 23, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a powerful paradigm for enhancing the reasoning capabilities of Large Language Models (LLMs). However, vanilla RLVR suffers from inefficient exploration, particularly when confronting "hard samples" that yield nearzero success rates. In such scenarios, the reliance on sparse outcome rewards typically results in zero-advantage estimates, effectively starving the model of supervision signals despite the high informational value of these instances. To address this, we propose P^2O, a novel framework that synergizes Prompt Optimization with Policy Optimization. P^2O identifies hard samples during training iterations and leverages the GeneticPareto (GEPA) prompt optimization algorithm to evolve prompt templates that guide the model toward discovering successful trajectories. Crucially, unlike traditional prompt engineering methods that rely on input augmentation, P^2O distills the reasoning gains induced by these optimized prompts directly into the model parameters. This mechanism provides denser positive supervision signals for hard samples and accelerates convergence. Extensive experiments demonstrate that P^2O not only achieves superior performance on in-distribution datasets but also exhibits strong generalization, yielding substantial improvements on out-of-distribution benchmarks (+4.7% avg.).
Decoupling Reasoning and Confidence: Resurrecting Calibration in Reinforcement Learning from Verifiable Rewards
Mar 10, 2026Reinforcement Learning from Verifiable Rewards (RLVR) significantly enhances large language models (LLMs) reasoning but severely suffers from calibration degeneration, where models become excessively over-confident in incorrect answers. Previous studies devote to directly incorporating calibration objective into existing optimization target. However, our theoretical analysis demonstrates that there exists a fundamental gradient conflict between the optimization for maximizing policy accuracy and minimizing calibration error. Building on this insight, we propose DCPO, a simple yet effective framework that systematically decouples reasoning and calibration objectives. Extensive experiments demonstrate that our DCPO not only preserves accuracy on par with GRPO but also achieves the best calibration performance and substantially mitigates the over-confidence issue. Our study provides valuable insights and practical solution for more reliable LLM deployment.
Memorizing is Not Enough: Deep Knowledge Injection Through Reasoning
Apr 01, 2025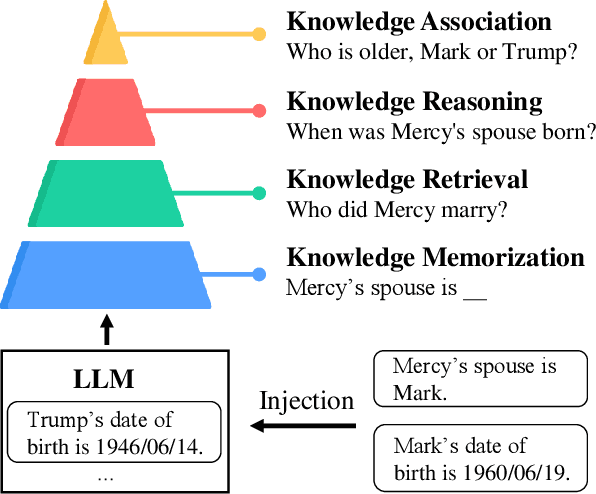
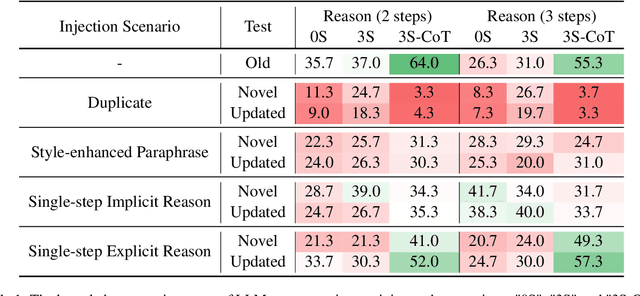
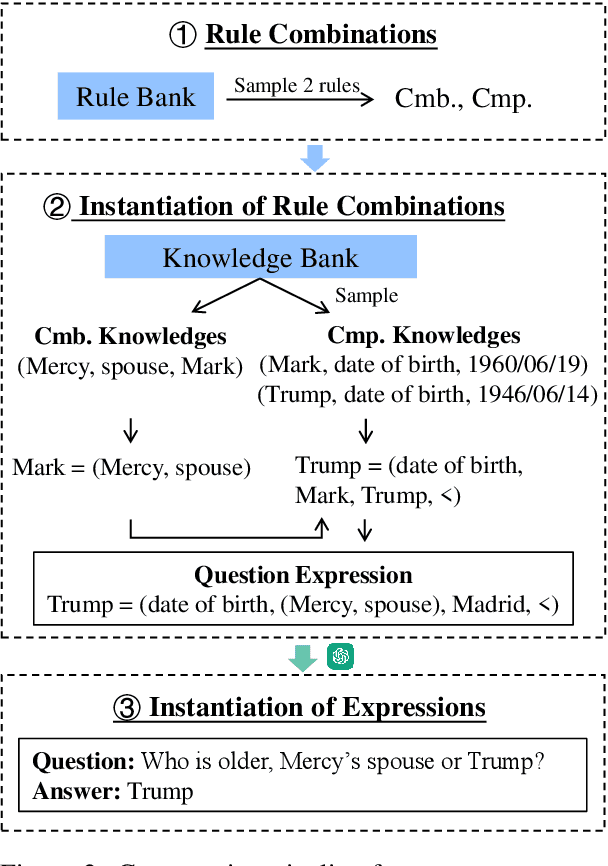
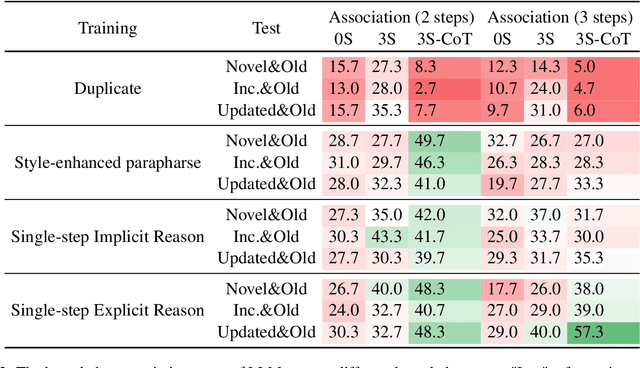
Although large language models (LLMs) excel in knowledge recall and reasoning, their static nature leads to outdated information as the real world evolves or when adapting to domain-specific knowledge, highlighting the need for effective knowledge injection. However, current research on knowledge injection remains superficial, mainly focusing on knowledge memorization and retrieval. This paper proposes a four-tier knowledge injection framework that systematically defines the levels of knowledge injection: memorization, retrieval, reasoning, and association. Based on this framework, we introduce DeepKnowledge, a synthetic experimental testbed designed for fine-grained evaluation of the depth of knowledge injection across three knowledge types (novel, incremental, and updated). We then explore various knowledge injection scenarios and evaluate the depth of knowledge injection for each scenario on the benchmark. Experimental results reveal key factors to reach each level of knowledge injection for LLMs and establish a mapping between the levels of knowledge injection and the corresponding suitable injection methods, aiming to provide a comprehensive approach for efficient knowledge injection across various levels.
Search, Verify and Feedback: Towards Next Generation Post-training Paradigm of Foundation Models via Verifier Engineering
Nov 18, 2024



The evolution of machine learning has increasingly prioritized the development of powerful models and more scalable supervision signals. However, the emergence of foundation models presents significant challenges in providing effective supervision signals necessary for further enhancing their capabilities. Consequently, there is an urgent need to explore novel supervision signals and technical approaches. In this paper, we propose verifier engineering, a novel post-training paradigm specifically designed for the era of foundation models. The core of verifier engineering involves leveraging a suite of automated verifiers to perform verification tasks and deliver meaningful feedback to foundation models. We systematically categorize the verifier engineering process into three essential stages: search, verify, and feedback, and provide a comprehensive review of state-of-the-art research developments within each stage. We believe that verifier engineering constitutes a fundamental pathway toward achieving Artificial General Intelligence.
Multi-Facet Counterfactual Learning for Content Quality Evaluation
Oct 10, 2024
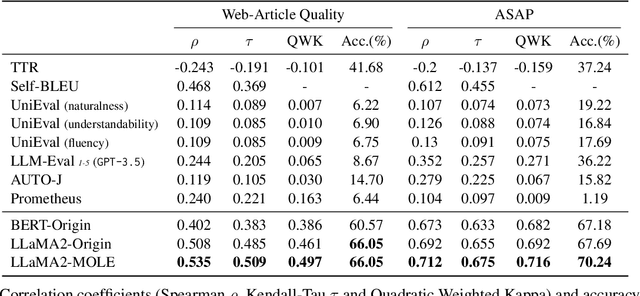

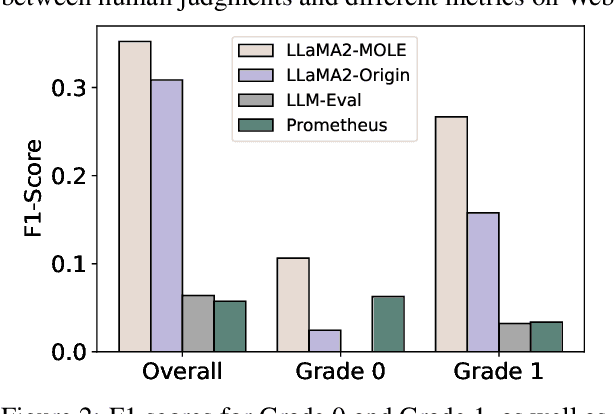
Evaluating the quality of documents is essential for filtering valuable content from the current massive amount of information. Conventional approaches typically rely on a single score as a supervision signal for training content quality evaluators, which is inadequate to differentiate documents with quality variations across multiple facets. In this paper, we propose Multi-facet cOunterfactual LEarning (MOLE), a framework for efficiently constructing evaluators that perceive multiple facets of content quality evaluation. Given a specific scenario, we prompt large language models to generate counterfactual content that exhibits variations in critical quality facets compared to the original document. Furthermore, we leverage a joint training strategy based on contrastive learning and supervised learning to enable the evaluator to distinguish between different quality facets, resulting in more accurate predictions of content quality scores. Experimental results on 2 datasets across different scenarios demonstrate that our proposed MOLE framework effectively improves the correlation of document content quality evaluations with human judgments, which serve as a valuable toolkit for effective information acquisition.
Critic-CoT: Boosting the reasoning abilities of large language model via Chain-of-thoughts Critic
Aug 29, 2024



Self-critic has become an important mechanism for enhancing the reasoning performance of LLMs. However, current approaches mainly involve basic prompts without further training, which tend to be over-simplified, leading to limited accuracy.Moreover, there is a lack of in-depth investigation of the relationship between LLM's ability to criticism and its task-solving performance.To address these issues, we propose Critic-CoT, a novel framework that pushes LLMs toward System-2-like critic capability, via step-wise CoT reasoning format and distant-supervision data construction, without the need for human annotation. Experiments on GSM8K and MATH show that via filtering out invalid solutions or iterative refinement, our enhanced model boosts task-solving performance, which demonstrates the effectiveness of our method. Further, we find that training on critique and refinement alone improves the generation. We hope our work could shed light on future research on improving the reasoning and critic ability of LLMs.
StructEval: Deepen and Broaden Large Language Model Assessment via Structured Evaluation
Aug 07, 2024



Evaluation is the baton for the development of large language models. Current evaluations typically employ a single-item assessment paradigm for each atomic test objective, which struggles to discern whether a model genuinely possesses the required capabilities or merely memorizes/guesses the answers to specific questions. To this end, we propose a novel evaluation framework referred to as StructEval. Starting from an atomic test objective, StructEval deepens and broadens the evaluation by conducting a structured assessment across multiple cognitive levels and critical concepts, and therefore offers a comprehensive, robust and consistent evaluation for LLMs. Experiments on three widely-used benchmarks demonstrate that StructEval serves as a reliable tool for resisting the risk of data contamination and reducing the interference of potential biases, thereby providing more reliable and consistent conclusions regarding model capabilities. Our framework also sheds light on the design of future principled and trustworthy LLM evaluation protocols.
Beyond Correctness: Benchmarking Multi-dimensional Code Generation for Large Language Models
Jul 16, 2024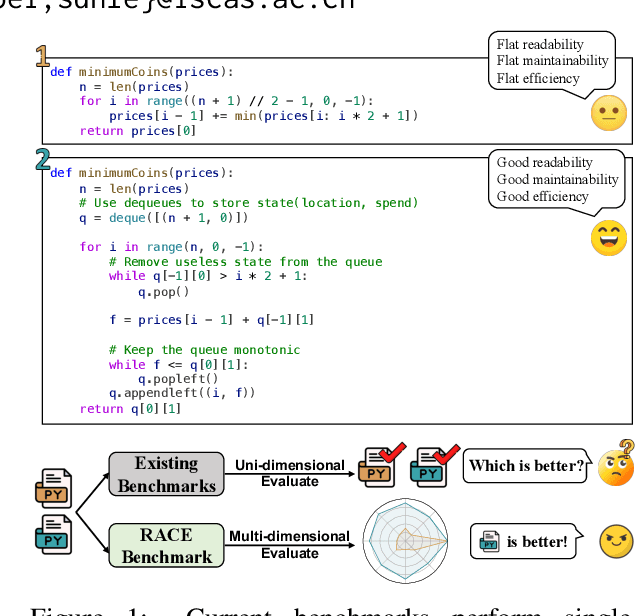
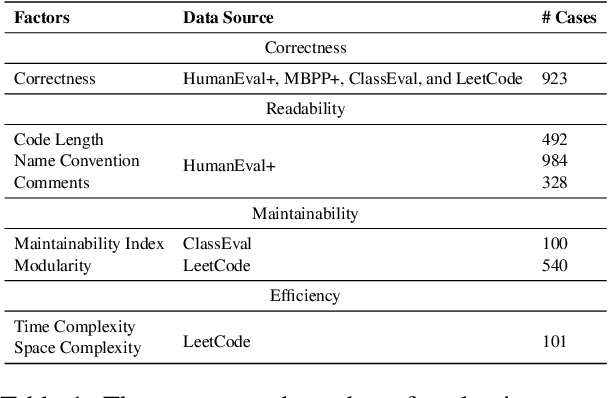
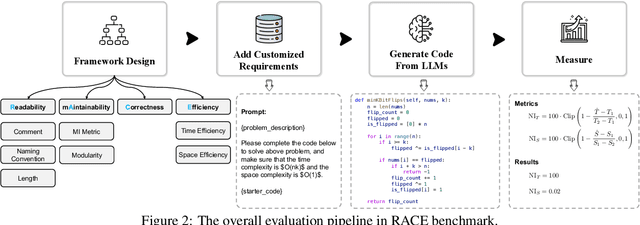
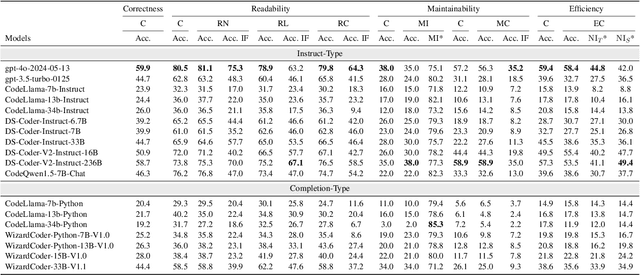
In recent years, researchers have proposed numerous benchmarks to evaluate the impressive coding capabilities of large language models (LLMs). However, existing benchmarks primarily focus on assessing the correctness of code generated by LLMs, while neglecting other critical dimensions that also significantly impact code quality. Therefore, this paper proposes the RACE benchmark, which comprehensively evaluates the quality of code generated by LLMs across 4 dimensions: Readability, mAintainability, Correctness, and Efficiency. Specifically, considering the demand-dependent nature of dimensions beyond correctness, we design various types of user requirements for each dimension to assess the model's ability to generate correct code that also meets user demands. We evaluate 18 representative LLMs on RACE and find that: 1) the current LLMs' ability to generate high-quality code on demand does not yet meet the requirements of software development; 2) readability serves as a critical indicator of the overall quality of generated code; 3) most LLMs exhibit an inherent preference for specific coding style. These findings can help researchers gain a deeper understanding of the coding capabilities of current LLMs and shed light on future directions for model improvement.