 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Facet Counterfactual Learning for Content Quality Evaluation
Oct 10, 2024Evaluating the quality of documents is essential for filtering valuable content from the current massive amount of information. Conventional approaches typically rely on a single score as a supervision signal for training content quality evaluators, which is inadequate to differentiate documents with quality variations across multiple facets. In this paper, we propose Multi-facet cOunterfactual LEarning (MOLE), a framework for efficiently constructing evaluators that perceive multiple facets of content quality evaluation. Given a specific scenario, we prompt large language models to generate counterfactual content that exhibits variations in critical quality facets compared to the original document. Furthermore, we leverage a joint training strategy based on contrastive learning and supervised learning to enable the evaluator to distinguish between different quality facets, resulting in more accurate predictions of content quality scores. Experimental results on 2 datasets across different scenarios demonstrate that our proposed MOLE framework effectively improves the correlation of document content quality evaluations with human judgments, which serve as a valuable toolkit for effective information acquisition.
Beyond Correctness: Benchmarking Multi-dimensional Code Generation for Large Language Models
Jul 16, 2024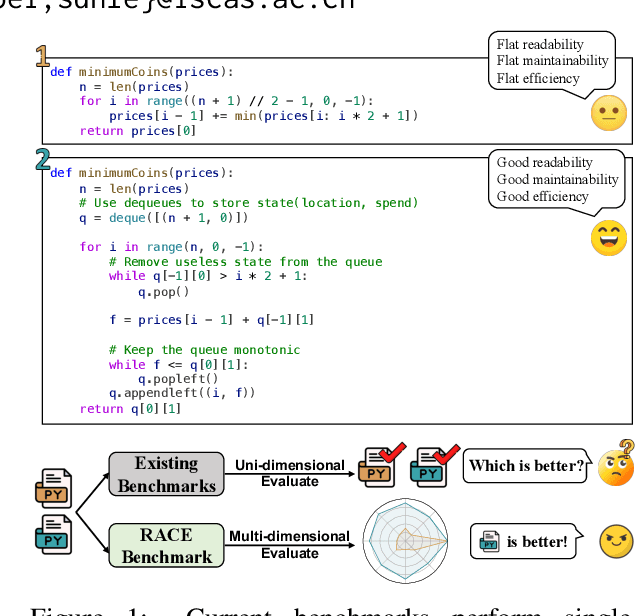
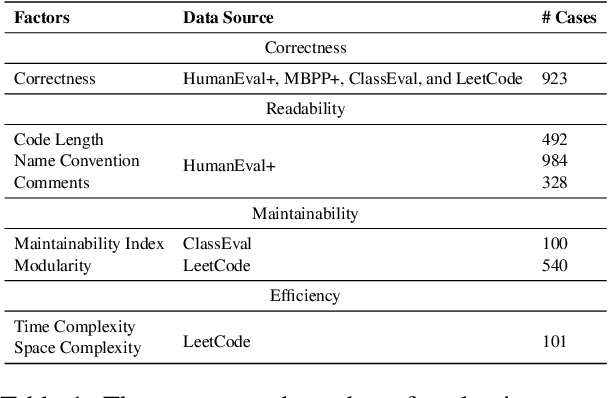
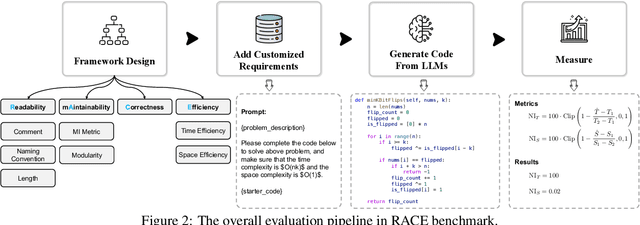
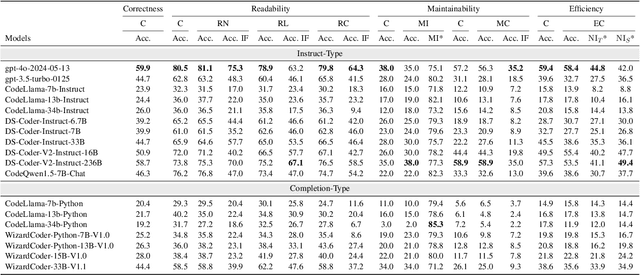
In recent years, researchers have proposed numerous benchmarks to evaluate the impressive coding capabilities of large language models (LLMs). However, existing benchmarks primarily focus on assessing the correctness of code generated by LLMs, while neglecting other critical dimensions that also significantly impact code quality. Therefore, this paper proposes the RACE benchmark, which comprehensively evaluates the quality of code generated by LLMs across 4 dimensions: Readability, mAintainability, Correctness, and Efficiency. Specifically, considering the demand-dependent nature of dimensions beyond correctness, we design various types of user requirements for each dimension to assess the model's ability to generate correct code that also meets user demands. We evaluate 18 representative LLMs on RACE and find that: 1) the current LLMs' ability to generate high-quality code on demand does not yet meet the requirements of software development; 2) readability serves as a critical indicator of the overall quality of generated code; 3) most LLMs exhibit an inherent preference for specific coding style. These findings can help researchers gain a deeper understanding of the coding capabilities of current LLMs and shed light on future directions for model improvement.