 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Correctness: Benchmarking Multi-dimensional Code Generation for Large Language Models
Paper and Code
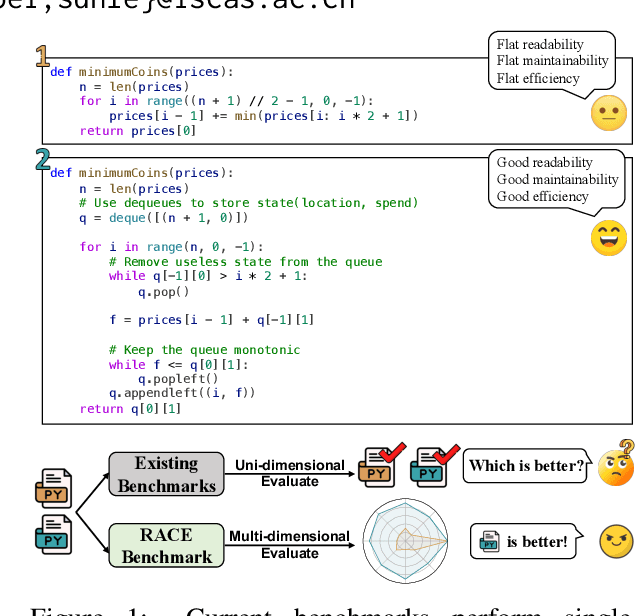
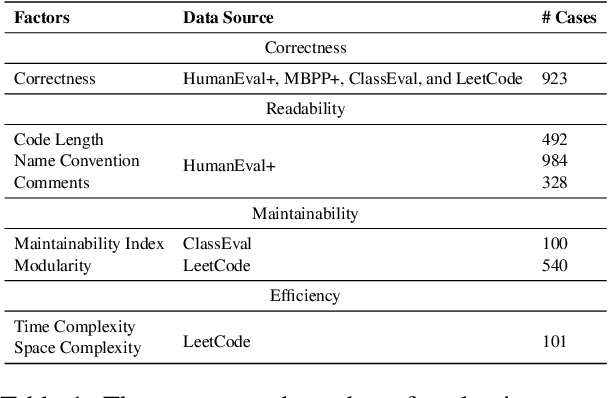
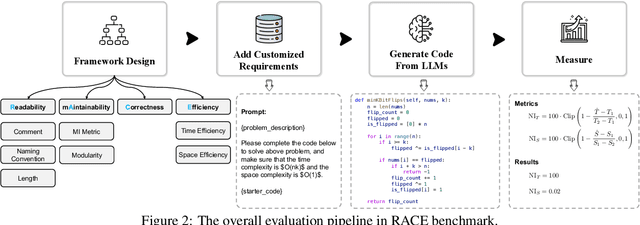
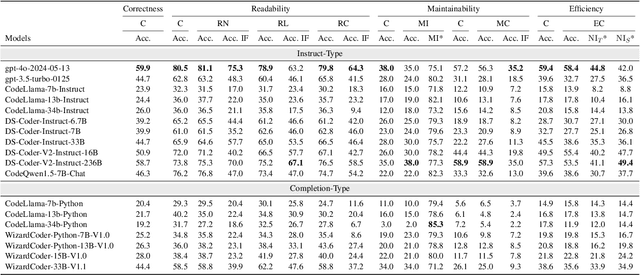
In recent years, researchers have proposed numerous benchmarks to evaluate the impressive coding capabilities of large language models (LLMs). However, existing benchmarks primarily focus on assessing the correctness of code generated by LLMs, while neglecting other critical dimensions that also significantly impact code quality. Therefore, this paper proposes the RACE benchmark, which comprehensively evaluates the quality of code generated by LLMs across 4 dimensions: Readability, mAintainability, Correctness, and Efficiency. Specifically, considering the demand-dependent nature of dimensions beyond correctness, we design various types of user requirements for each dimension to assess the model's ability to generate correct code that also meets user demands. We evaluate 18 representative LLMs on RACE and find that: 1) the current LLMs' ability to generate high-quality code on demand does not yet meet the requirements of software development; 2) readability serves as a critical indicator of the overall quality of generated code; 3) most LLMs exhibit an inherent preference for specific coding style. These findings can help researchers gain a deeper understanding of the coding capabilities of current LLMs and shed light on future directions for model improvement.