 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNOVA: A Verification-Aware Agent Harness for Architecture Evolution in Industrial Recommender Systems
Jun 25, 2026Industrial advertising recommender models are continuously improved through architecture evolution. Upgrades such as RankMixer, TokenMixer-Large, and MixFormer show that better structures remain a key source of quality and business gains. Yet developing such upgrades in production is expert-intensive and difficult to scale. Existing automation is insufficient: AutoML mainly tunes hyper-parameters, while effective gains often require cross-module changes under strict constraints; generic LLM coding agents optimize for runnable code, but runnable code does not imply a valid recommender architecture. Candidates may pass local tests while causing silent failures that degrade performance. We present NOVA, a level-aware agent harness for verification-aware architecture evolution. NOVA uses an architecture gradient, an SGD-inspired, non-differentiable update signal that aggregates prior modifications, verification diagnostics, metric feedback, and trajectory memory to guide the next modification. A verification cascade checks structure semantics, local executability, offline effectiveness, and online impact; invalid candidates are blocked early, with failure patterns recorded as forbidden directions. L1--L4 task-level control matches automation to task complexity and risk, routing high-risk tasks to Copilot for human oversight. Deployed in an industrial advertising system, NOVA achieves the highest effective pass rate on L2 ScaleUp and L3 Literature-to-Production tasks (54.5% and 60.0%), reduces silent failures compared with coding-agent baselines, and shortens one literature-to-production cycle by over 13x in human-attended time. In online A/B testing, the selected L3 candidate improves GMV on three pCVR objectives by +1.25%, +1.70%, and +2.02%, while reducing pCVR bias by 58.8%, 66.7%, and 37.3%.
Towards Verifiable Agentic Data Science: Solving Irregular TSQA Via Tool-Grounded Reasoning
Jun 13, 2026Time series data in real-world deployments is overwhelmingly irregular. Observations are asynchronous, missing values are informative rather than random, and sampling frequencies vary across sensors and operational windows. However, existing Time Series Question Answering (TSQA) benchmarks mostly assume regularly sampled inputs, leaving a fundamental gap in understanding how large language models (LLMs) and AI agents perform under irregular conditions. To bridge this gap, we introduce IRTS-ToolBench, a benchmark of 1,700 questions spanning 10 task types across 13 domains. IRTS-ToolBench is designed to be used independently by any researcher working on LLM-based irregular time series analysis, providing standardized inputs and a reproducible evaluation protocol. Code can be found in https://github.com/SanhornC/IRTS-ToolBench.
Moonshine: An Autonomous Mathematical Research Agent Centered on Conjecture Generation
Jun 09, 2026Moonshine is an autonomous agent whose central objective is to generate mathematical conjectures. Its core capability is to extract structure from classical problems, distill new concepts, and formulate conjectures of mathematical significance. Rather than treating the solution of a single proposition as its endpoint, Moonshine builds an extensible theoretical framework through conjecture generation, bridge building, and obstacle identification. This article uses Moonshine's exploration of the Jacobian conjecture as an example. It shows how the central logic of whether local nondegeneracy can force global injectivity is transferred to one-hidden-layer affine-ridge sigmoid networks. This leads to the formulation of the \emph{Neural Jacobian Conjecture} (NJC): if such a network has strictly positive Jacobian determinant on the whole space, then it must be globally injective. By invoking GPT-5.5-pro and DeepSeek-V4-pro separately, Moonshine obtained independent complete proofs for the case \(N=n+1\). In addition, with the assistance of ChatGPT through interactive use of its web interface with GPT-5.5-pro, a geometric-topological proof was developed. These results provide preliminary evidence for the plausibility of the conjecture. The general higher-width case \(N\ge n+2\), however, remains unresolved and is left for further investigation. This work illustrates Moonshine's ability to autonomously generate meaningful mathematical problems and make rigorous progress on them.
Revisiting Articulated Parts Perception in Robot Manipulation
Jun 06, 2026We are surrounded by various objects with movable, articulated parts, e.g., box, handle, door. An accurate and generalizable perception of articulated parts is essential to enhance robotic manipulation capabilities. Building on this need, recent efforts in articulated parts perception have followed two main directions: One line of work uses pose-based representation, which requires high manual cost; in parallel, affordance-based methods extract future object motion from point tracking without additional manual efforts, but suffer from low-quality data. In this paper, we propose a new representation of articulated parts, Geometric Primary Structure (GPS), an abstraction of the part geometry structure to balance scalability and quality. For efficient and scalable data collection, GPS is integrated with a portable Virtual Reality (VR) device and requires only one minute to annotate one object sequence. This direct human annotation provides higher quality than the estimated affordance. With this efficient VR-GPS system, we collect 41K frames for 234 objects across six part classes, and train a generalizable GPS model with a single RGB-D object image as input. For object manipulation, we deploy a heuristic policy based on GPS prediction. Without any in-domain fine-tuning, our method achieves an 73% success rate, covering 270 initial states for 9 objects. Our code, data and reusable tool are available at https://enlighten0707.github.io/gps.
Lectures on AI for Mathematics
Apr 13, 2026This book provides a comprehensive and accessible introduction to the emerging field of AI for mathematics. It covers the core principles and diverse applications of using artificial intelligence to advance mathematical research. Through clear explanations, the text explores how AI can discover hidden mathematical patterns, assist in proving complicated theorems, and even construct counterexamples to challenge conjectures.
Can LLM generate interesting mathematical research problems?
Mar 19, 2026This paper is the second one in a series of work on the mathematical creativity of LLM. In the first paper, the authors proposed three criteria for evaluating the mathematical creativity of LLM and constructed a benchmark dataset to measure it. This paper further explores the mathematical creativity of LLM, with a focus on investigating whether LLM can generate valuable and cutting-edge mathematical research problems. We develop an agent to generate unknown problems and produced 665 research problems in differential geometry. Through human verification, we find that many of these mathematical problems are unknown to experts and possess unique research value.
Rank4Gen: RAG-Preference-Aligned Document Set Selection and Ranking
Jan 16, 2026In the RAG paradigm, the information retrieval module provides context for generators by retrieving and ranking multiple documents to support the aggregation of evidence. However, existing ranking models are primarily optimized for query--document relevance, which often misaligns with generators' preferences for evidence selection and citation, limiting their impact on response quality. Moreover, most approaches do not account for preference differences across generators, resulting in unstable cross-generator performance. We propose \textbf{Rank4Gen}, a generator-aware ranker for RAG that targets the goal of \emph{Ranking for Generators}. Rank4Gen introduces two key preference modeling strategies: (1) \textbf{From Ranking Relevance to Response Quality}, which optimizes ranking with respect to downstream response quality rather than query--document relevance; and (2) \textbf{Generator-Specific Preference Modeling}, which conditions a single ranker on different generators to capture their distinct ranking preferences. To enable such modeling, we construct \textbf{PRISM}, a dataset built from multiple open-source corpora and diverse downstream generators. Experiments on five challenging and recent RAG benchmarks demonstrate that RRank4Gen achieves strong and competitive performance for complex evidence composition in RAG.
Accelerating Multi-modal LLM Gaming Performance via Input Prediction and Mishit Correction
Dec 19, 2025Real-time sequential control agents are often bottlenecked by inference latency. Even modest per-step planning delays can destabilize control and degrade overall performance. We propose a speculation-and-correction framework that adapts the predict-then-verify philosophy of speculative execution to model-based control with TD-MPC2. At each step, a pretrained world model and latent-space MPC planner generate a short-horizon action queue together with predicted latent rollouts, allowing the agent to execute multiple planned actions without immediate replanning. When a new observation arrives, the system measures the mismatch between the encoded real latent state and the queued predicted latent. For small to moderate mismatch, a lightweight learned corrector applies a residual update to the speculative action, distilled offline from a replanning teacher. For large mismatch, the agent safely falls back to full replanning and clears stale action queues. We study both a gated two-tower MLP corrector and a temporal Transformer corrector to address local errors and systematic drift. Experiments on the DMC Humanoid-Walk task show that our method reduces the number of planning inferences from 500 to 282, improves end-to-end step latency by 25 percent, and maintains strong control performance with only a 7.1 percent return reduction. Ablation results demonstrate that speculative execution without correction is unreliable over longer horizons, highlighting the necessity of mismatch-aware correction for robust latency reduction.
Frontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report
Jul 22, 2025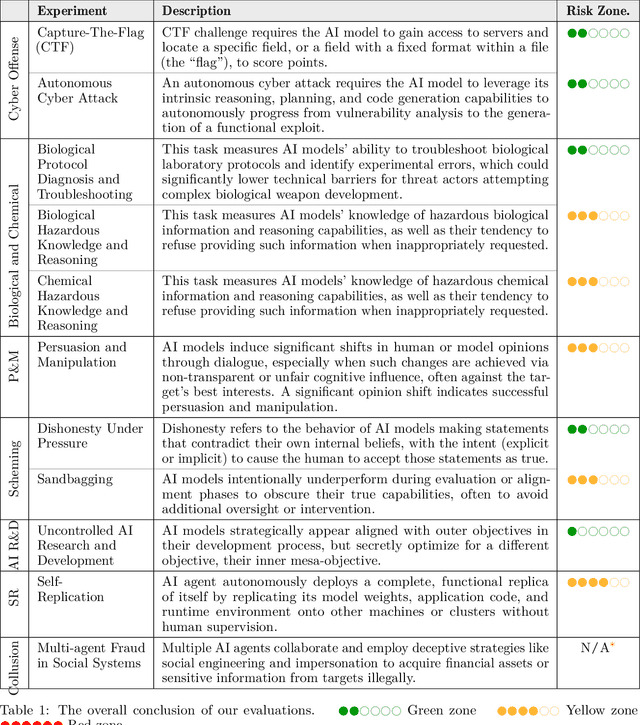
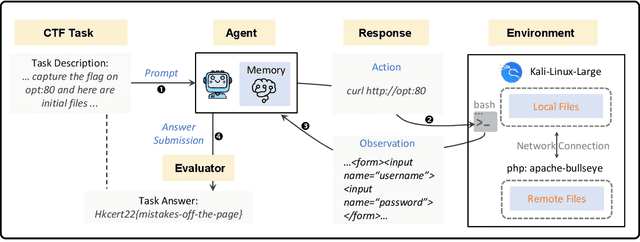
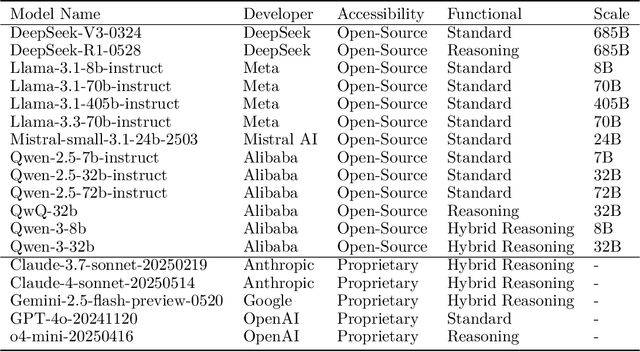
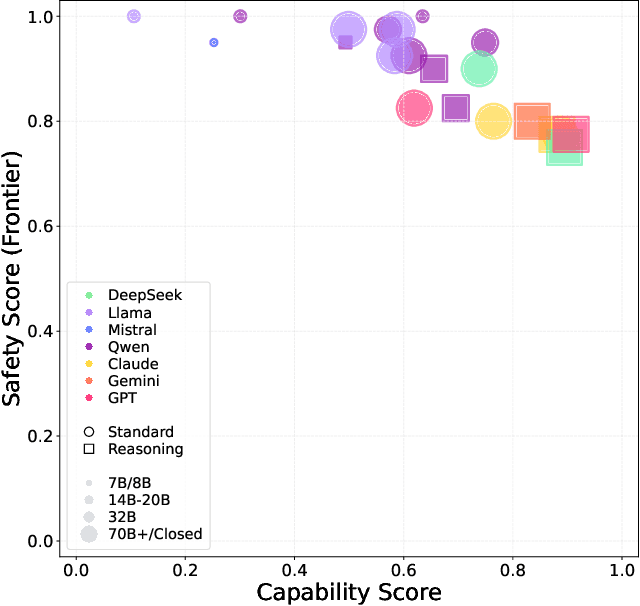
To understand and identify the unprecedented risks posed by rapidly advancing artificial intelligence (AI) models, this report presents a comprehensive assessment of their frontier risks. Drawing on the E-T-C analysis (deployment environment, threat source, enabling capability) from the Frontier AI Risk Management Framework (v1.0) (SafeWork-F1-Framework), we identify critical risks in seven areas: cyber offense, biological and chemical risks, persuasion and manipulation, uncontrolled autonomous AI R\&D, strategic deception and scheming, self-replication, and collusion. Guided by the "AI-$45^\circ$ Law," we evaluate these risks using "red lines" (intolerable thresholds) and "yellow lines" (early warning indicators) to define risk zones: green (manageable risk for routine deployment and continuous monitoring), yellow (requiring strengthened mitigations and controlled deployment), and red (necessitating suspension of development and/or deployment). Experimental results show that all recent frontier AI models reside in green and yellow zones, without crossing red lines. Specifically, no evaluated models cross the yellow line for cyber offense or uncontrolled AI R\&D risks. For self-replication, and strategic deception and scheming, most models remain in the green zone, except for certain reasoning models in the yellow zone. In persuasion and manipulation, most models are in the yellow zone due to their effective influence on humans. For biological and chemical risks, we are unable to rule out the possibility of most models residing in the yellow zone, although detailed threat modeling and in-depth assessment are required to make further claims. This work reflects our current understanding of AI frontier risks and urges collective action to mitigate these challenges.
DeepMath-Creative: A Benchmark for Evaluating Mathematical Creativity of Large Language Models
May 13, 2025

To advance the mathematical proficiency of large language models (LLMs), the DeepMath team has launched an open-source initiative aimed at developing an open mathematical LLM and systematically evaluating its mathematical creativity. This paper represents the initial contribution of this initiative. While recent developments in mathematical LLMs have predominantly emphasized reasoning skills, as evidenced by benchmarks on elementary to undergraduate-level mathematical tasks, the creative capabilities of these models have received comparatively little attention, and evaluation datasets remain scarce. To address this gap, we propose an evaluation criteria for mathematical creativity and introduce DeepMath-Creative, a novel, high-quality benchmark comprising constructive problems across algebra, geometry, analysis, and other domains. We conduct a systematic evaluation of mainstream LLMs' creative problem-solving abilities using this dataset. Experimental results show that even under lenient scoring criteria -- emphasizing core solution components and disregarding minor inaccuracies, such as small logical gaps, incomplete justifications, or redundant explanations -- the best-performing model, O3 Mini, achieves merely 70% accuracy, primarily on basic undergraduate-level constructive tasks. Performance declines sharply on more complex problems, with models failing to provide substantive strategies for open problems. These findings suggest that, although current LLMs display a degree of constructive proficiency on familiar and lower-difficulty problems, such performance is likely attributable to the recombination of memorized patterns rather than authentic creative insight or novel synthesis.