 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Classifier-Free Incremental Learning Framework for Scalable Medical Image Segmentation
May 25, 2024



Current methods for developing foundation models in medical image segmentation rely on two primary assumptions: a fixed set of classes and the immediate availability of a substantial and diverse training dataset. However, this can be impractical due to the evolving nature of imaging technology and patient demographics, as well as labor-intensive data curation, limiting their practical applicability and scalability. To address these challenges, we introduce a novel segmentation paradigm enabling the segmentation of a variable number of classes within a single classifier-free network, featuring an architecture independent of class number. This network is trained using contrastive learning and produces discriminative feature representations that facilitate straightforward interpretation. Additionally, we integrate this strategy into a knowledge distillation-based incremental learning framework, facilitating the gradual assimilation of new information from non-stationary data streams while avoiding catastrophic forgetting. Our approach provides a unified solution for tackling both class- and domain-incremental learning scenarios. We demonstrate the flexibility of our method in handling varying class numbers within a unified network and its capacity for incremental learning. Experimental results on an incompletely annotated, multi-modal, multi-source dataset for medical image segmentation underscore its superiority over state-of-the-art alternative approaches.
Versatile Medical Image Segmentation Learned from Multi-Source Datasets via Model Self-Disambiguation
Nov 17, 2023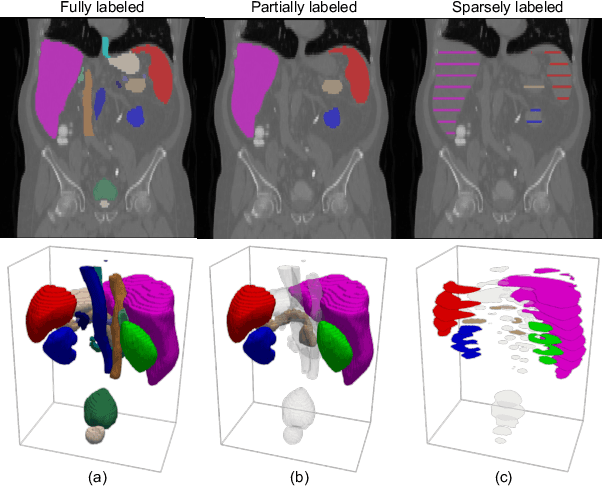
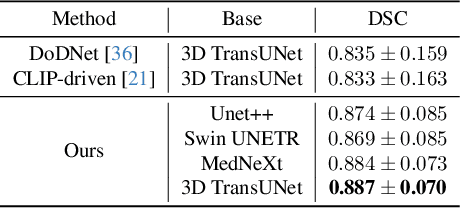
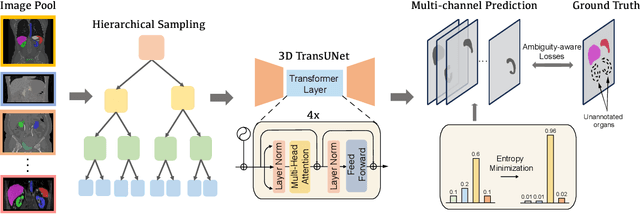

A versatile medical image segmentation model applicable to imaging data collected with diverse equipment and protocols can facilitate model deployment and maintenance. However, building such a model typically requires a large, diverse, and fully annotated dataset, which is rarely available due to the labor-intensive and costly data curation. In this study, we develop a cost-efficient method by harnessing readily available data with partially or even sparsely annotated segmentation labels. We devise strategies for model self-disambiguation, prior knowledge incorporation, and imbalance mitigation to address challenges associated with inconsistently labeled data from various sources, including label ambiguity and imbalances across modalities, datasets, and segmentation labels. Experimental results on a multi-modal dataset compiled from eight different sources for abdominal organ segmentation have demonstrated our method's effectiveness and superior performance over alternative state-of-the-art methods, highlighting its potential for optimizing the use of existing annotated data and reducing the annotation efforts for new data to further enhance model capability.