 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatch, Compare, or Select? An Investigation of Large Language Models for Entity Matching
May 27, 2024Entity matching (EM) is a critical step in entity resolution. Recently, entity matching based on large language models (LLMs) has shown great promise. However, current LLM-based entity matching approaches typically follow a binary matching paradigm that ignores the global consistency between different records. In this paper, we investigate various methodologies for LLM-based entity matching that incorporate record interactions from different perspectives. Specifically, we comprehensively compare three representative strategies: matching, comparing, and selecting, and analyze their respective advantages and challenges in diverse scenarios. Based on our findings, we further design a compositional entity matching (ComEM) framework that leverages the composition of multiple strategies and LLMs. In this way, ComEM can benefit from the advantages of different sides and achieve improvements in both effectiveness and efficiency. Experimental results show that ComEM not only achieves significant performance gains on various datasets but also reduces the cost of LLM-based entity matching in real-world application.
URL: Universal Referential Knowledge Linking via Task-instructed Representation Compression
Apr 24, 2024Linking a claim to grounded references is a critical ability to fulfill human demands for authentic and reliable information. Current studies are limited to specific tasks like information retrieval or semantic matching, where the claim-reference relationships are unique and fixed, while the referential knowledge linking (RKL) in real-world can be much more diverse and complex. In this paper, we propose universal referential knowledge linking (URL), which aims to resolve diversified referential knowledge linking tasks by one unified model. To this end, we propose a LLM-driven task-instructed representation compression, as well as a multi-view learning approach, in order to effectively adapt the instruction following and semantic understanding abilities of LLMs to referential knowledge linking. Furthermore, we also construct a new benchmark to evaluate ability of models on referential knowledge linking tasks across different scenarios. Experiments demonstrate that universal RKL is challenging for existing approaches, while the proposed framework can effectively resolve the task across various scenarios, and therefore outperforms previous approaches by a large margin.
DBCopilot: Scaling Natural Language Querying to Massive Databases
Dec 06, 2023Text-to-SQL simplifies database interactions by enabling non-experts to convert their natural language (NL) questions into Structured Query Language (SQL) queries. While recent advances in large language models (LLMs) have improved the zero-shot text-to-SQL paradigm, existing methods face scalability challenges when dealing with massive, dynamically changing databases. This paper introduces DBCopilot, a framework that addresses these challenges by employing a compact and flexible copilot model for routing across massive databases. Specifically, DBCopilot decouples the text-to-SQL process into schema routing and SQL generation, leveraging a lightweight sequence-to-sequence neural network-based router to formulate database connections and navigate natural language questions through databases and tables. The routed schemas and questions are then fed into LLMs for efficient SQL generation. Furthermore, DBCopilot also introduced a reverse schema-to-question generation paradigm, which can learn and adapt the router over massive databases automatically without requiring manual intervention. Experimental results demonstrate that DBCopilot is a scalable and effective solution for real-world text-to-SQL tasks, providing a significant advancement in handling large-scale schemas.
UUKG: Unified Urban Knowledge Graph Dataset for Urban Spatiotemporal Prediction
Jun 20, 2023Accurate Urban SpatioTemporal Prediction (USTP) is of great importance to the development and operation of the smart city. As an emerging building block, multi-sourced urban data are usually integrated as urban knowledge graphs (UrbanKGs) to provide critical knowledge for urban spatiotemporal prediction models. However, existing UrbanKGs are often tailored for specific downstream prediction tasks and are not publicly available, which limits the potential advancement. This paper presents UUKG, the unified urban knowledge graph dataset for knowledge-enhanced urban spatiotemporal predictions. Specifically, we first construct UrbanKGs consisting of millions of triplets for two metropolises by connecting heterogeneous urban entities such as administrative boroughs, POIs, and road segments. Moreover, we conduct qualitative and quantitative analysis on constructed UrbanKGs and uncover diverse high-order structural patterns, such as hierarchies and cycles, that can be leveraged to benefit downstream USTP tasks. To validate and facilitate the use of UrbanKGs, we implement and evaluate 15 KG embedding methods on the KG completion task and integrate the learned KG embeddings into 9 spatiotemporal models for five different USTP tasks. The extensive experimental results not only provide benchmarks of knowledge-enhanced USTP models under different task settings but also highlight the potential of state-of-the-art high-order structure-aware UrbanKG embedding methods. We hope the proposed UUKG fosters research on urban knowledge graphs and broad smart city applications. The dataset and source code are available at https://github.com/usail-hkust/UUKG/.
KG-MTT-BERT: Knowledge Graph Enhanced BERT for Multi-Type Medical Text Classification
Oct 08, 2022


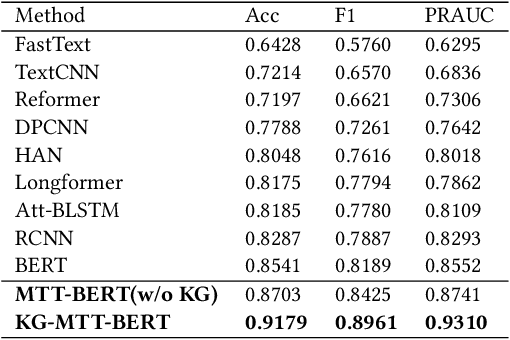
Medical text learning has recently emerged as a promising area to improve healthcare due to the wide adoption of electronic health record (EHR) systems. The complexity of the medical text such as diverse length, mixed text types, and full of medical jargon, poses a great challenge for developing effective deep learning models. BERT has presented state-of-the-art results in many NLP tasks, such as text classification and question answering. However, the standalone BERT model cannot deal with the complexity of the medical text, especially the lengthy clinical notes. Herein, we develop a new model called KG-MTT-BERT (Knowledge Graph Enhanced Multi-Type Text BERT) by extending the BERT model for long and multi-type text with the integration of the medical knowledge graph. Our model can outperform all baselines and other state-of-the-art models in diagnosis-related group (DRG) classification, which requires comprehensive medical text for accurate classification. We also demonstrated that our model can effectively handle multi-type text and the integration of medical knowledge graph can significantly improve the performance.