 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifiable Environments Are LEGO Bricks: Recursive Composition for Reasoning Generalization
Jun 10, 2026Reinforcement Learning (RL) with verifiable environments has emerged as a powerful approach for enhancing the reasoning capabilities of Large Language Models (LLMs). While prior research demonstrates that scaling environment quantity improves RL performance, existing manual or individual construction methods suffer from linear scaling limits, thereby hindering scalable reasoning generalization. This paper introduces RACES (\textbf{R}ecursive \textbf{A}utomated \textbf{C}omposition for \textbf{E}nvironment \textbf{S}caling), a framework that conceptualizes verifiable environments as composable building blocks that can be recursively assembled. The key insight is that when the codomain (output type) of one environment matches the domain (input type) of another, they can be automatically fused into a new verifiable environment, enabling recursive composition. RACES is implemented with 300 individual environments and defines a set of composition operators (\textsc{SEQUENTIAL}, \textsc{PARALLEL}, \textsc{SORT}, and \textsc{SELECT}) that induce diverse reasoning patterns. Extensive experiments show that RL training on these composite environments consistently enhances reasoning generalization. Specifically, RACES improves DeepSeek-R1-Distill-Qwen-14B by an average of 3.1 points (from 48.2 to 51.3) and boosts Qwen3-14B performance from 58.8 to 61.1 on six benchmarks, which are unseen during the construction of training environments. Moreover, RACES achieves performance comparable to training on 300 individual environments using only 50 base environments, demonstrating significant efficiency in environment utilization.
Your Teacher Can't Help You Here: Combating Supervision Fidelity Decay in On-Policy Distillation
May 29, 2026On-policy distillation transfers reasoning capabilities by training a student model on its own generated trajectories using token-level feedback from a teacher. However, we identify a critical bottleneck, \textbf{Supervision Fidelity Decay (SFD)}: as student-generated prefixes lengthen, the teacher's next-token distribution becomes less confident and less discriminative. Consequently, the teacher-dependent corrective signal in reverse-KL distillation weakens, causing student drift to compound across long reasoning chains. To mitigate SFD, we introduce \textbf{Lookahead Group Reward (\ours{})}. Building on the insight that next-step teacher confidence reflects the discriminative strength of future reverse-KL supervision, \ours{} evaluates the student's top-K candidate tokens by the teacher confidence they induce at the subsequent step and assigns a group-normalized reward. To maintain computational efficiency, we further design an entropy-triggered tree-attention mechanism. Across six math and code benchmarks, \ours{} improves mean@8 by \textbf{2.57} points over OPD for a 7B student, with gains increasing in longer-generation and reaching +\textbf{4.92} points on AIME-26 at 39k tokens.
All Languages Matter: Understanding and Mitigating Language Bias in Multilingual RAG
Apr 22, 2026Multilingual Retrieval-Augmented Generation (mRAG) leverages cross-lingual evidence to ground Large Language Models (LLMs) in global knowledge. However, we show that current mRAG systems suffer from a language bias during reranking, systematically favoring English and the query's native language. By introducing an estimated oracle evidence analysis, we quantify a substantial performance gap between existing rerankers and the achievable upper bound. Further analysis reveals a critical distributional mismatch: while optimal predictions require evidence scattered across multiple languages, current systems systematically suppress such ``answer-critical'' documents, thereby limiting downstream generation performance. To bridge this gap, we propose \textit{\textbf{L}anguage-\textbf{A}gnostic \textbf{U}tility-driven \textbf{R}eranker \textbf{A}lignment (LAURA)}, which aligns multilingual evidence ranking with downstream generative utility. Experiments across diverse languages and generation models show that LAURA effectively mitigates language bias and consistently improves mRAG performance.
Beyond Local Edits: Embedding-Virtualized Knowledge for Broader Evaluation and Preservation of Model Editing
Feb 02, 2026Knowledge editing methods for large language models are commonly evaluated using predefined benchmarks that assess edited facts together with a limited set of related or neighboring knowledge. While effective, such evaluations remain confined to finite, dataset-bounded samples, leaving the broader impact of editing on the model's knowledge system insufficiently understood. To address this gap, we introduce Embedding-Virtualized Knowledge (EVK) that characterizes model knowledge through controlled perturbations in embedding space, enabling the exploration of a substantially broader and virtualized knowledge region beyond explicit data annotations. Based on EVK, we construct an embedding-level evaluation benchmark EVK-Bench that quantifies potential knowledge drift induced by editing, revealing effects that are not captured by conventional sample-based metrics. Furthermore, we propose a plug-and-play EVK-Align module that constrains embedding-level knowledge drift during editing and can be seamlessly integrated into existing editing methods. Experiments demonstrate that our approach enables more comprehensive evaluation while significantly improving knowledge preservation without sacrificing editing accuracy.
Identifying and Transferring Reasoning-Critical Neurons: Improving LLM Inference Reliability via Activation Steering
Jan 27, 2026Despite the strong reasoning capabilities of recent large language models (LLMs), achieving reliable performance on challenging tasks often requires post-training or computationally expensive sampling strategies, limiting their practical efficiency. In this work, we first show that a small subset of neurons in LLMs exhibits strong predictive correlations with reasoning correctness. Based on this observation, we propose AdaRAS (Adaptive Reasoning Activation Steering), a lightweight test-time framework that improves reasoning reliability by selectively intervening on neuron activations. AdaRAS identifies Reasoning-Critical Neurons (RCNs) via a polarity-aware mean-difference criterion and adaptively steers their activations during inference, enhancing incorrect reasoning traces while avoiding degradation on already-correct cases. Experiments on 10 mathematics and coding benchmarks demonstrate consistent improvements, including over 13% gains on AIME-24 and AIME-25. Moreover, AdaRAS exhibits strong transferability across datasets and scalability to stronger models, outperforming post-training methods without additional training or sampling cost.
Rank4Gen: RAG-Preference-Aligned Document Set Selection and Ranking
Jan 16, 2026In the RAG paradigm, the information retrieval module provides context for generators by retrieving and ranking multiple documents to support the aggregation of evidence. However, existing ranking models are primarily optimized for query--document relevance, which often misaligns with generators' preferences for evidence selection and citation, limiting their impact on response quality. Moreover, most approaches do not account for preference differences across generators, resulting in unstable cross-generator performance. We propose \textbf{Rank4Gen}, a generator-aware ranker for RAG that targets the goal of \emph{Ranking for Generators}. Rank4Gen introduces two key preference modeling strategies: (1) \textbf{From Ranking Relevance to Response Quality}, which optimizes ranking with respect to downstream response quality rather than query--document relevance; and (2) \textbf{Generator-Specific Preference Modeling}, which conditions a single ranker on different generators to capture their distinct ranking preferences. To enable such modeling, we construct \textbf{PRISM}, a dataset built from multiple open-source corpora and diverse downstream generators. Experiments on five challenging and recent RAG benchmarks demonstrate that RRank4Gen achieves strong and competitive performance for complex evidence composition in RAG.
Coupled Variational Reinforcement Learning for Language Model General Reasoning
Dec 14, 2025While reinforcement learning have achieved impressive progress in language model reasoning, they are constrained by the requirement for verifiable rewards. Recent verifier-free RL methods address this limitation by utilizing the intrinsic probabilities of LLMs generating reference answers as reward signals. However, these approaches typically sample reasoning traces conditioned only on the question. This design decouples reasoning-trace sampling from answer information, leading to inefficient exploration and incoherence between traces and final answers. In this paper, we propose \textit{\b{Co}upled \b{V}ariational \b{R}einforcement \b{L}earning} (CoVRL), which bridges variational inference and reinforcement learning by coupling prior and posterior distributions through a hybrid sampling strategy. By constructing and optimizing a composite distribution that integrates these two distributions, CoVRL enables efficient exploration while preserving strong thought-answer coherence. Extensive experiments on mathematical and general reasoning benchmarks show that CoVRL improves performance by 12.4\% over the base model and achieves an additional 2.3\% improvement over strong state-of-the-art verifier-free RL baselines, providing a principled framework for enhancing the general reasoning capabilities of language models.
Memorizing is Not Enough: Deep Knowledge Injection Through Reasoning
Apr 01, 2025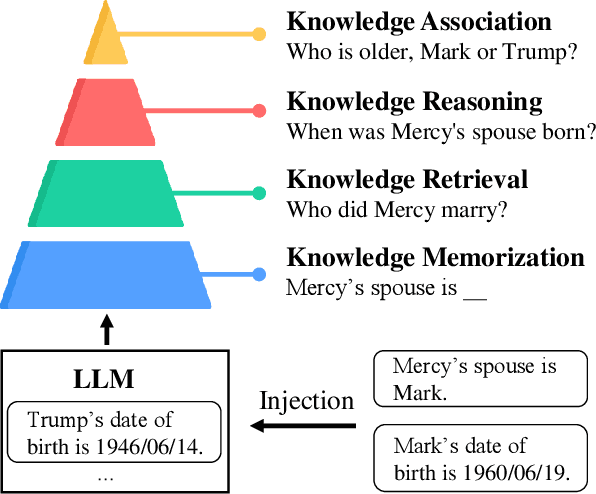
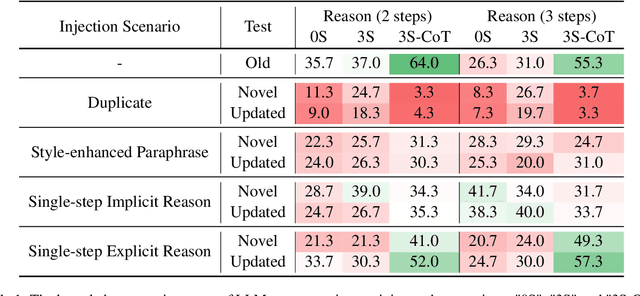
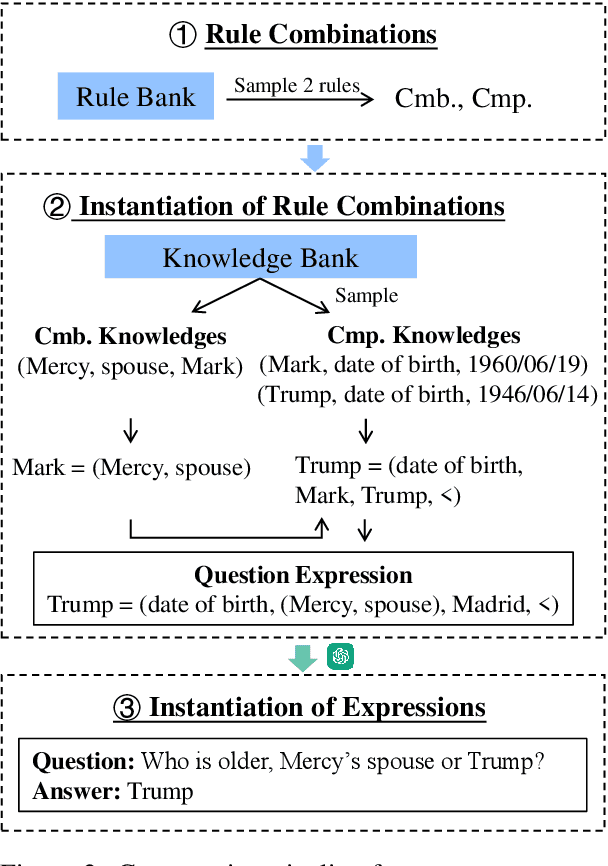
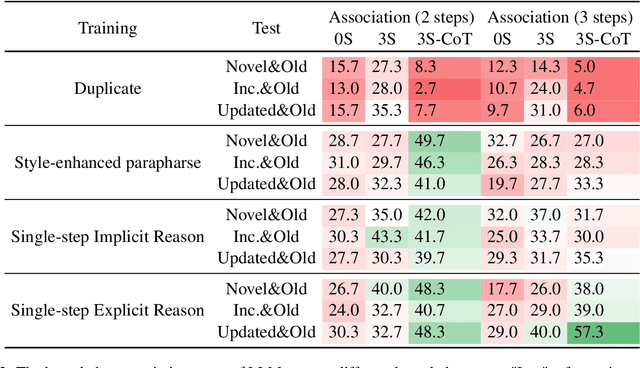
Although large language models (LLMs) excel in knowledge recall and reasoning, their static nature leads to outdated information as the real world evolves or when adapting to domain-specific knowledge, highlighting the need for effective knowledge injection. However, current research on knowledge injection remains superficial, mainly focusing on knowledge memorization and retrieval. This paper proposes a four-tier knowledge injection framework that systematically defines the levels of knowledge injection: memorization, retrieval, reasoning, and association. Based on this framework, we introduce DeepKnowledge, a synthetic experimental testbed designed for fine-grained evaluation of the depth of knowledge injection across three knowledge types (novel, incremental, and updated). We then explore various knowledge injection scenarios and evaluate the depth of knowledge injection for each scenario on the benchmark. Experimental results reveal key factors to reach each level of knowledge injection for LLMs and establish a mapping between the levels of knowledge injection and the corresponding suitable injection methods, aiming to provide a comprehensive approach for efficient knowledge injection across various levels.
Cheems: A Practical Guidance for Building and Evaluating Chinese Reward Models from Scratch
Feb 24, 2025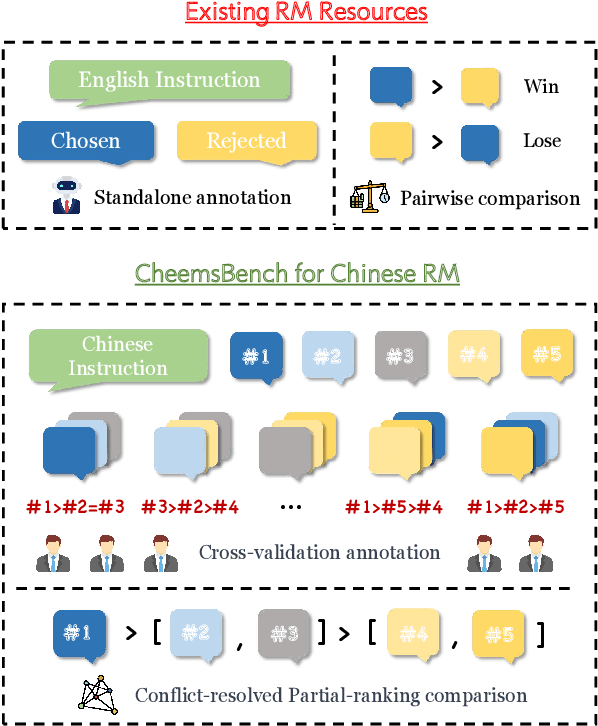
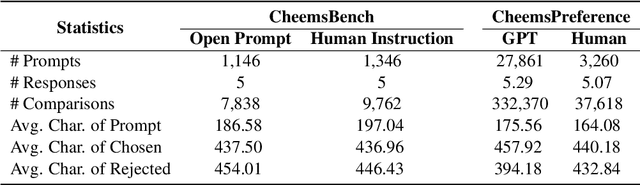
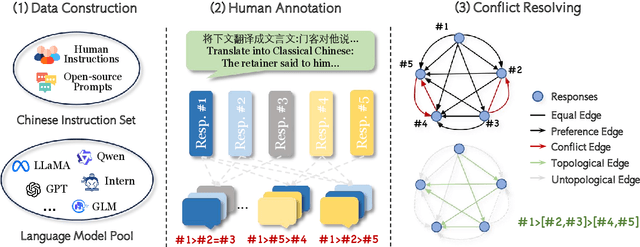
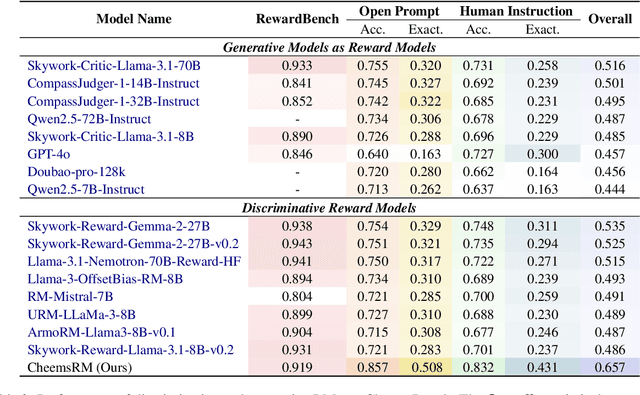
Reward models (RMs) are crucial for aligning large language models (LLMs) with human preferences. However, most RM research is centered on English and relies heavily on synthetic resources, which leads to limited and less reliable datasets and benchmarks for Chinese. To address this gap, we introduce CheemsBench, a fully human-annotated RM evaluation benchmark within Chinese contexts, and CheemsPreference, a large-scale and diverse preference dataset annotated through human-machine collaboration to support Chinese RM training. We systematically evaluate open-source discriminative and generative RMs on CheemsBench and observe significant limitations in their ability to capture human preferences in Chinese scenarios. Additionally, based on CheemsPreference, we construct an RM that achieves state-of-the-art performance on CheemsBench, demonstrating the necessity of human supervision in RM training. Our findings reveal that scaled AI-generated data struggles to fully capture human preferences, emphasizing the importance of high-quality human supervision in RM development.
SAISA: Towards Multimodal Large Language Models with Both Training and Inference Efficiency
Feb 04, 2025Multimodal Large Language Models (MLLMs) mainly fall into two architectures, each involving a trade-off between training and inference efficiency: embedding space alignment (e.g., LLaVA-1.5) is inefficient during inference, while cross-attention space alignment (e.g., Flamingo) is inefficient in training. In this paper, we compare these two architectures and identify the key factors for building efficient MLLMs. A primary difference between them lies in how attention is applied to visual tokens, particularly in their interactions with each other. To investigate whether attention among visual tokens is necessary, we propose a new self-attention mechanism, NAAViT (\textbf{N}o \textbf{A}ttention \textbf{A}mong \textbf{Vi}sual \textbf{T}okens), which eliminates this type of attention. Our pilot experiment on LLaVA-1.5 shows that attention among visual tokens is highly redundant. Based on these insights, we introduce SAISA (\textbf{S}elf-\textbf{A}ttention \textbf{I}nput \textbf{S}pace \textbf{A}lignment), a novel architecture that enhance both training and inference efficiency. SAISA directly aligns visual features with the input spaces of NAAViT self-attention blocks, reducing computational overhead in both self-attention blocks and feed-forward networks (FFNs). Using the same configuration as LLaVA-1.5, SAISA reduces inference FLOPs by 66\% and training budget by 26\%, while achieving superior performance in terms of accuracy. Comprehensive ablation studies further validate the effectiveness of SAISA across various LLMs and visual encoders. The code and model will be publicly available at https://github.com/icip-cas/SAISA.