 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNICA: A Unified Neural Framework for Controllable 3D Avatars
Apr 03, 2026Controllable 3D human avatars have found widespread applications in 3D games, the metaverse, and AR/VR scenarios. The conventional approach to creating such a 3D avatar requires a lengthy, intricate pipeline encompassing appearance modeling, motion planning, rigging, and physical simulation. In this paper, we introduce UNICA (UNIfied neural Controllable Avatar), a skeleton-free generative model that unifies all avatar control components into a single neural framework. Given keyboard inputs akin to video game controls, UNICA generates the next frame of a 3D avatar's geometry through an action-conditioned diffusion model operating on 2D position maps. A point transformer then maps the resulting geometry to 3D Gaussian Splatting for high-fidelity free-view rendering. Our approach naturally captures hair and loose clothing dynamics without manually designed physical simulation, and supports extra-long autoregressive generation. To the best of our knowledge, UNICA is the first model to unify the workflow of "motion planning, rigging, physical simulation, and rendering". Code is released at https://github.com/zjh21/UNICA.
Physics-Embedded Neural ODEs for Learning Antagonistic Pneumatic Artificial Muscle Dynamics
Feb 27, 2026Pneumatic artificial muscles (PAMs) enable compliant actuation for soft wearable, assistive, and interactive robots. When arranged antagonistically, PAMs can provide variable impedance through co-contraction but exhibit coupled, nonlinear, and hysteretic dynamics that challenge modeling and control. This paper presents a hybrid neural ordinary differential equation (Neural ODE) framework that embeds physical structure into a learned model of antagonistic PAM dynamics. The formulation combines parametric joint mechanics and pneumatic state dynamics with a neural network force component that captures antagonistic coupling and rate-dependent hysteresis. The forward model predicts joint motion and chamber pressures with a mean R$^2$ of 0.88 across 225 co-contraction conditions. An inverse formulation, derived from the learned dynamics, computes pressure commands offline for desired motion and stiffness profiles, tracked in closed loop during execution. Experimental validation demonstrates reliable stiffness control across 126-176 N/mm and consistent impedance behavior across operating velocities, in contrast to a static model, which shows degraded stiffness consistency at higher velocities.
Infi-MMR: Curriculum-based Unlocking Multimodal Reasoning via Phased Reinforcement Learning in Multimodal Small Language Models
May 29, 2025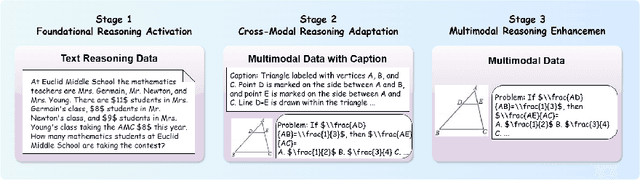
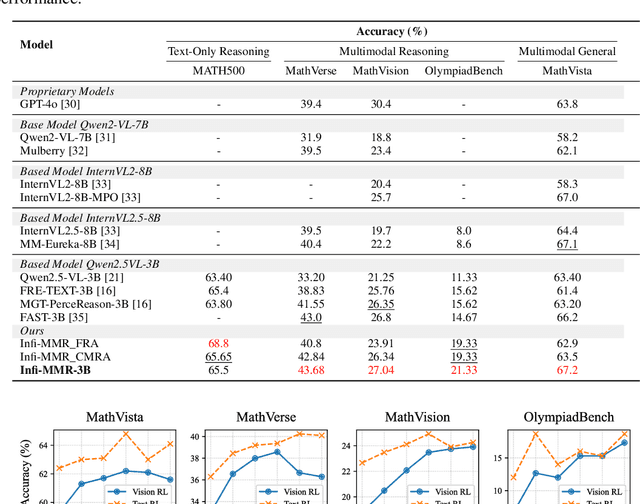
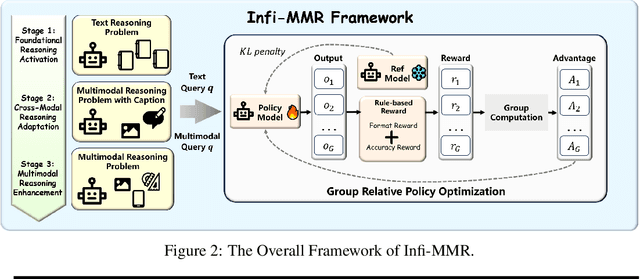
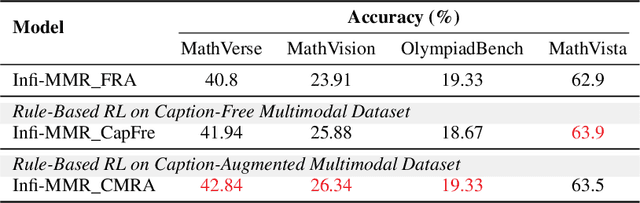
Recent advancements in large language models (LLMs) have demonstrated substantial progress in reasoning capabilities, such as DeepSeek-R1, which leverages rule-based reinforcement learning to enhance logical reasoning significantly. However, extending these achievements to multimodal large language models (MLLMs) presents critical challenges, which are frequently more pronounced for Multimodal Small Language Models (MSLMs) given their typically weaker foundational reasoning abilities: (1) the scarcity of high-quality multimodal reasoning datasets, (2) the degradation of reasoning capabilities due to the integration of visual processing, and (3) the risk that direct application of reinforcement learning may produce complex yet incorrect reasoning processes. To address these challenges, we design a novel framework Infi-MMR to systematically unlock the reasoning potential of MSLMs through a curriculum of three carefully structured phases and propose our multimodal reasoning model Infi-MMR-3B. The first phase, Foundational Reasoning Activation, leverages high-quality textual reasoning datasets to activate and strengthen the model's logical reasoning capabilities. The second phase, Cross-Modal Reasoning Adaptation, utilizes caption-augmented multimodal data to facilitate the progressive transfer of reasoning skills to multimodal contexts. The third phase, Multimodal Reasoning Enhancement, employs curated, caption-free multimodal data to mitigate linguistic biases and promote robust cross-modal reasoning. Infi-MMR-3B achieves both state-of-the-art multimodal math reasoning ability (43.68% on MathVerse testmini, 27.04% on MathVision test, and 21.33% on OlympiadBench) and general reasoning ability (67.2% on MathVista testmini).
DiffLM: Controllable Synthetic Data Generation via Diffusion Language Models
Nov 05, 2024



Recent advancements in large language models (LLMs) have significantly enhanced their knowledge and generative capabilities, leading to a surge of interest in leveraging LLMs for high-quality data synthesis. However, synthetic data generation via prompting LLMs remains challenging due to LLMs' limited understanding of target data distributions and the complexity of prompt engineering, especially for structured formatted data. To address these issues, we introduce DiffLM, a controllable data synthesis framework based on variational autoencoder (VAE), which further (1) leverages diffusion models to reserve more information of original distribution and format structure in the learned latent distribution and (2) decouples the learning of target distribution knowledge from the LLM's generative objectives via a plug-and-play latent feature injection module. As we observed significant discrepancies between the VAE's latent representations and the real data distribution, the latent diffusion module is introduced into our framework to learn a fully expressive latent distribution. Evaluations on seven real-world datasets with structured formatted data (i.e., Tabular, Code and Tool data) demonstrate that DiffLM generates high-quality data, with performance on downstream tasks surpassing that of real data by 2-7 percent in certain cases. The data and code will be publicly available upon completion of internal review.
AIPO: Improving Training Objective for Iterative Preference Optimization
Sep 13, 2024



Preference Optimization (PO), is gaining popularity as an alternative choice of Proximal Policy Optimization (PPO) for aligning Large Language Models (LLMs). Recent research on aligning LLMs iteratively with synthetic or partially synthetic data shows promising results in scaling up PO training for both academic settings and proprietary trained models such as Llama3. Despite its success, our study shows that the length exploitation issue present in PO is even more severe in Iterative Preference Optimization (IPO) due to the iterative nature of the process. In this work, we study iterative preference optimization with synthetic data. We share the findings and analysis along the way of building the iterative preference optimization pipeline. More specifically, we discuss the length exploitation issue during iterative preference optimization and propose our training objective for iterative preference optimization, namely Agreement-aware Iterative Preference Optimization (AIPO). To demonstrate the effectiveness of our method, we conduct comprehensive experiments and achieve state-of-the-art performance on MT-Bench, AlpacaEval 2.0, and Arena-Hard. Our implementation and model checkpoints will be made available at https://github.com/bytedance/AIPO.
Beyond Raw Videos: Understanding Edited Videos with Large Multimodal Model
Jun 15, 2024



The emerging video LMMs (Large Multimodal Models) have achieved significant improvements on generic video understanding in the form of VQA (Visual Question Answering), where the raw videos are captured by cameras. However, a large portion of videos in real-world applications are edited videos, \textit{e.g.}, users usually cut and add effects/modifications to the raw video before publishing it on social media platforms. The edited videos usually have high view counts but they are not covered in existing benchmarks of video LMMs, \textit{i.e.}, ActivityNet-QA, or VideoChatGPT benchmark. In this paper, we leverage the edited videos on a popular short video platform, \textit{i.e.}, TikTok, and build a video VQA benchmark (named EditVid-QA) covering four typical editing categories, i.e., effect, funny, meme, and game. Funny and meme videos benchmark nuanced understanding and high-level reasoning, while effect and game evaluate the understanding capability of artificial design. Most of the open-source video LMMs perform poorly on the EditVid-QA benchmark, indicating a huge domain gap between edited short videos on social media and regular raw videos. To improve the generalization ability of LMMs, we collect a training set for the proposed benchmark based on both Panda-70M/WebVid raw videos and small-scale TikTok/CapCut edited videos, which boosts the performance on the proposed EditVid-QA benchmark, indicating the effectiveness of high-quality training data. We also identified a serious issue in the existing evaluation protocol using the GPT-3.5 judge, namely a "sorry" attack, where a sorry-style naive answer can achieve an extremely high rating from the GPT judge, e.g., over 4.3 for correctness score on VideoChatGPT evaluation protocol. To avoid the "sorry" attacks, we evaluate results with GPT-4 judge and keyword filtering. The datasets will be released for academic purposes only.
CuMo: Scaling Multimodal LLM with Co-Upcycled Mixture-of-Experts
May 09, 2024
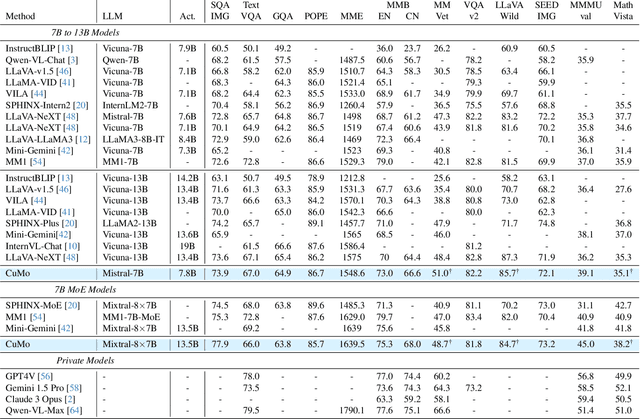
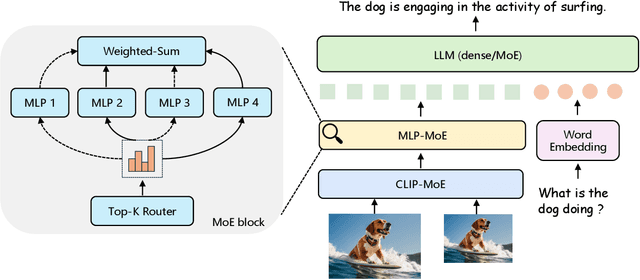
Recent advancements in Multimodal Large Language Models (LLMs) have focused primarily on scaling by increasing text-image pair data and enhancing LLMs to improve performance on multimodal tasks. However, these scaling approaches are computationally expensive and overlook the significance of improving model capabilities from the vision side. Inspired by the successful applications of Mixture-of-Experts (MoE) in LLMs, which improves model scalability during training while keeping inference costs similar to those of smaller models, we propose CuMo. CuMo incorporates Co-upcycled Top-K sparsely-gated Mixture-of-experts blocks into both the vision encoder and the MLP connector, thereby enhancing the multimodal LLMs with minimal additional activated parameters during inference. CuMo first pre-trains the MLP blocks and then initializes each expert in the MoE block from the pre-trained MLP block during the visual instruction tuning stage. Auxiliary losses are used to ensure a balanced loading of experts. CuMo outperforms state-of-the-art multimodal LLMs across various VQA and visual-instruction-following benchmarks using models within each model size group, all while training exclusively on open-sourced datasets. The code and model weights for CuMo are open-sourced at https://github.com/SHI-Labs/CuMo.
QuadraNet V2: Efficient and Sustainable Training of High-Order Neural Networks with Quadratic Adaptation
May 06, 2024


Machine learning is evolving towards high-order models that necessitate pre-training on extensive datasets, a process associated with significant overheads. Traditional models, despite having pre-trained weights, are becoming obsolete due to architectural differences that obstruct the effective transfer and initialization of these weights. To address these challenges, we introduce a novel framework, QuadraNet V2, which leverages quadratic neural networks to create efficient and sustainable high-order learning models. Our method initializes the primary term of the quadratic neuron using a standard neural network, while the quadratic term is employed to adaptively enhance the learning of data non-linearity or shifts. This integration of pre-trained primary terms with quadratic terms, which possess advanced modeling capabilities, significantly augments the information characterization capacity of the high-order network. By utilizing existing pre-trained weights, QuadraNet V2 reduces the required GPU hours for training by 90\% to 98.4\% compared to training from scratch, demonstrating both efficiency and effectiveness.
Steam Recommendation System
May 03, 2023


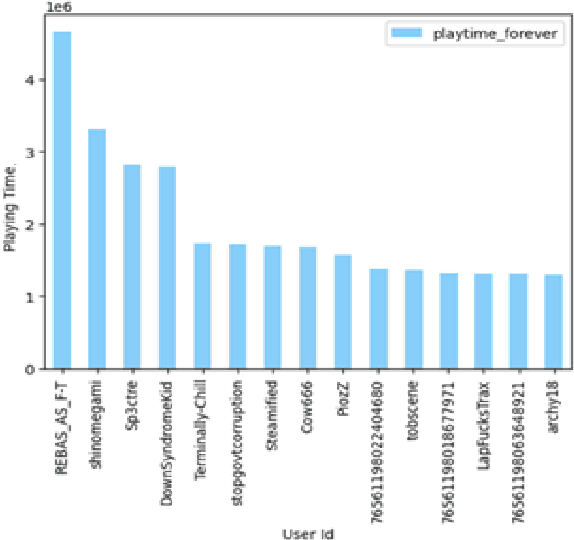
We aim to leverage the interactions between users and items in the Steam community to build a game recommendation system that makes personalized suggestions to players in order to boost Steam's revenue as well as improve the users' gaming experience. The whole project is built on Apache Spark and deals with Big Data. The final output of the project is a recommendation system that gives a list of the top 5 items that the users will possibly like.6
Secure UAV-to-Ground MIMO Communications: Joint Transceiver and Location Optimization
Jul 10, 2022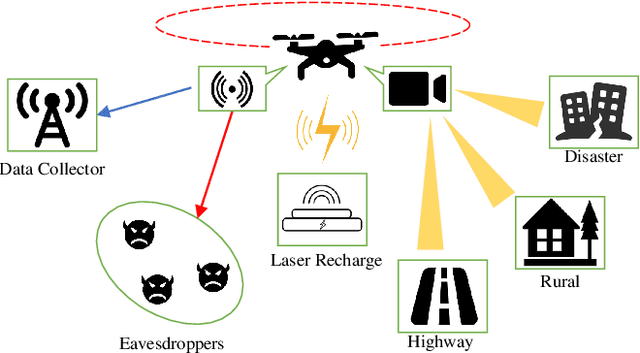
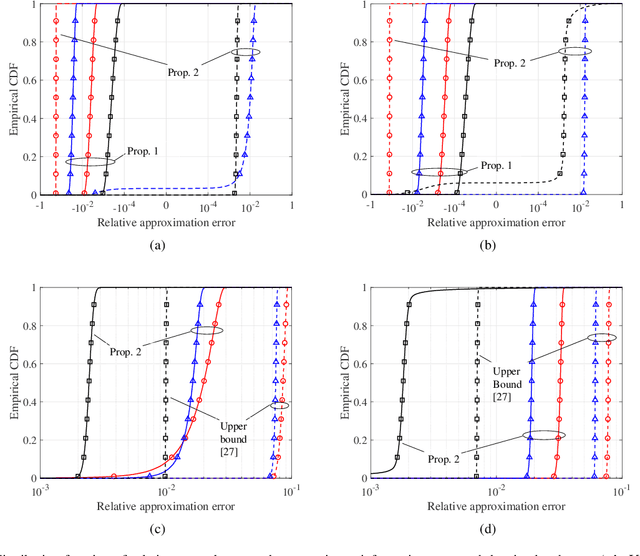
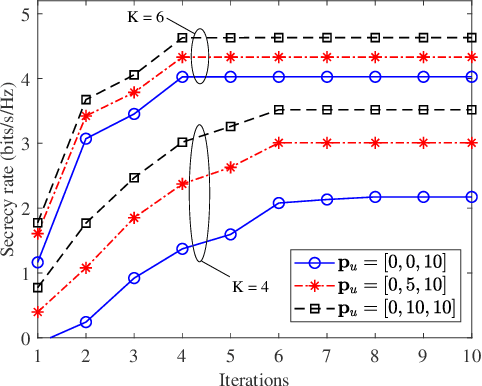
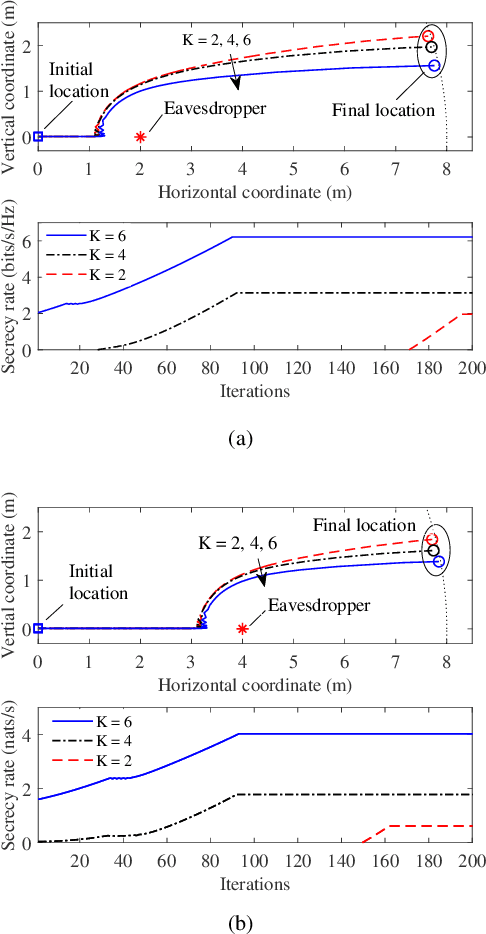
Unmanned aerial vehicles (UAVs) are foreseen to constitute promising airborne communication devices as a benefit of their superior channel quality. But UAV-to-ground (U2G) communications are vulnerable to eavesdropping. Hence, we conceive a sophisticated physical layer security solution for improving the secrecy rate of multi-antenna aided U2G systems. Explicitly, the secrecy rate of the U2G MIMO wiretap channels is derived by using random matrix theory. The resultant explicit expression is then applied in the joint optimization of the MIMO transceiver and the UAV location relying on an alternating optimization technique. Our numerical results show that the joint transceiver and location optimization conceived facilitates secure communications even in the challenging scenario, where the legitimate channel of confidential information is inferior to the eavesdropping channel.