 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Context Transformer for Generic Event Boundary Detection
Paper and Code
Jun 07, 2022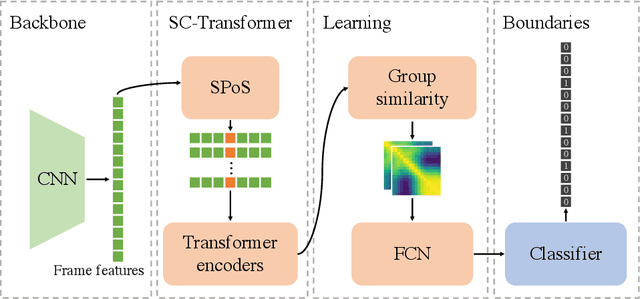
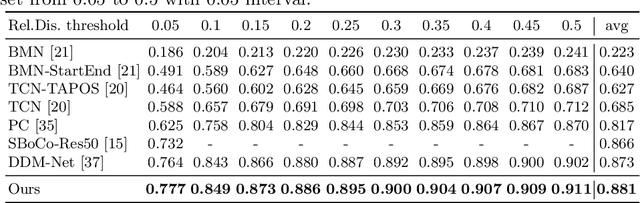
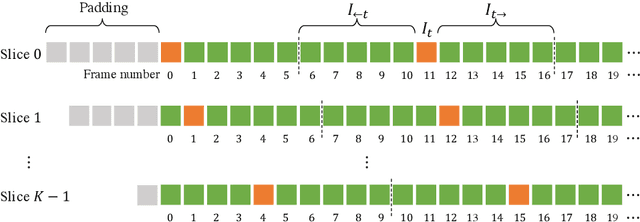
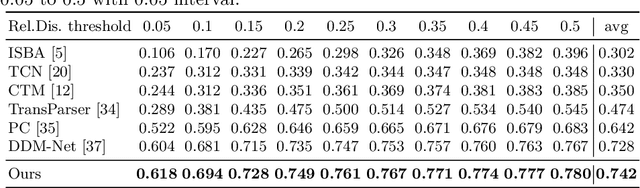
Generic Event Boundary Detection (GEBD) aims to detect moments where humans naturally perceive as event boundaries. In this paper, we present Structured Context Transformer (or SC-Transformer) to solve the GEBD task, which can be trained in an end-to-end fashion. Specifically, we use the backbone convolutional neural network (CNN) to extract the features of each video frame. To capture temporal context information of each frame, we design the structure context transformer (SC-Transformer) by re-partitioning input frame sequence. Note that, the overall computation complexity of SC-Transformer is linear to the video length. After that, the group similarities are computed to capture the differences between frames. Then, a lightweight fully convolutional network is used to determine the event boundaries based on the grouped similarity maps. To remedy the ambiguities of boundary annotations, the Gaussian kernel is adopted to preprocess the ground-truth event boundaries to further boost the accuracy. Extensive experiments conducted on the challenging Kinetics-GEBD and TAPOS datasets demonstrate the effectiveness of the proposed method compared to the state-of-the-art methods.