 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiMed-Foundation: Pioneering Advanced Multimodal Medical Models with Compute-Efficient Pre-Training and Multi-Stage Fine-Tuning
Sep 26, 2025



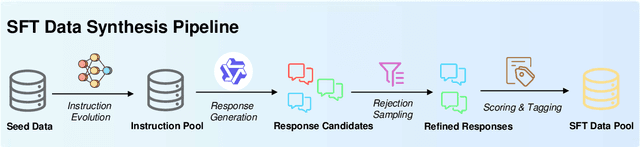
Multimodal large language models (MLLMs) have shown remarkable potential in various domains, yet their application in the medical field is hindered by several challenges. General-purpose MLLMs often lack the specialized knowledge required for medical tasks, leading to uncertain or hallucinatory responses. Knowledge distillation from advanced models struggles to capture domain-specific expertise in radiology and pharmacology. Additionally, the computational cost of continual pretraining with large-scale medical data poses significant efficiency challenges. To address these issues, we propose InfiMed-Foundation-1.7B and InfiMed-Foundation-4B, two medical-specific MLLMs designed to deliver state-of-the-art performance in medical applications. We combined high-quality general-purpose and medical multimodal data and proposed a novel five-dimensional quality assessment framework to curate high-quality multimodal medical datasets. We employ low-to-high image resolution and multimodal sequence packing to enhance training efficiency, enabling the integration of extensive medical data. Furthermore, a three-stage supervised fine-tuning process ensures effective knowledge extraction for complex medical tasks. Evaluated on the MedEvalKit framework, InfiMed-Foundation-1.7B outperforms Qwen2.5VL-3B, while InfiMed-Foundation-4B surpasses HuatuoGPT-V-7B and MedGemma-27B-IT, demonstrating superior performance in medical visual question answering and diagnostic tasks. By addressing key challenges in data quality, training efficiency, and domain-specific knowledge extraction, our work paves the way for more reliable and effective AI-driven solutions in healthcare. InfiMed-Foundation-4B model is available at \href{https://huggingface.co/InfiX-ai/InfiMed-Foundation-4B}{InfiMed-Foundation-4B}.
Infi-MMR: Curriculum-based Unlocking Multimodal Reasoning via Phased Reinforcement Learning in Multimodal Small Language Models
May 29, 2025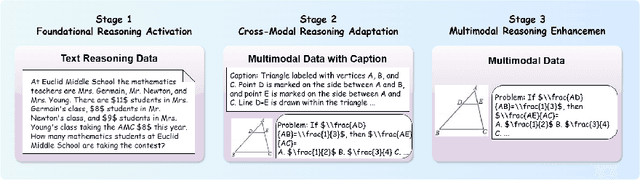
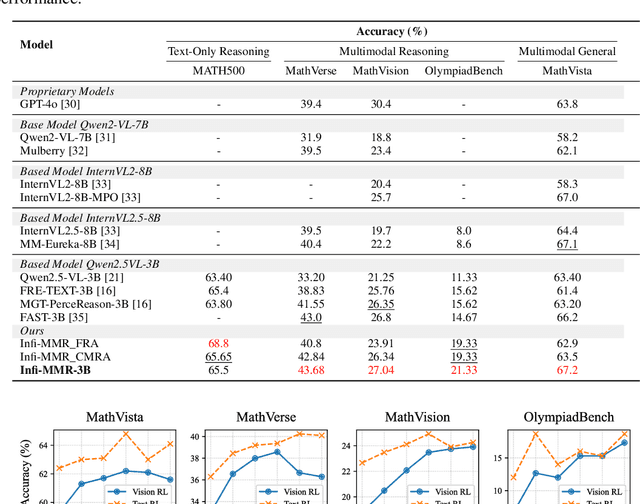
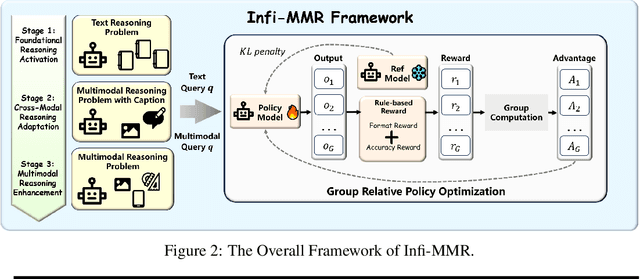
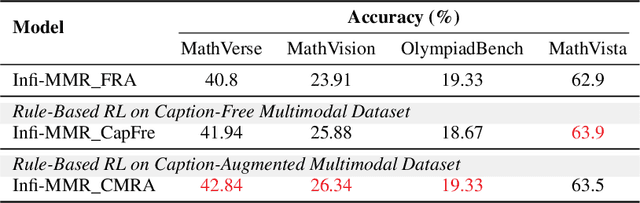
Recent advancements in large language models (LLMs) have demonstrated substantial progress in reasoning capabilities, such as DeepSeek-R1, which leverages rule-based reinforcement learning to enhance logical reasoning significantly. However, extending these achievements to multimodal large language models (MLLMs) presents critical challenges, which are frequently more pronounced for Multimodal Small Language Models (MSLMs) given their typically weaker foundational reasoning abilities: (1) the scarcity of high-quality multimodal reasoning datasets, (2) the degradation of reasoning capabilities due to the integration of visual processing, and (3) the risk that direct application of reinforcement learning may produce complex yet incorrect reasoning processes. To address these challenges, we design a novel framework Infi-MMR to systematically unlock the reasoning potential of MSLMs through a curriculum of three carefully structured phases and propose our multimodal reasoning model Infi-MMR-3B. The first phase, Foundational Reasoning Activation, leverages high-quality textual reasoning datasets to activate and strengthen the model's logical reasoning capabilities. The second phase, Cross-Modal Reasoning Adaptation, utilizes caption-augmented multimodal data to facilitate the progressive transfer of reasoning skills to multimodal contexts. The third phase, Multimodal Reasoning Enhancement, employs curated, caption-free multimodal data to mitigate linguistic biases and promote robust cross-modal reasoning. Infi-MMR-3B achieves both state-of-the-art multimodal math reasoning ability (43.68% on MathVerse testmini, 27.04% on MathVision test, and 21.33% on OlympiadBench) and general reasoning ability (67.2% on MathVista testmini).
InfiR : Crafting Effective Small Language Models and Multimodal Small Language Models in Reasoning
Feb 17, 2025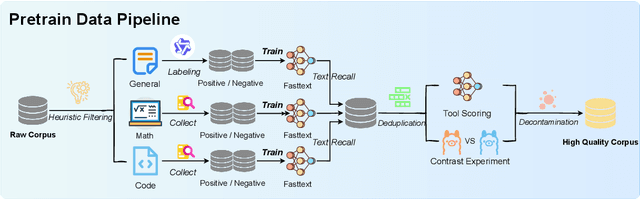


Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) have made significant advancements in reasoning capabilities. However, they still face challenges such as high computational demands and privacy concerns. This paper focuses on developing efficient Small Language Models (SLMs) and Multimodal Small Language Models (MSLMs) that retain competitive reasoning abilities. We introduce a novel training pipeline that enhances reasoning capabilities and facilitates deployment on edge devices, achieving state-of-the-art performance while minimizing development costs. \InfR~ aims to advance AI systems by improving reasoning, reducing adoption barriers, and addressing privacy concerns through smaller model sizes. Resources are available at https://github. com/Reallm-Labs/InfiR.
UADSN: Uncertainty-Aware Dual-Stream Network for Facial Nerve Segmentation
Jun 29, 2024



Facial nerve segmentation is crucial for preoperative path planning in cochlear implantation surgery. Recently, researchers have proposed some segmentation methods, such as atlas-based and deep learning-based methods. However, since the facial nerve is a tubular organ with a diameter of only 1.0-1.5mm, it is challenging to locate and segment the facial nerve in CT scans. In this work, we propose an uncertainty-aware dualstream network (UADSN). UADSN consists of a 2D segmentation stream and a 3D segmentation stream. Predictions from two streams are used to identify uncertain regions, and a consistency loss is employed to supervise the segmentation of these regions. In addition, we introduce channel squeeze & spatial excitation modules into the skip connections of U-shaped networks to extract meaningful spatial information. In order to consider topologypreservation, a clDice loss is introduced into the supervised loss function. Experimental results on the facial nerve dataset demonstrate the effectiveness of UADSN and our submodules.
AstMatch: Adversarial Self-training Consistency Framework for Semi-Supervised Medical Image Segmentation
Jun 28, 2024



Semi-supervised learning (SSL) has shown considerable potential in medical image segmentation, primarily leveraging consistency regularization and pseudo-labeling. However, many SSL approaches only pay attention to low-level consistency and overlook the significance of pseudo-label reliability. Therefore, in this work, we propose an adversarial self-training consistency framework (AstMatch). Firstly, we design an adversarial consistency regularization (ACR) approach to enhance knowledge transfer and strengthen prediction consistency under varying perturbation intensities. Second, we apply a feature matching loss for adversarial training to incorporate high-level consistency regularization. Additionally, we present the pyramid channel attention (PCA) and efficient channel and spatial attention (ECSA) modules to improve the discriminator's performance. Finally, we propose an adaptive self-training (AST) approach to ensure the pseudo-labels' quality. The proposed AstMatch has been extensively evaluated with cutting-edge SSL methods on three public-available datasets. The experimental results under different labeled ratios indicate that AstMatch outperforms other existing methods, achieving new state-of-the-art performance. Our code will be available at https://github.com/GuanghaoZhu663/AstMatch.
SKD-TSTSAN: Three-Stream Temporal-Shift Attention Network Based on Self-Knowledge Distillation for Micro-Expression Recognition
Jun 25, 2024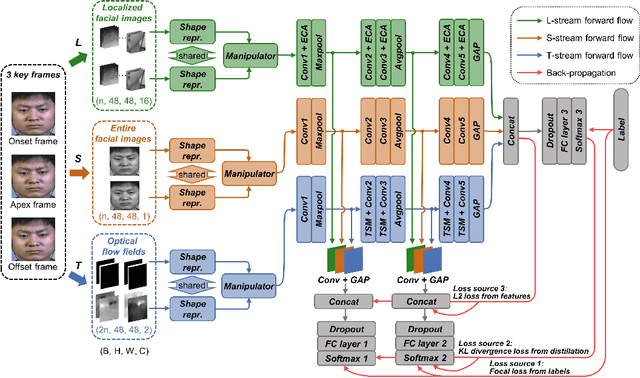
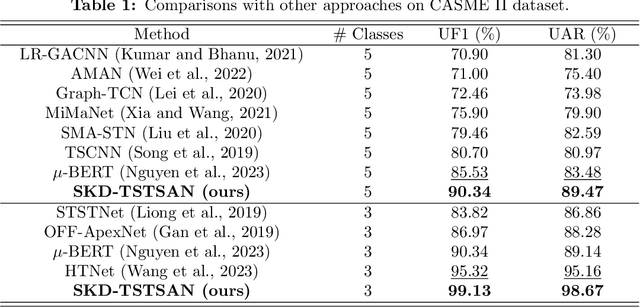
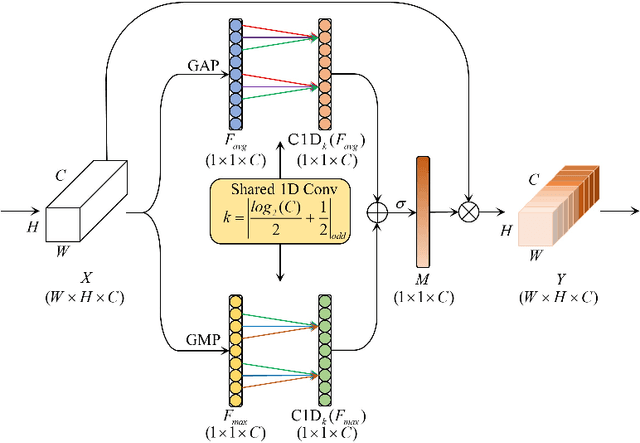
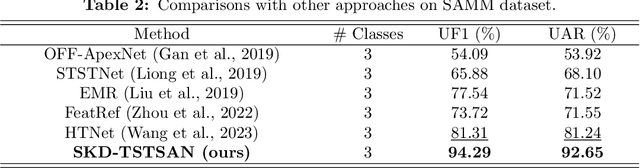
Micro-expressions (MEs) are subtle facial movements that occur spontaneously when people try to conceal the real emotions. Micro-expression recognition (MER) is crucial in many fields, including criminal analysis and psychotherapy. However, MER is challenging since MEs have low intensity and ME datasets are small in size. To this end, a three-stream temporal-shift attention network based on self-knowledge distillation (SKD-TSTSAN) is proposed in this paper. Firstly, to address the low intensity of ME muscle movements, we utilize learning-based motion magnification modules to enhance the intensity of ME muscle movements. Secondly, we employ efficient channel attention (ECA) modules in the local-spatial stream to make the network focus on facial regions that are highly relevant to MEs. In addition, temporal shift modules (TSMs) are used in the dynamic-temporal stream, which enables temporal modeling with no additional parameters by mixing ME motion information from two different temporal domains. Furthermore, we introduce self-knowledge distillation (SKD) into the MER task by introducing auxiliary classifiers and using the deepest section of the network for supervision, encouraging all blocks to fully explore the features of the training set. Finally, extensive experiments are conducted on four ME datasets: CASME II, SAMM, MMEW, and CAS(ME)3. The experimental results demonstrate that our SKD-TSTSAN outperforms other existing methods and achieves new state-of-the-art performance. Our code will be available at https://github.com/GuanghaoZhu663/SKD-TSTSAN.