 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow and Why: Taming Flow Matching for Unsupervised Anomaly Detection and Localization
Aug 07, 2025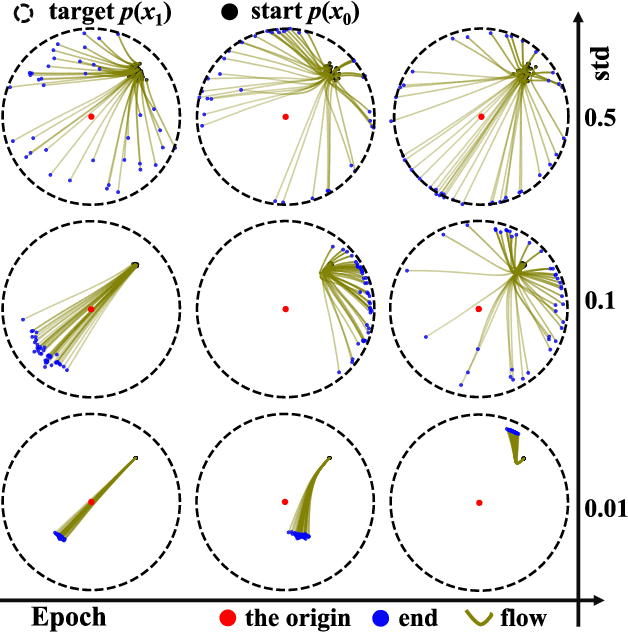
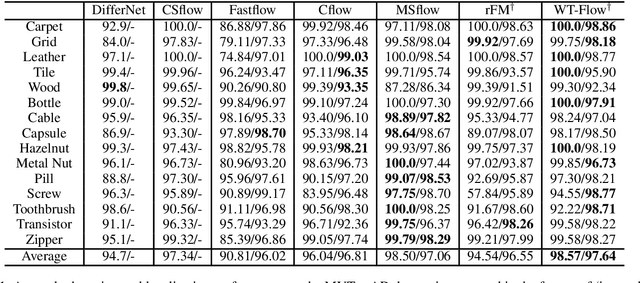
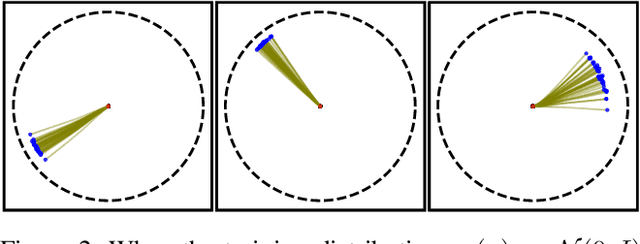
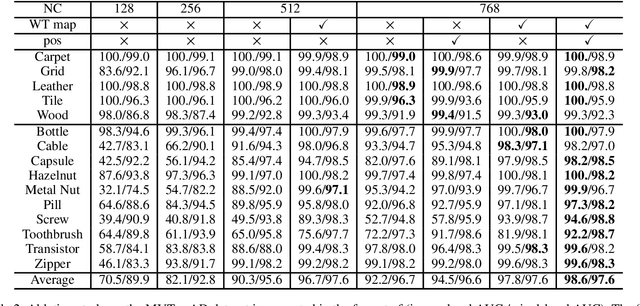
We propose a new paradigm for unsupervised anomaly detection and localization using Flow Matching (FM), which fundamentally addresses the model expressivity limitations of conventional flow-based methods. To this end, we formalize the concept of time-reversed Flow Matching (rFM) as a vector field regression along a predefined probability path to transform unknown data distributions into standard Gaussian. We bring two core observations that reshape our understanding of FM. First, we rigorously prove that FM with linear interpolation probability paths is inherently non-invertible. Second, our analysis reveals that employing reversed Gaussian probability paths in high-dimensional spaces can lead to trivial vector fields. This issue arises due to the manifold-related constraints. Building on the second observation, we propose Worst Transport (WT) displacement interpolation to reconstruct a non-probabilistic evolution path. The proposed WT-Flow enhances dynamical control over sample trajectories, constructing ''degenerate potential wells'' for anomaly-free samples while allowing anomalous samples to escape. This novel unsupervised paradigm offers a theoretically grounded separation mechanism for anomalous samples. Notably, FM provides a computationally tractable framework that scales to complex data. We present the first successful application of FM for the unsupervised anomaly detection task, achieving state-of-the-art performance at a single scale on the MVTec dataset. The reproducible code for training will be released upon camera-ready submission.
UNSCT-HRNet: Modeling Anatomical Uncertainty for Landmark Detection in Total Hip Arthroplasty
Nov 13, 2024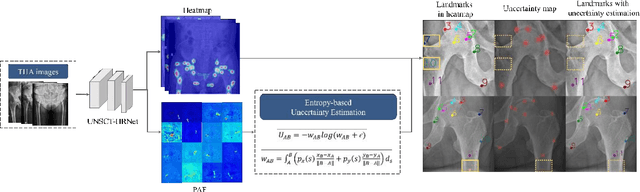

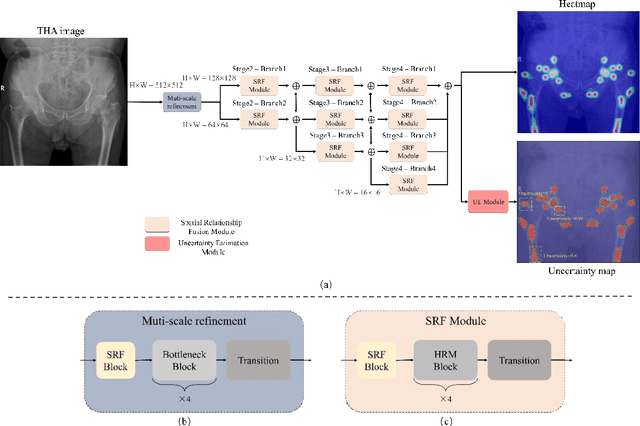

Total hip arthroplasty (THA) relies on accurate landmark detection from radiographic images, but unstructured data caused by irregular patient postures or occluded anatomical markers pose significant challenges for existing methods. To address this, we propose UNSCT-HRNet (Unstructured CT - High-Resolution Net), a deep learning-based framework that integrates a Spatial Relationship Fusion (SRF) module and an Uncertainty Estimation (UE) module. The SRF module, utilizing coordinate convolution and polarized attention, enhances the model's ability to capture complex spatial relationships. Meanwhile, the UE module which based on entropy ensures predictions are anatomically relevant. For unstructured data, the proposed method can predict landmarks without relying on the fixed number of points, which shows higher accuracy and better robustness comparing with the existing methods. Our UNSCT-HRNet demonstrates over a 60% improvement across multiple metrics in unstructured data. The experimental results also reveal that our approach maintains good performance on the structured dataset. Overall, the proposed UNSCT-HRNet has the potential to be used as a new reliable, automated solution for THA surgical planning and postoperative monitoring.
UADSN: Uncertainty-Aware Dual-Stream Network for Facial Nerve Segmentation
Jun 29, 2024



Facial nerve segmentation is crucial for preoperative path planning in cochlear implantation surgery. Recently, researchers have proposed some segmentation methods, such as atlas-based and deep learning-based methods. However, since the facial nerve is a tubular organ with a diameter of only 1.0-1.5mm, it is challenging to locate and segment the facial nerve in CT scans. In this work, we propose an uncertainty-aware dualstream network (UADSN). UADSN consists of a 2D segmentation stream and a 3D segmentation stream. Predictions from two streams are used to identify uncertain regions, and a consistency loss is employed to supervise the segmentation of these regions. In addition, we introduce channel squeeze & spatial excitation modules into the skip connections of U-shaped networks to extract meaningful spatial information. In order to consider topologypreservation, a clDice loss is introduced into the supervised loss function. Experimental results on the facial nerve dataset demonstrate the effectiveness of UADSN and our submodules.
AstMatch: Adversarial Self-training Consistency Framework for Semi-Supervised Medical Image Segmentation
Jun 28, 2024



Semi-supervised learning (SSL) has shown considerable potential in medical image segmentation, primarily leveraging consistency regularization and pseudo-labeling. However, many SSL approaches only pay attention to low-level consistency and overlook the significance of pseudo-label reliability. Therefore, in this work, we propose an adversarial self-training consistency framework (AstMatch). Firstly, we design an adversarial consistency regularization (ACR) approach to enhance knowledge transfer and strengthen prediction consistency under varying perturbation intensities. Second, we apply a feature matching loss for adversarial training to incorporate high-level consistency regularization. Additionally, we present the pyramid channel attention (PCA) and efficient channel and spatial attention (ECSA) modules to improve the discriminator's performance. Finally, we propose an adaptive self-training (AST) approach to ensure the pseudo-labels' quality. The proposed AstMatch has been extensively evaluated with cutting-edge SSL methods on three public-available datasets. The experimental results under different labeled ratios indicate that AstMatch outperforms other existing methods, achieving new state-of-the-art performance. Our code will be available at https://github.com/GuanghaoZhu663/AstMatch.
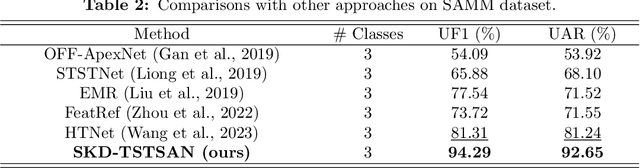
SKD-TSTSAN: Three-Stream Temporal-Shift Attention Network Based on Self-Knowledge Distillation for Micro-Expression Recognition
Jun 25, 2024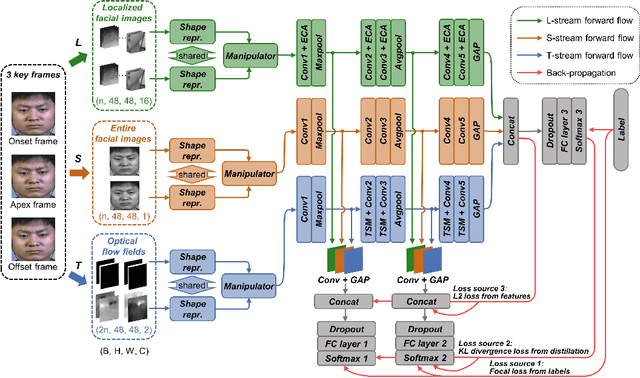
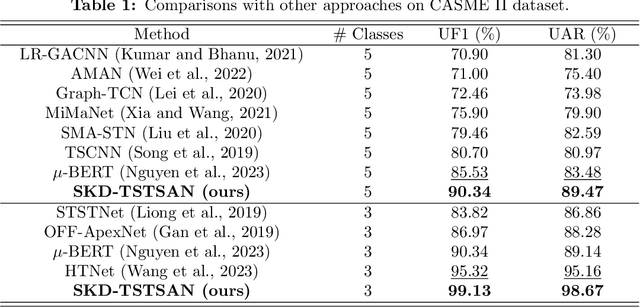
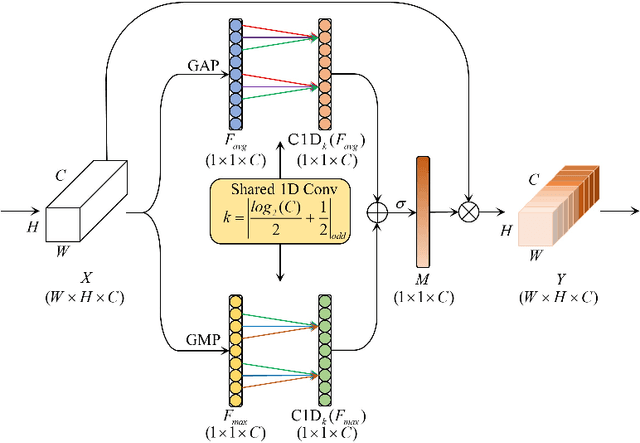
Micro-expressions (MEs) are subtle facial movements that occur spontaneously when people try to conceal the real emotions. Micro-expression recognition (MER) is crucial in many fields, including criminal analysis and psychotherapy. However, MER is challenging since MEs have low intensity and ME datasets are small in size. To this end, a three-stream temporal-shift attention network based on self-knowledge distillation (SKD-TSTSAN) is proposed in this paper. Firstly, to address the low intensity of ME muscle movements, we utilize learning-based motion magnification modules to enhance the intensity of ME muscle movements. Secondly, we employ efficient channel attention (ECA) modules in the local-spatial stream to make the network focus on facial regions that are highly relevant to MEs. In addition, temporal shift modules (TSMs) are used in the dynamic-temporal stream, which enables temporal modeling with no additional parameters by mixing ME motion information from two different temporal domains. Furthermore, we introduce self-knowledge distillation (SKD) into the MER task by introducing auxiliary classifiers and using the deepest section of the network for supervision, encouraging all blocks to fully explore the features of the training set. Finally, extensive experiments are conducted on four ME datasets: CASME II, SAMM, MMEW, and CAS(ME)3. The experimental results demonstrate that our SKD-TSTSAN outperforms other existing methods and achieves new state-of-the-art performance. Our code will be available at https://github.com/GuanghaoZhu663/SKD-TSTSAN.
Machine-Learning-based Colorectal Tissue Classification via Acoustic Resolution Photoacoustic Microscopy
Jul 17, 2023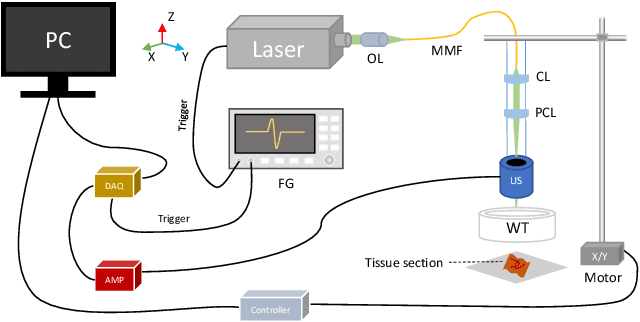
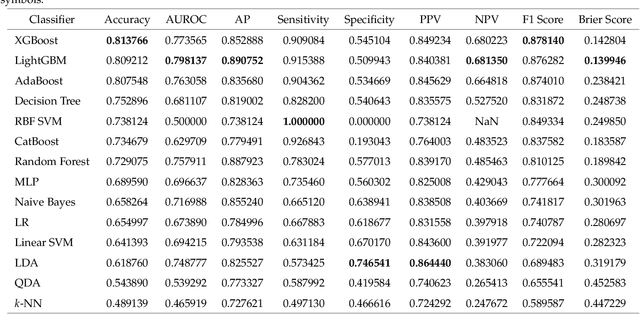
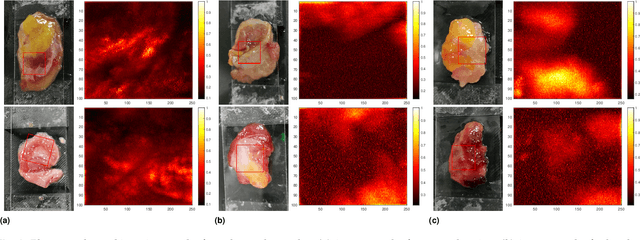
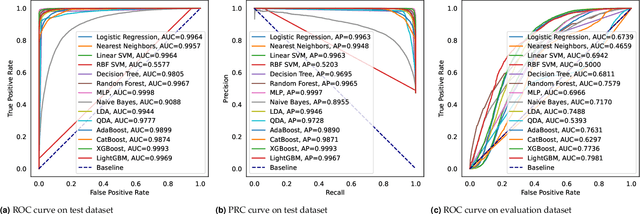
Colorectal cancer is a deadly disease that has become increasingly prevalent in recent years. Early detection is crucial for saving lives, but traditional diagnostic methods such as colonoscopy and biopsy have limitations. Colonoscopy cannot provide detailed information within the tissues affected by cancer, while biopsy involves tissue removal, which can be painful and invasive. In order to improve diagnostic efficiency and reduce patient suffering, we studied machine-learningbased approach for colorectal tissue classification that uses acoustic resolution photoacoustic microscopy (ARPAM). With this tool, we were able to classify benign and malignant tissue using multiple machine learning methods. Our results were analyzed both quantitatively and qualitatively to evaluate the effectiveness of our approach.