 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoe: Towards Efficient and Low-Cost MoE Inference in Serverless Computing
Dec 21, 2025Mixture-of-Experts (MoE) has become a dominant architecture in large language models (LLMs) due to its ability to scale model capacity via sparse expert activation. Meanwhile, serverless computing, with its elasticity and pay-per-use billing, is well-suited for deploying MoEs with bursty workloads. However, the large number of experts in MoE models incurs high inference costs due to memory-intensive parameter caching. These costs are difficult to mitigate via simple model partitioning due to input-dependent expert activation. To address these issues, we propose Remoe, a heterogeneous MoE inference system tailored for serverless computing. Remoe assigns non-expert modules to GPUs and expert modules to CPUs, and further offloads infrequently activated experts to separate serverless functions to reduce memory overhead and enable parallel execution. We incorporate three key techniques: (1) a Similar Prompts Searching (SPS) algorithm to predict expert activation patterns based on semantic similarity of inputs; (2) a Main Model Pre-allocation (MMP) algorithm to ensure service-level objectives (SLOs) via worst-case memory estimation; and (3) a joint memory and replica optimization framework leveraging Lagrangian duality and the Longest Processing Time (LPT) algorithm. We implement Remoe on Kubernetes and evaluate it across multiple LLM benchmarks. Experimental results show that Remoe reduces inference cost by up to 57% and cold start latency by 47% compared to state-of-the-art baselines.
Ascend HiFloat8 Format for Deep Learning
Sep 26, 2024



This preliminary white paper proposes a novel 8-bit floating-point data format HiFloat8 (abbreviated as HiF8) for deep learning. HiF8 features tapered precision. For normal value encoding, it provides 7 exponent values with 3-bit mantissa, 8 exponent values with 2-bit mantissa, and 16 exponent values with 1-bit mantissa. For denormal value encoding, it extends the dynamic range by 7 extra powers of 2, from 31 to 38 binades (notice that FP16 covers 40 binades). Meanwhile, HiF8 encodes all the special values except that positive zero and negative zero are represented by only one bit-pattern. Thanks to the better balance between precision and dynamic range, HiF8 can be simultaneously used in both forward and backward passes of AI training. In this paper, we will describe the definition and rounding methods of HiF8, as well as the tentative training and inference solutions. To demonstrate the efficacy of HiF8, massive simulation results on various neural networks, including traditional neural networks and large language models (LLMs), will also be presented.
SKD-TSTSAN: Three-Stream Temporal-Shift Attention Network Based on Self-Knowledge Distillation for Micro-Expression Recognition
Jun 25, 2024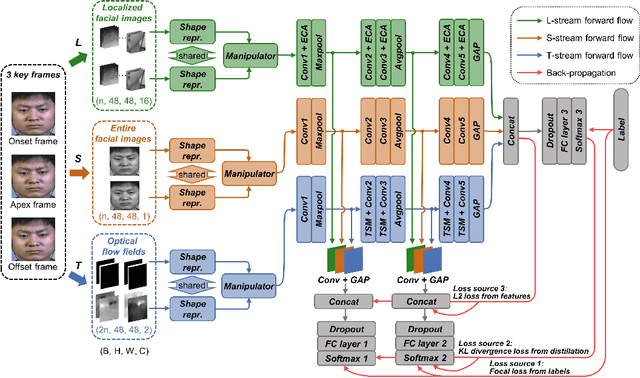
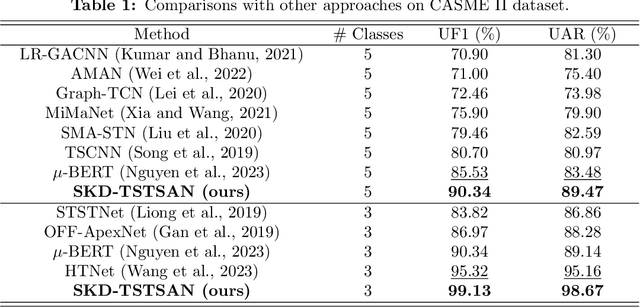
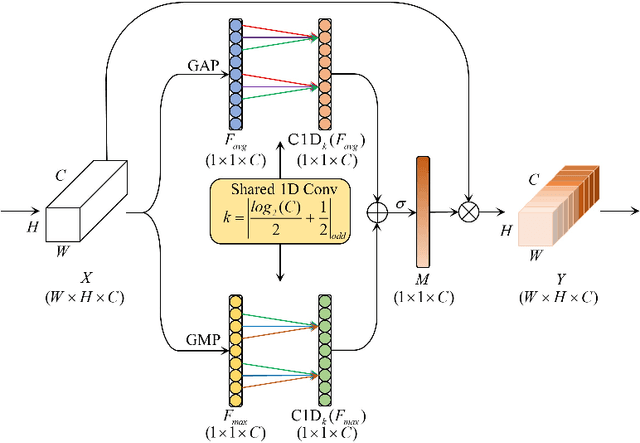
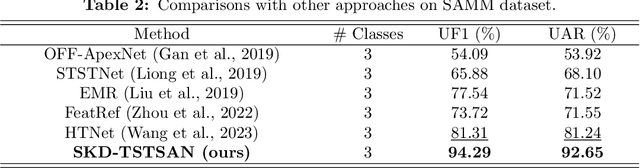
Micro-expressions (MEs) are subtle facial movements that occur spontaneously when people try to conceal the real emotions. Micro-expression recognition (MER) is crucial in many fields, including criminal analysis and psychotherapy. However, MER is challenging since MEs have low intensity and ME datasets are small in size. To this end, a three-stream temporal-shift attention network based on self-knowledge distillation (SKD-TSTSAN) is proposed in this paper. Firstly, to address the low intensity of ME muscle movements, we utilize learning-based motion magnification modules to enhance the intensity of ME muscle movements. Secondly, we employ efficient channel attention (ECA) modules in the local-spatial stream to make the network focus on facial regions that are highly relevant to MEs. In addition, temporal shift modules (TSMs) are used in the dynamic-temporal stream, which enables temporal modeling with no additional parameters by mixing ME motion information from two different temporal domains. Furthermore, we introduce self-knowledge distillation (SKD) into the MER task by introducing auxiliary classifiers and using the deepest section of the network for supervision, encouraging all blocks to fully explore the features of the training set. Finally, extensive experiments are conducted on four ME datasets: CASME II, SAMM, MMEW, and CAS(ME)3. The experimental results demonstrate that our SKD-TSTSAN outperforms other existing methods and achieves new state-of-the-art performance. Our code will be available at https://github.com/GuanghaoZhu663/SKD-TSTSAN.