 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial-R1: Aligning Reasoning and Recognition for Facial Emotion Analysis
Nov 13, 2025
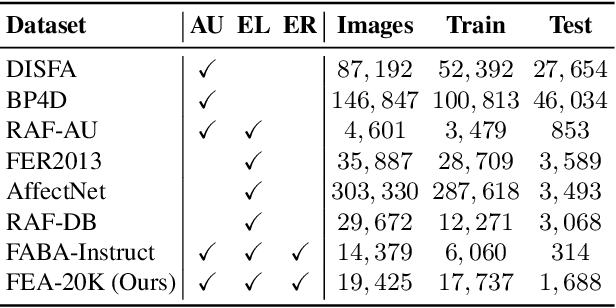
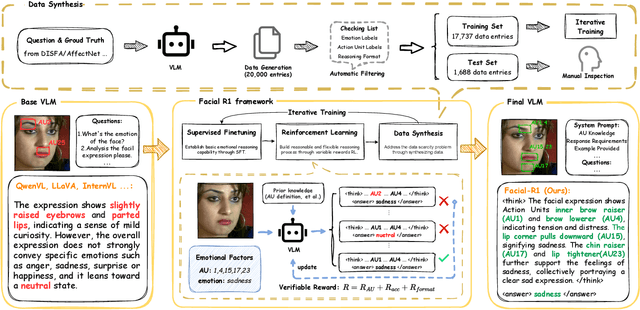
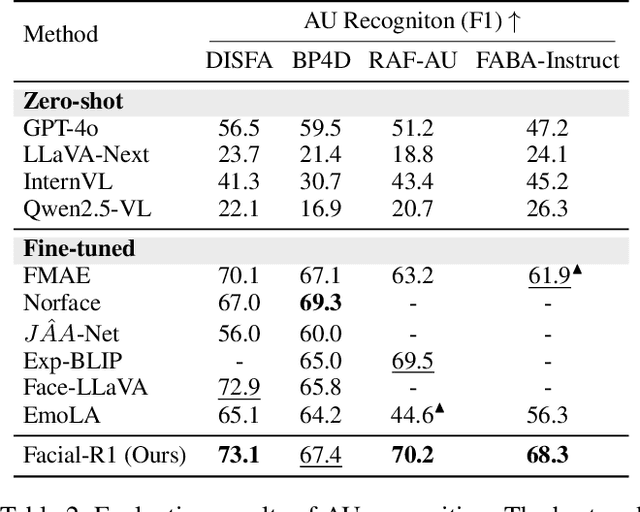
Facial Emotion Analysis (FEA) extends traditional facial emotion recognition by incorporating explainable, fine-grained reasoning. The task integrates three subtasks: emotion recognition, facial Action Unit (AU) recognition, and AU-based emotion reasoning to model affective states jointly. While recent approaches leverage Vision-Language Models (VLMs) and achieve promising results, they face two critical limitations: (1) hallucinated reasoning, where VLMs generate plausible but inaccurate explanations due to insufficient emotion-specific knowledge; and (2) misalignment between emotion reasoning and recognition, caused by fragmented connections between observed facial features and final labels. We propose Facial-R1, a three-stage alignment framework that effectively addresses both challenges with minimal supervision. First, we employ instruction fine-tuning to establish basic emotional reasoning capability. Second, we introduce reinforcement training guided by emotion and AU labels as reward signals, which explicitly aligns the generated reasoning process with the predicted emotion. Third, we design a data synthesis pipeline that iteratively leverages the prior stages to expand the training dataset, enabling scalable self-improvement of the model. Built upon this framework, we introduce FEA-20K, a benchmark dataset comprising 17,737 training and 1,688 test samples with fine-grained emotion analysis annotations. Extensive experiments across eight standard benchmarks demonstrate that Facial-R1 achieves state-of-the-art performance in FEA, with strong generalization and robust interpretability.
SKD-TSTSAN: Three-Stream Temporal-Shift Attention Network Based on Self-Knowledge Distillation for Micro-Expression Recognition
Jun 25, 2024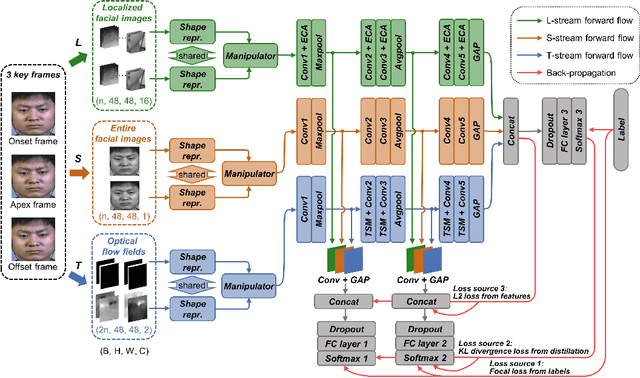
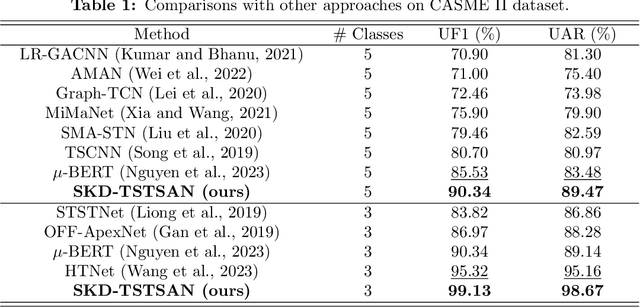
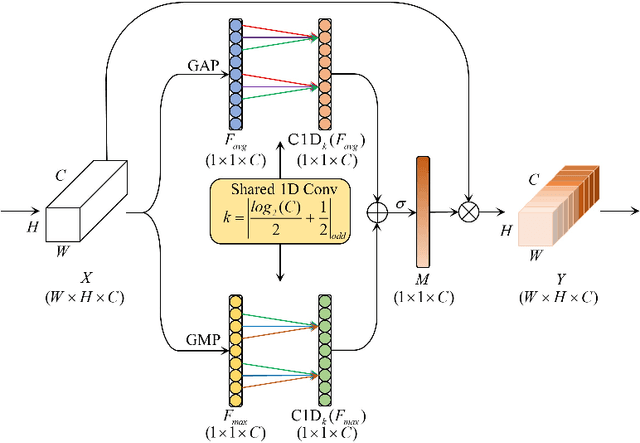
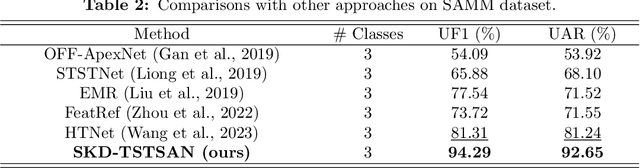
Micro-expressions (MEs) are subtle facial movements that occur spontaneously when people try to conceal the real emotions. Micro-expression recognition (MER) is crucial in many fields, including criminal analysis and psychotherapy. However, MER is challenging since MEs have low intensity and ME datasets are small in size. To this end, a three-stream temporal-shift attention network based on self-knowledge distillation (SKD-TSTSAN) is proposed in this paper. Firstly, to address the low intensity of ME muscle movements, we utilize learning-based motion magnification modules to enhance the intensity of ME muscle movements. Secondly, we employ efficient channel attention (ECA) modules in the local-spatial stream to make the network focus on facial regions that are highly relevant to MEs. In addition, temporal shift modules (TSMs) are used in the dynamic-temporal stream, which enables temporal modeling with no additional parameters by mixing ME motion information from two different temporal domains. Furthermore, we introduce self-knowledge distillation (SKD) into the MER task by introducing auxiliary classifiers and using the deepest section of the network for supervision, encouraging all blocks to fully explore the features of the training set. Finally, extensive experiments are conducted on four ME datasets: CASME II, SAMM, MMEW, and CAS(ME)3. The experimental results demonstrate that our SKD-TSTSAN outperforms other existing methods and achieves new state-of-the-art performance. Our code will be available at https://github.com/GuanghaoZhu663/SKD-TSTSAN.
3D-FlowNet: Event-based optical flow estimation with 3D representation
Jan 28, 2022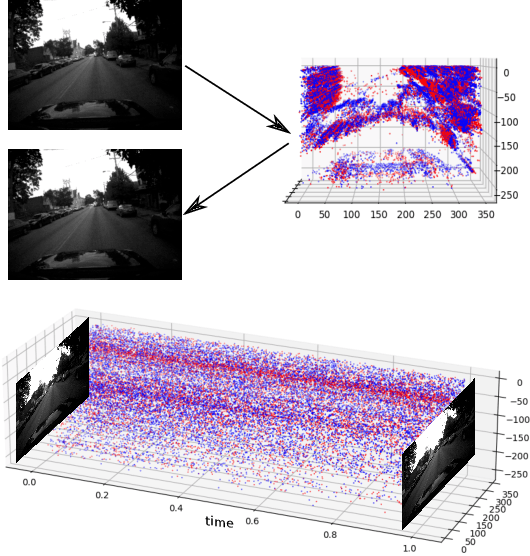
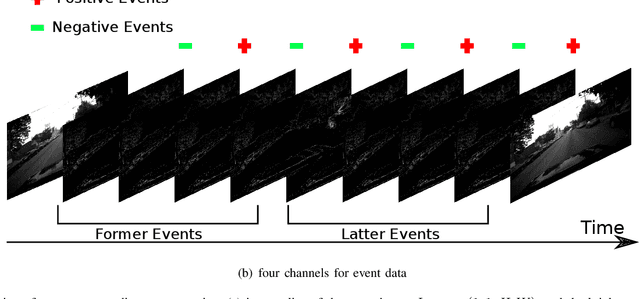
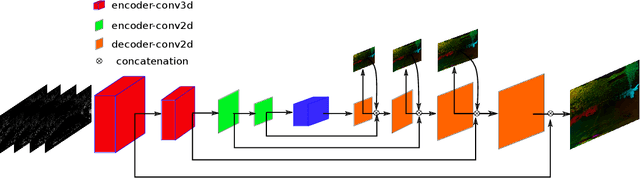

Event-based cameras can overpass frame-based cameras limitations for important tasks such as high-speed motion detection during self-driving cars navigation in low illumination conditions. The event cameras' high temporal resolution and high dynamic range, allow them to work in fast motion and extreme light scenarios. However, conventional computer vision methods, such as Deep Neural Networks, are not well adapted to work with event data as they are asynchronous and discrete. Moreover, the traditional 2D-encoding representation methods for event data, sacrifice the time resolution. In this paper, we first improve the 2D-encoding representation by expanding it into three dimensions to better preserve the temporal distribution of the events. We then propose 3D-FlowNet, a novel network architecture that can process the 3D input representation and output optical flow estimations according to the new encoding methods. A self-supervised training strategy is adopted to compensate the lack of labeled datasets for the event-based camera. Finally, the proposed network is trained and evaluated with the Multi-Vehicle Stereo Event Camera (MVSEC) dataset. The results show that our 3D-FlowNet outperforms state-of-the-art approaches with less training epoch (30 compared to 100 of Spike-FlowNet).
CenterFace: Joint Face Detection and Alignment Using Face as Point
Nov 09, 2019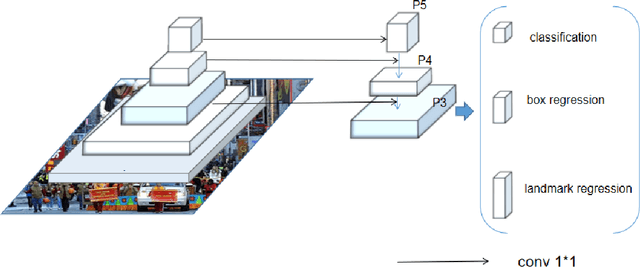
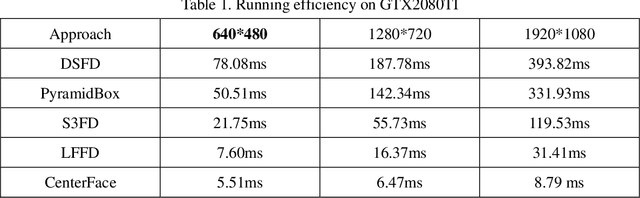
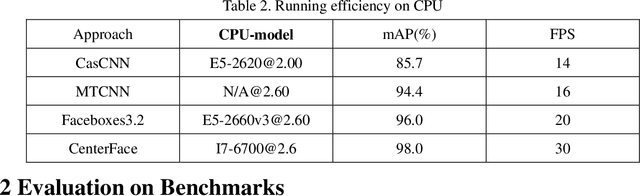
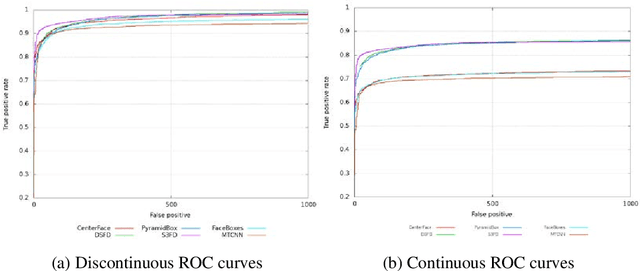
Face detection and alignment in unconstrained environment is always deployed on edge devices which have limited memory storage and low computing power. This paper proposes a one-stage method named CenterFace to simultaneously predict facial box and landmark location with real-time speed and high accuracy. The proposed method also belongs to the anchor free category. This is achieved by: (a) learning face existing possibility by the semantic maps, (b) learning bounding box, offsets and five landmarks for each position that potentially contains a face. Specifically, the method can run in real-time on a single CPU core and 200 FPS using NVIDIA 2080TI for VGA-resolution images, and can simultaneously achieve superior accuracy (WIDER FACE Val/Test-Easy: 0.935/0.932, Medium: 0.924/0.921, Hard: 0.875/0.873 and FDDB discontinuous: 0.980, continuous: 0.732). A demo of CenterFace can be available at https://github.com/Star-Clouds/CenterFace.