 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Skepticism: Evaluating LLMs Pedagogical Intent Reasoning with the Adaptive Pedagogical Vigilance Framework
Jul 02, 2026The capacity of Large Language Models (LLMs) to reason about pedagogical intent within instructional communication remains underexplored, particularly in educational domains such as translation pedagogy. To address this, we propose the \textbf{Adaptive Pedagogical Vigilance (APV)} framework, a novel computational formalism that reframes communicative vigilance as an adaptive mechanism for optimizing learning through intent inference. APV formalizes the problem via a Bayesian Pedagogical Intent Inference Engine (PIIE), which models how instructors select content to maximize pedagogical utility and how vigilant learners should inversely reason about latent instructional configurations -- encompassing genre, stance, and incentives. We evaluate APV through a three-tier hierarchy: distinguishing instructional genre, reasoning about structured pedagogical setups, and generalizing to authentic educational discourse. Experiments on leading LLMs (e.g., GPT-4o, Claude 3.5) show that APV substantially improves model vigilance. It achieves the strongest discrimination between pedagogical and exposure-based content, correlates highly with human judgments ($r=0.958$), and maintains robust performance on naturalistic data where baseline methods degrade. This work establishes a unified framework for assessing and enhancing LLMs' understanding of pedagogical motives, advancing the development of more reliable AI-assisted learning systems.
LazyMAR: Accelerating Masked Autoregressive Models via Feature Caching
Mar 16, 2025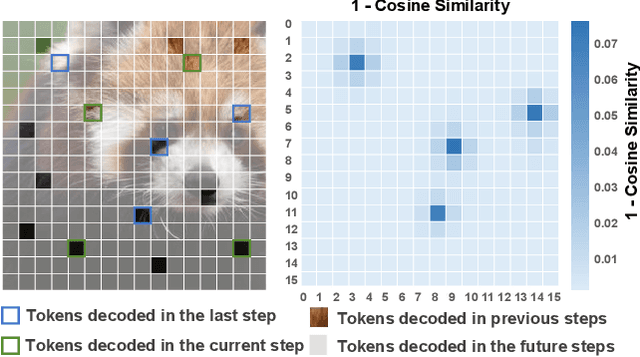
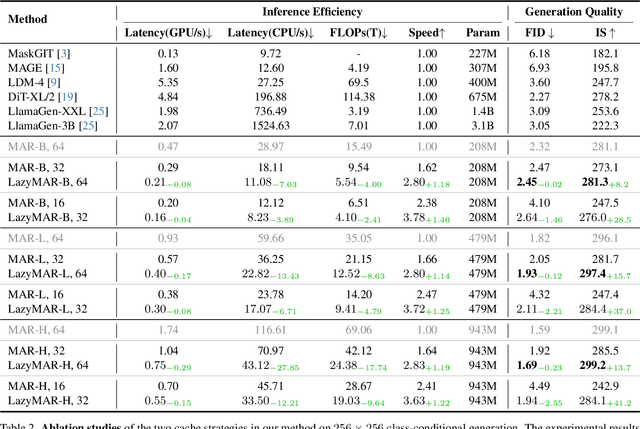
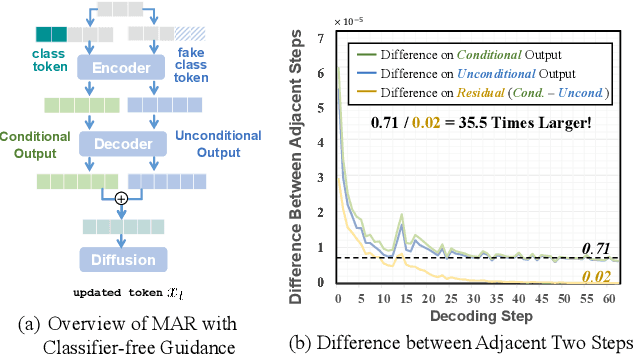

Masked Autoregressive (MAR) models have emerged as a promising approach in image generation, expected to surpass traditional autoregressive models in computational efficiency by leveraging the capability of parallel decoding. However, their dependence on bidirectional self-attention inherently conflicts with conventional KV caching mechanisms, creating unexpected computational bottlenecks that undermine their expected efficiency. To address this problem, this paper studies the caching mechanism for MAR by leveraging two types of redundancy: Token Redundancy indicates that a large portion of tokens have very similar representations in the adjacent decoding steps, which allows us to first cache them in previous steps and then reuse them in the later steps. Condition Redundancy indicates that the difference between conditional and unconditional output in classifier-free guidance exhibits very similar values in adjacent steps. Based on these two redundancies, we propose LazyMAR, which introduces two caching mechanisms to handle them one by one. LazyMAR is training-free and plug-and-play for all MAR models. Experimental results demonstrate that our method achieves 2.83 times acceleration with almost no drop in generation quality. Our codes will be released in https://github.com/feihongyan1/LazyMAR.
Token Pruning for Caching Better: 9 Times Acceleration on Stable Diffusion for Free
Dec 31, 2024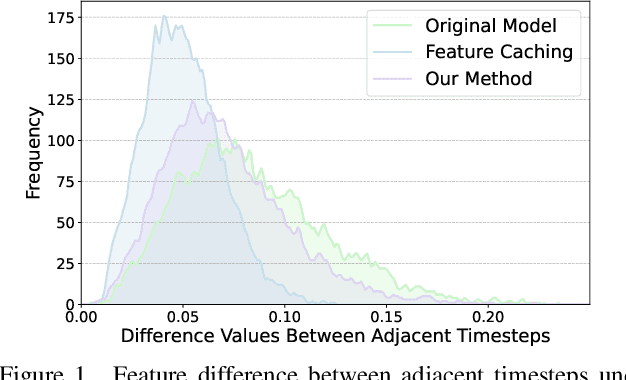
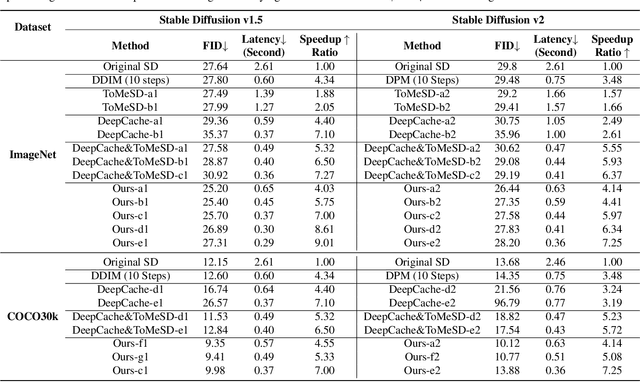

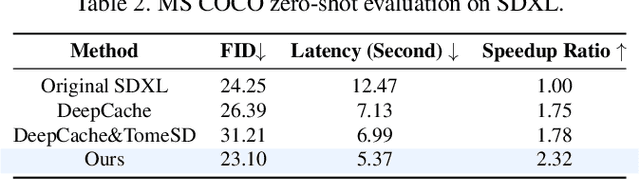
Stable Diffusion has achieved remarkable success in the field of text-to-image generation, with its powerful generative capabilities and diverse generation results making a lasting impact. However, its iterative denoising introduces high computational costs and slows generation speed, limiting broader adoption. The community has made numerous efforts to reduce this computational burden, with methods like feature caching attracting attention due to their effectiveness and simplicity. Nonetheless, simply reusing features computed at previous timesteps causes the features across adjacent timesteps to become similar, reducing the dynamics of features over time and ultimately compromising the quality of generated images. In this paper, we introduce a dynamics-aware token pruning (DaTo) approach that addresses the limitations of feature caching. DaTo selectively prunes tokens with lower dynamics, allowing only high-dynamic tokens to participate in self-attention layers, thereby extending feature dynamics across timesteps. DaTo combines feature caching with token pruning in a training-free manner, achieving both temporal and token-wise information reuse. Applied to Stable Diffusion on the ImageNet, our approach delivered a 9$\times$ speedup while reducing FID by 0.33, indicating enhanced image quality. On the COCO-30k, we observed a 7$\times$ acceleration coupled with a notable FID reduction of 2.17.
UNSCT-HRNet: Modeling Anatomical Uncertainty for Landmark Detection in Total Hip Arthroplasty
Nov 13, 2024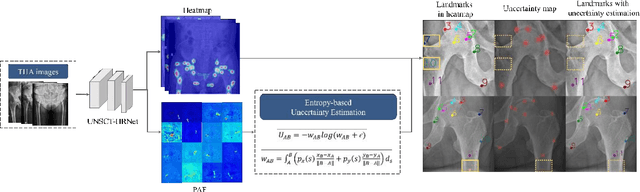

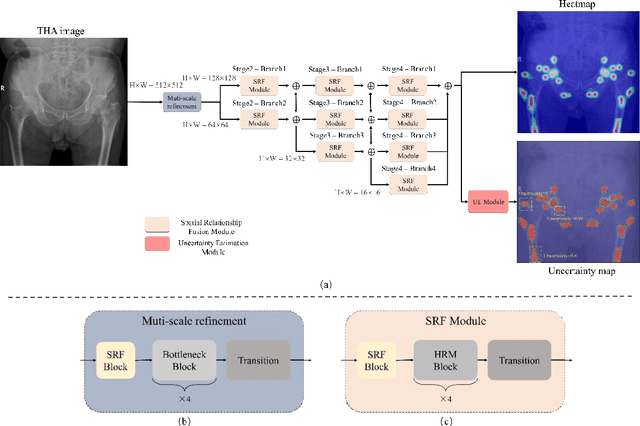

Total hip arthroplasty (THA) relies on accurate landmark detection from radiographic images, but unstructured data caused by irregular patient postures or occluded anatomical markers pose significant challenges for existing methods. To address this, we propose UNSCT-HRNet (Unstructured CT - High-Resolution Net), a deep learning-based framework that integrates a Spatial Relationship Fusion (SRF) module and an Uncertainty Estimation (UE) module. The SRF module, utilizing coordinate convolution and polarized attention, enhances the model's ability to capture complex spatial relationships. Meanwhile, the UE module which based on entropy ensures predictions are anatomically relevant. For unstructured data, the proposed method can predict landmarks without relying on the fixed number of points, which shows higher accuracy and better robustness comparing with the existing methods. Our UNSCT-HRNet demonstrates over a 60% improvement across multiple metrics in unstructured data. The experimental results also reveal that our approach maintains good performance on the structured dataset. Overall, the proposed UNSCT-HRNet has the potential to be used as a new reliable, automated solution for THA surgical planning and postoperative monitoring.
Quantifying and Mitigating Privacy Risks for Tabular Generative Models
Mar 12, 2024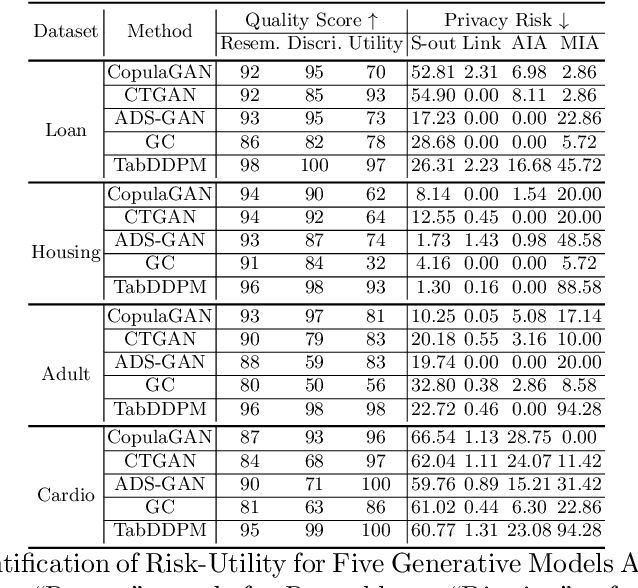
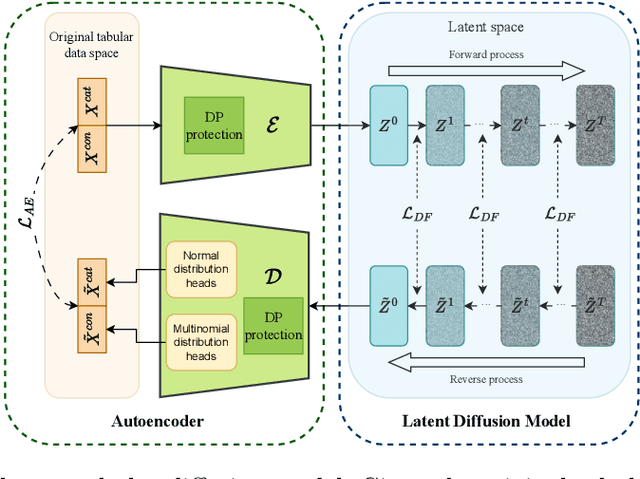
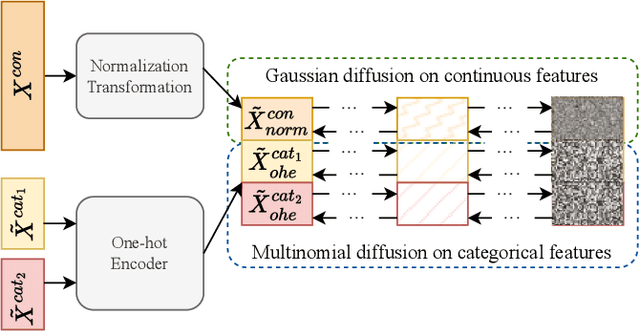
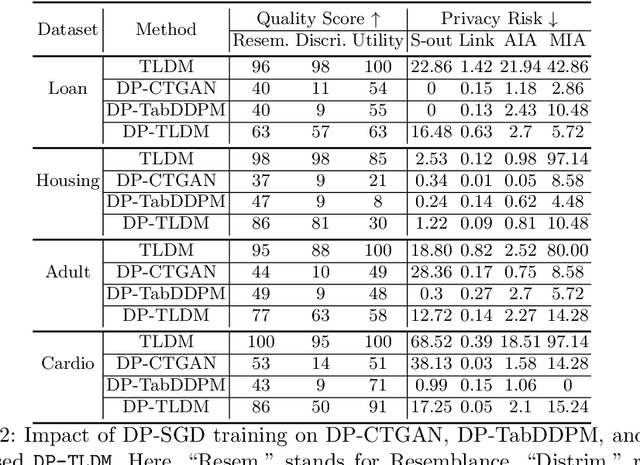
Synthetic data from generative models emerges as the privacy-preserving data-sharing solution. Such a synthetic data set shall resemble the original data without revealing identifiable private information. The backbone technology of tabular synthesizers is rooted in image generative models, ranging from Generative Adversarial Networks (GANs) to recent diffusion models. Recent prior work sheds light on the utility-privacy tradeoff on tabular data, revealing and quantifying privacy risks on synthetic data. We first conduct an exhaustive empirical analysis, highlighting the utility-privacy tradeoff of five state-of-the-art tabular synthesizers, against eight privacy attacks, with a special focus on membership inference attacks. Motivated by the observation of high data quality but also high privacy risk in tabular diffusion, we propose DP-TLDM, Differentially Private Tabular Latent Diffusion Model, which is composed of an autoencoder network to encode the tabular data and a latent diffusion model to synthesize the latent tables. Following the emerging f-DP framework, we apply DP-SGD to train the auto-encoder in combination with batch clipping and use the separation value as the privacy metric to better capture the privacy gain from DP algorithms. Our empirical evaluation demonstrates that DP-TLDM is capable of achieving a meaningful theoretical privacy guarantee while also significantly enhancing the utility of synthetic data. Specifically, compared to other DP-protected tabular generative models, DP-TLDM improves the synthetic quality by an average of 35% in data resemblance, 15% in the utility for downstream tasks, and 50% in data discriminability, all while preserving a comparable level of privacy risk.