 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow and Why: Taming Flow Matching for Unsupervised Anomaly Detection and Localization
Aug 07, 2025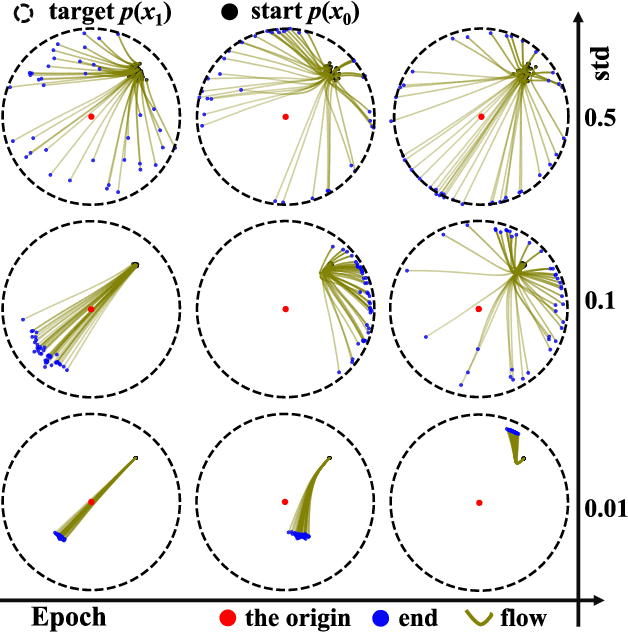
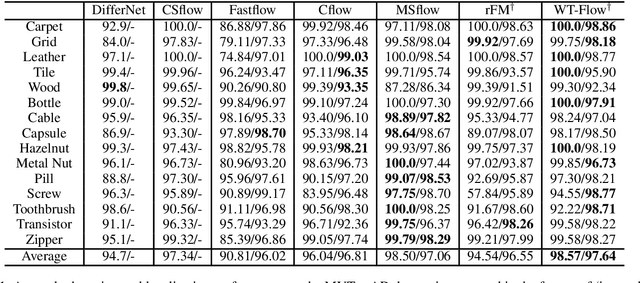
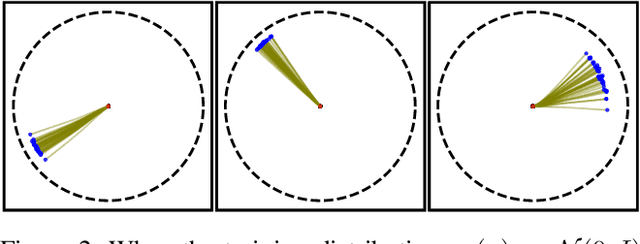
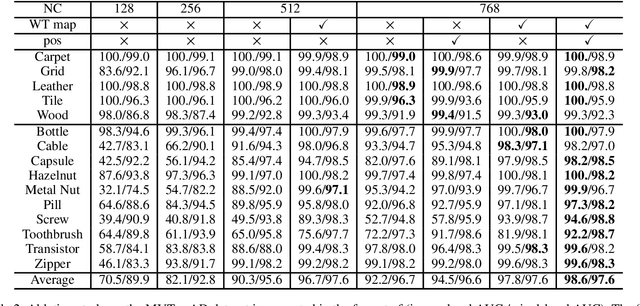
We propose a new paradigm for unsupervised anomaly detection and localization using Flow Matching (FM), which fundamentally addresses the model expressivity limitations of conventional flow-based methods. To this end, we formalize the concept of time-reversed Flow Matching (rFM) as a vector field regression along a predefined probability path to transform unknown data distributions into standard Gaussian. We bring two core observations that reshape our understanding of FM. First, we rigorously prove that FM with linear interpolation probability paths is inherently non-invertible. Second, our analysis reveals that employing reversed Gaussian probability paths in high-dimensional spaces can lead to trivial vector fields. This issue arises due to the manifold-related constraints. Building on the second observation, we propose Worst Transport (WT) displacement interpolation to reconstruct a non-probabilistic evolution path. The proposed WT-Flow enhances dynamical control over sample trajectories, constructing ''degenerate potential wells'' for anomaly-free samples while allowing anomalous samples to escape. This novel unsupervised paradigm offers a theoretically grounded separation mechanism for anomalous samples. Notably, FM provides a computationally tractable framework that scales to complex data. We present the first successful application of FM for the unsupervised anomaly detection task, achieving state-of-the-art performance at a single scale on the MVTec dataset. The reproducible code for training will be released upon camera-ready submission.
UNSCT-HRNet: Modeling Anatomical Uncertainty for Landmark Detection in Total Hip Arthroplasty
Nov 13, 2024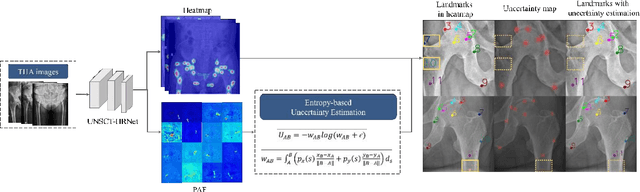

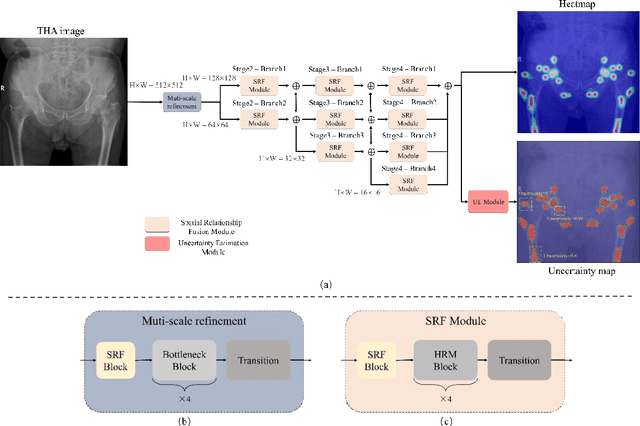

Total hip arthroplasty (THA) relies on accurate landmark detection from radiographic images, but unstructured data caused by irregular patient postures or occluded anatomical markers pose significant challenges for existing methods. To address this, we propose UNSCT-HRNet (Unstructured CT - High-Resolution Net), a deep learning-based framework that integrates a Spatial Relationship Fusion (SRF) module and an Uncertainty Estimation (UE) module. The SRF module, utilizing coordinate convolution and polarized attention, enhances the model's ability to capture complex spatial relationships. Meanwhile, the UE module which based on entropy ensures predictions are anatomically relevant. For unstructured data, the proposed method can predict landmarks without relying on the fixed number of points, which shows higher accuracy and better robustness comparing with the existing methods. Our UNSCT-HRNet demonstrates over a 60% improvement across multiple metrics in unstructured data. The experimental results also reveal that our approach maintains good performance on the structured dataset. Overall, the proposed UNSCT-HRNet has the potential to be used as a new reliable, automated solution for THA surgical planning and postoperative monitoring.
Understanding Pixel-level 2D Image Semantics with 3D Keypoint Knowledge Engine
Nov 21, 2021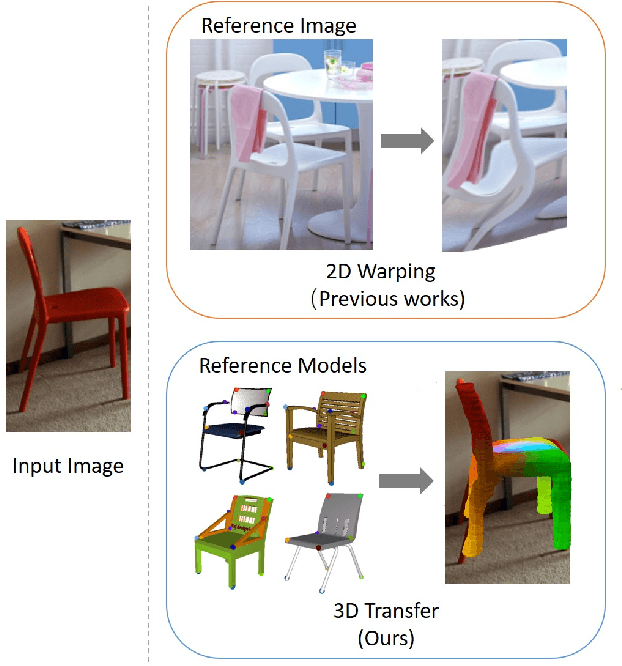

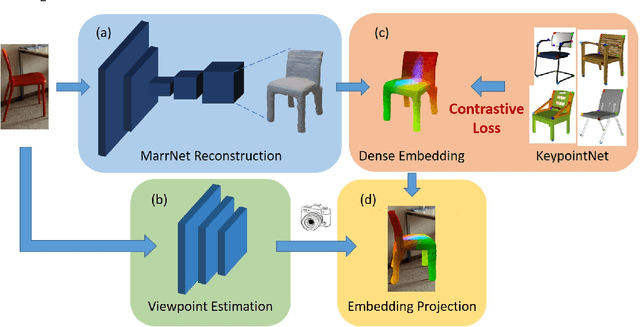

Pixel-level 2D object semantic understanding is an important topic in computer vision and could help machine deeply understand objects (e.g. functionality and affordance) in our daily life. However, most previous methods directly train on correspondences in 2D images, which is end-to-end but loses plenty of information in 3D spaces. In this paper, we propose a new method on predicting image corresponding semantics in 3D domain and then projecting them back onto 2D images to achieve pixel-level understanding. In order to obtain reliable 3D semantic labels that are absent in current image datasets, we build a large scale keypoint knowledge engine called KeypointNet, which contains 103,450 keypoints and 8,234 3D models from 16 object categories. Our method leverages the advantages in 3D vision and can explicitly reason about objects self-occlusion and visibility. We show that our method gives comparative and even superior results on standard semantic benchmarks.
Spending Money Wisely: Online Electronic Coupon Allocation based on Real-Time User Intent Detection
Aug 23, 2020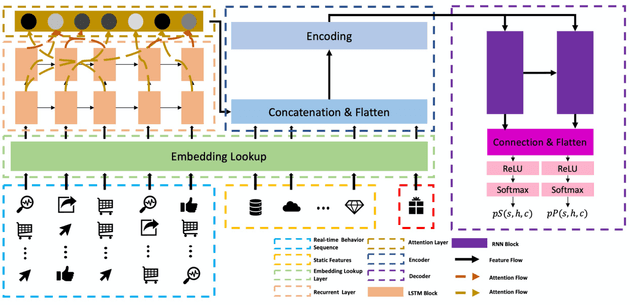
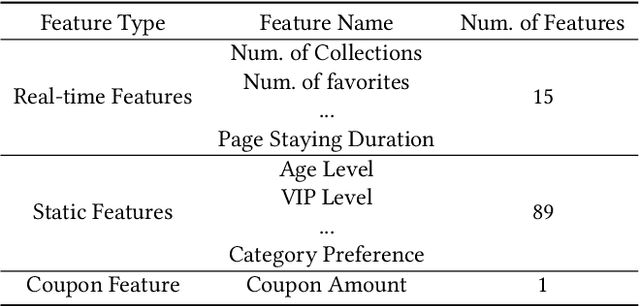
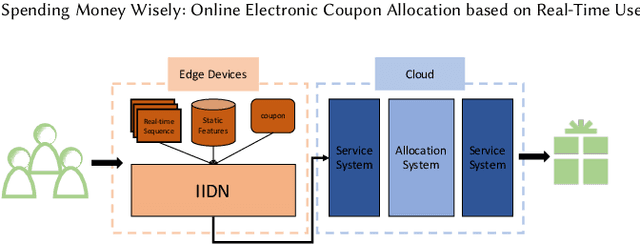
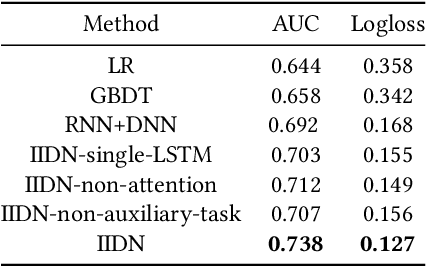
Online electronic coupon (e-coupon) is becoming a primary tool for e-commerce platforms to attract users to place orders. E-coupons are the digital equivalent of traditional paper coupons which provide customers with discounts or gifts. One of the fundamental problems related is how to deliver e-coupons with minimal cost while users' willingness to place an order is maximized. We call this problem the coupon allocation problem. This is a non-trivial problem since the number of regular users on a mature e-platform often reaches hundreds of millions and the types of e-coupons to be allocated are often multiple. The policy space is extremely large and the online allocation has to satisfy a budget constraint. Besides, one can never observe the responses of one user under different policies which increases the uncertainty of the policy making process. Previous work fails to deal with these challenges. In this paper, we decompose the coupon allocation task into two subtasks: the user intent detection task and the allocation task. Accordingly, we propose a two-stage solution: at the first stage (detection stage), we put forward a novel Instantaneous Intent Detection Network (IIDN) which takes the user-coupon features as input and predicts user real-time intents; at the second stage (allocation stage), we model the allocation problem as a Multiple-Choice Knapsack Problem (MCKP) and provide a computational efficient allocation method using the intents predicted at the detection stage. We conduct extensive online and offline experiments and the results show the superiority of our proposed framework, which has brought great profits to the platform and continues to function online.
KeypointNet: A Large-scale 3D Keypoint Dataset Aggregated from Numerous Human Annotations
Mar 21, 2020

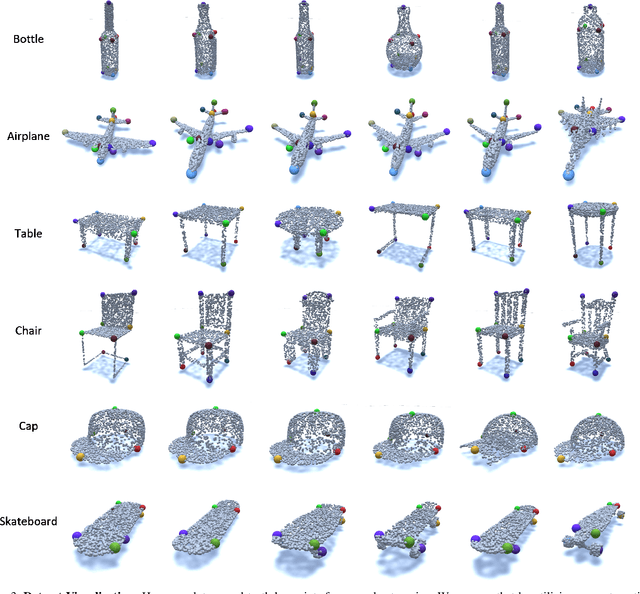
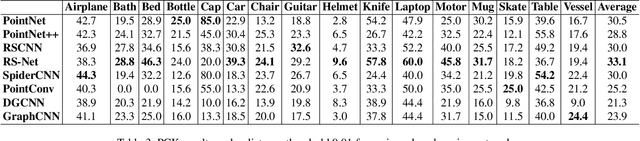
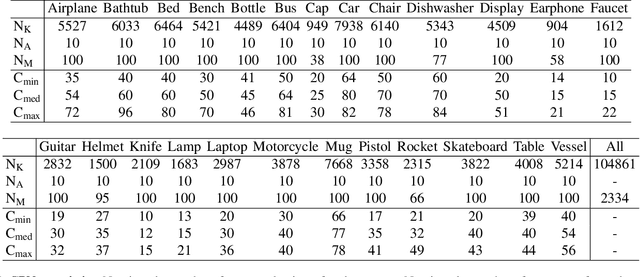
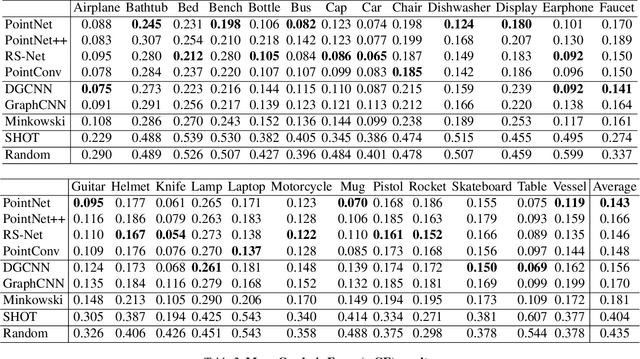
Detecting 3D objects keypoints is of great interest to the areas of both graphics and computer vision. There have been several 2D and 3D keypoint datasets aiming to address this problem in a data-driven way. These datasets, however, either lack scalability or bring ambiguity to the definition of keypoints. Therefore, we present KeypointNet: the first large-scale and diverse 3D keypoint dataset that contains 83,231 keypoints and 8,329 3D models from 16 object categories, by leveraging numerous human annotations. To handle the inconsistency between annotations from different people, we propose a novel method to aggregate these keypoints automatically, through minimization of a fidelity loss. Finally, ten state-of-the-art methods are benchmarked on our proposed dataset.
Fine-grained Object Semantic Understanding from Correspondences
Dec 29, 2019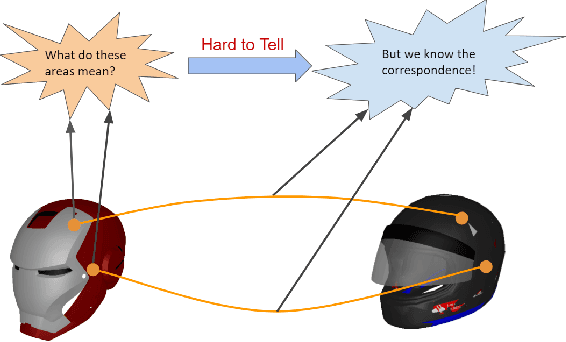
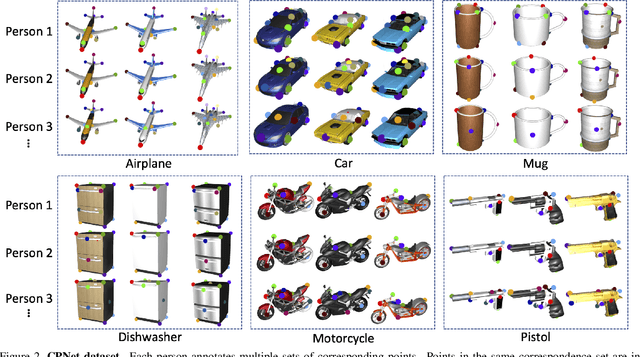
Fine-grained semantic understanding of 3D objects is crucial in many applications such as object manipulation. However, it is hard to give a universal definition of point-level semantics that everyone would agree on. We observe that people are pretty sure about semantic correspondences between two areas from different objects, but less certain about what each area means in semantics. Therefore, we argue that by providing human labeled correspondences between different objects from the same category, one can recover rich semantic information of an object. In this paper, we propose a method that outputs dense semantic embeddings based on a novel geodesic consistency loss. Accordingly, a new dataset named CorresPondenceNet and its corresponding benchmark are designed. Several state-of-the-art networks are evaluated based on our proposed method. We show that our method could boost the fine-grained understanding of heterogeneous objects and the inference of dense semantic information is possible.
Combinational Q-Learning for Dou Di Zhu
Jan 24, 2019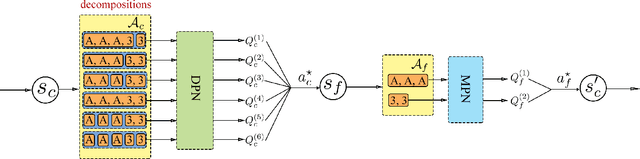
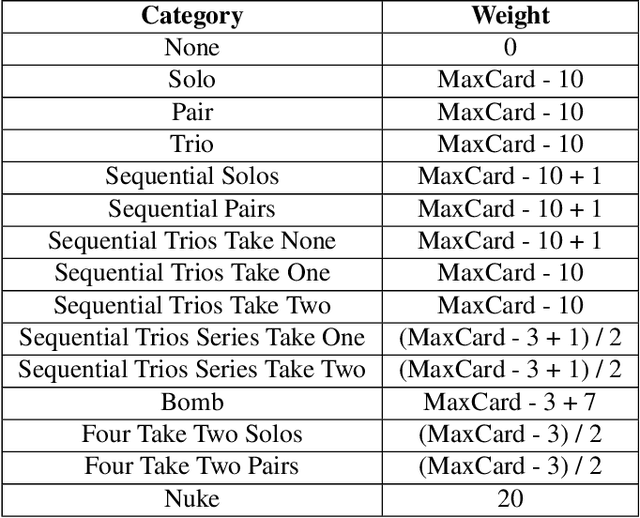
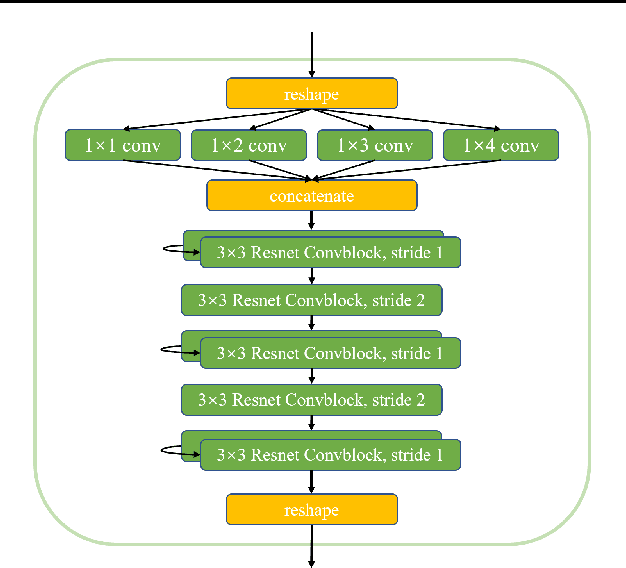
Deep reinforcement learning (DRL) has gained a lot of attention in recent years, and has been proven to be able to play Atari games and Go at or above human levels. However, those games are assumed to have a small fixed number of actions and could be trained with a simple CNN network. In this paper, we study a special class of Asian popular card games called Dou Di Zhu, in which two adversarial groups of agents must consider numerous card combinations at each time step, leading to huge number of actions. We propose a novel method to handle combinatorial actions, which we call combinational Q-learning (CQL). We employ a two-stage network to reduce action space and also leverage order-invariant max-pooling operations to extract relationships between primitive actions. Results show that our method prevails over state-of-the art methods like naive Q-learning and A3C. We develop an easy-to-use card game environments and train all agents adversarially from sractch, with only knowledge of game rules and verify that our agents are comparative to humans. Our code to reproduce all reported results will be available online.